IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处!
IK分词器如果配置成
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
本人测试切分词可以,但是同义词,扩展词库用不了,
网上查各种资料说IK分词器有个BUG,要自己把jar文件改一下,于是找到IK的源码,里面只有IKAnalyzer的源码,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer; /**
* IK分词器,Lucene Analyzer接口实现
* 兼容Lucene 4.0版本
*/
public final class IKAnalyzer extends Analyzer{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} /**
* IK分词器Lucene Analyzer接口实现类
*
* 默认细粒度切分算法
*/
public IKAnalyzer(){
this(false);
} /**
* IK分词器Lucene Analyzer接口实现类
*
* @param useSmart 当为true时,分词器进行智能切分
*/
public IKAnalyzer(boolean useSmart){
super();
this.useSmart = useSmart;
} /**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
} }
自己加了一个IKAnalyzerSolrFactory,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader;
import java.util.Map; import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory; public class IKAnalyzerSolrFactory extends TokenizerFactory{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} public IKAnalyzerSolrFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
} @Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
} }
这样一来就能在配置文件中配置成IKAnalyzerSolrFactory 的列子
下面是具体的配置描述:
1。修改IK的jar文件,加入IKAnalyzerSolrFactory (如果不会改的自行下载 http://pan.baidu.com/s/1gfLOIL9)
2.修改solrconfig.xml文件,加入
<lib dir="/contrib/analysis-extras/lib" regex=".*\.jar" />
3.修改schema.xml文件,加入
<!--IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
4.在solr的webINFO 下的classes(没有新建)加入如下图,IK压缩文件中的部分文件,如图所示:
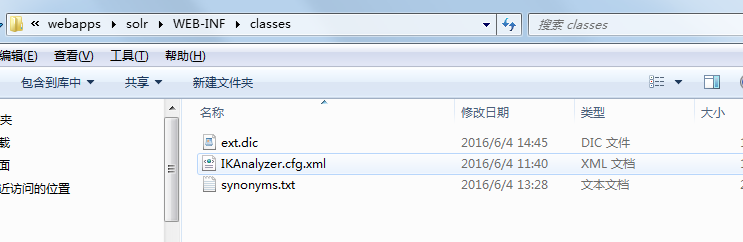
5.在ext.dic配置自定义词库,不需要切分词的词语配置在此,同义词写在synonyms.txt中即可。格式为: 通知,通告
注意每次改变词库或者同义词需要重启服务。
IK分词器 整合solr4.7 含同义词、切分词、停止词的更多相关文章
- Ik分词器没有使用---------elasticsearch-analysis-ik 5.6.3分词问题
此文章在作者认真阅读源码后发现,这并不是问题所在. 此篇文章是对IK配置的错误理解.新版本的IK配置的扩展字典本来就该使用者自己去手动配置! 1.问题 现在项目中用的是ES5.6.3的版本,在解决Fi ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- 【杂记】docker搭建ELK 集群6.4.0版本 + elasticsearch-head IK分词器与拼音分词器整合
大佬博客地址:https://blog.csdn.net/supermao1013/article/category/8269552 docker elasticsearch 集群启动命令 docke ...
- solr4.x配置IK2012FF智能分词+同义词配置
本文配置环境:solr4.6+ IK2012ff +tomcat7 在Solr4.0发布以后,官方取消了BaseTokenizerFactory接口,而直接使用Lucene Analyzer标准接口T ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- solr4.5配置中文分词器mmseg4j
solr4.x虽然提供了分词器,但不太适合对中文的分词,给大家推荐一个中文分词器mmseg4j mmseg4j的下载地址:https://code.google.com/p/mmseg4j/ 通过以下 ...
随机推荐
- maven archetype生成自定义项目原型(模板)
maven archetype可以将一个项目做成项目原型,之后只需要以此原型来创建项目,那么初始创建的项目便具有原型项目中的一切配置和代码.通俗讲就是一个项目模板. eclipse中那些快速生成mav ...
- centos 7 install python spynner
yum install python-devel yum install libXtst-devel pip install autopy pip install spynner import spy ...
- MultiThread
Stephen Toub From MicroSoft Crop. Stephen Cleary It's All About the SynchronizationContext How would ...
- 帆软报表FineReport中数据连接之Tomcat配置JNDI连接
1. 问题描述 在帆软报表FineReport中,通过JNDI方式定义数据连接,首先在Tomcat服务器配置好JNDI,然后在设计器中直接调用JNDI的名字,即可成功使用JNDI连接,连接步骤如下: ...
- Hibernate入门案例及增删改查
一.Hibernate入门案例剖析: ①创建实体类Student 并重写toString方法 public class Student { private Integer sid; private I ...
- python高级之生成器&迭代器
python高级之生成器&迭代器 本机内容 概念梳理 容器 可迭代对象 迭代器 for循环内部实现 生成器 1.概念梳理 容器(container):多个元素组织在一起的数据结构 可迭代对象( ...
- thinkphp怎么实现图片验证码
1.控制器 function verify() { ob_clean();//丢弃输出缓冲区中的内容 $config = array( 'fontSize' => 20, // 字体大小 'le ...
- js 字符串转换数字
方法主要有三种转换函数.强制类型转换.利用js变量弱类型转换. 1. 转换函数: js提供了parseInt()和parseFloat()两个转换函数.前者把值转换成整数,后者把值转换成浮点数.只有对 ...
- .net Core学习笔记:Windows环境搭建
1.安装 VS2015 Update3.如果已经安装了VS2015,但不是Update3版本,请在VS的工具 --> 扩展与更新 中执行update3的升级(大约需要2小时). 2..net C ...
- jquery-leonaScroll-1.2-自定义滚动条插件
leonaScroll-1.2.js 下载链接地址:http://share.weiyun.com/bb531dd6b1916c0023c176897182dc15 (密码:iZck)[内含压缩版] ...