MySQL Group Replication (MGR) 主节点故障自动切换和选举过程
MySQL Group Replication (MGR) 在主节点(单主模式下)故障时,其自动故障切换(Failover) 的核心在于其分布式故障检测机制和基于最新数据的共识选举协议。整个过程高度自动化,旨在最小化人工干预和停机时间。
以下是主节点故障自动切换的实现细节和选举过程:
一、触发条件:故障检测
持续心跳监控 (Failure Detector):
- 组内每个成员会定期(默认每秒)通过专用的组通信网络通道向其他成员发送心跳消息(包含自身状态和最新事务信息)。
- 每个成员都会监听来自其他成员的心跳。
超时判定故障:
- 如果某个成员(比如当前的Primary,称为
Node_A)在预设的超时时间(如 5秒,由参数group_replication_member_expel_timeout控制)内未收到来自某个特定成员(比如Node_B)的任何消息(包括心跳和应用进度等有效消息)。
- 如果某个成员(比如当前的Primary,称为
嫌疑阶段(Suspicion Phase - 分布式检测):
- 超时后,检测到问题的成员(
Node_B)并不会立即宣布Node_A失效。 Node_B会向整个组广播一个怀疑消息,指出它认为Node_A可能失效了。(这是一种优化的“流言传播”或Gossip-like机制)
- 超时后,检测到问题的成员(
确认故障 (Expulsion):
- 组内其他成员收到
Node_B的怀疑消息后,会检查自己与Node_A的最后通信时间。 - 如果大多数在线成员(构成法定数量Quorum)都确认在
group_replication_member_expel_timeout时间内未收到Node_A的有效消息,那么这些成员将达成共识。 - 达成共识后,组会自动驱逐(Expel)
Node_A。Node_A的状态被标记为UNREACHABLE然后OFFLINE(或ERROR),并从组视图(group_replication_group_members)中移除。
- 组内其他成员收到
关键点:故障检测是分布式的,避免单点判断错误;驱逐需要多数派(Quorum)成员确认。
二、新主节点选举(Leader Election)
一旦确认旧主节点(Node_A)被驱逐,并且剩余的在线成员数量仍然超过半数(拥有 Quorum),集群会自动触发新主节点(Primary)的选举过程。
核心选举算法:基于“最高事务序列号(seq_no) + 唯一标识(server_uuid)”
MySQL MGR 的选举过程由底层 XCom 引擎驱动,遵循一个严格的、基于分布式共识的顺序规则来选择新主:
收集候选节点状态: 剩余的在线节点(构成 Quorum 的成员)会交换和比较彼此的状态信息,最关键的两个值是:
-
last_applied_seq_no(或类似的最高事务序列号): 每个节点上已应用的最高事务的序列号(通常直接取自 GTID Executed Set 中的内部序号,或事务计数器)。这个值代表了节点上数据的相对“新旧”程度。数值越大,数据越新。 -
server_uuid: 每个 MySQL 服务器实例的唯一标识符(全局唯一字符串)。
-
比较规则:
- 第一优先级:
last_applied_seq_no(值更高者优先)- 目标:选择具有最新数据(拥有最多已提交事务)的节点作为新主。这最大限度地避免了数据丢失(因为新主理论上包含了旧主最后提交的所有事务)。
- 第二优先级:
server_uuid(字典序更小者优先)- 在出现多个节点拥有 完全相同的 最高的
last_applied_seq_no值的情况时(通常只发生在完美同步或启动时),选举算法会回退到比较server_uuid,选择字典序更小的(即server_uuid字符串排序更靠前)的节点作为新主。这是一种确定性的最终解决机制。
- 在出现多个节点拥有 完全相同的 最高的
- 第一优先级:
达成共识:
- XCom 引擎负责协调这个比较和决策过程。
- 剩余的每个在线节点独立应用上述比较规则,最终在所有节点上达成完全一致的选举结果。这个过程基于共识协议(类似 Paxos),确保所有在线节点都选出同一个新主节点。
角色切换:
- 被选中的节点(如
Node_C)自动将其角色从SECONDARY切换为PRIMARY。 - 其他剩余节点(如
Node_B,Node_D)保持为SECONDARY(只读)角色,并准备接受来自新主Node_C的复制数据。
- 被选中的节点(如
核心原则:选数据最新的节点当新主!
last_applied_seq_no是选择的核心依据,server_uuid用于处理平局。
三、集群视图更新与服务恢复
更新元数据:
- 组内形成新的成员视图(删除了故障节点
Node_A,并包含了新主Node_C)。 - 新的视图(
group_replication_group_members)信息通过共识协议自动同步给所有剩余节点。
- 组内形成新的成员视图(删除了故障节点
MySQL Router 重定向:
- MySQL Router 实例在后台定期轮询集群元数据(
mysql_innodb_cluster_metadataschema 或 performance_schemagroup_replication_group_members)。 - 当 Router 检测到集群视图更新(
ROLE列显示新的PRIMARY是Node_C)时,它会立即更新内部路由表。 - 对于新连接: 所有新到达的读写请求自动路由到新主
Node_C。 - 对于现有连接: Router 会尝试关闭或终止指向旧主
Node_A的会话(通常在旧连接下次发生读写操作时返回错误或自动重连到 Router,由 Router 重定向到Node_C)。
- MySQL Router 实例在后台定期轮询集群元数据(
应用恢复(Applier 继续):
- SECONDARY 节点上的 Applier 线程继续从新的 PRIMARY (
Node_C) 接收并应用 binlog events,追赶数据。
- SECONDARY 节点上的 Applier 线程继续从新的 PRIMARY (
四、故障切换流程图(简版)
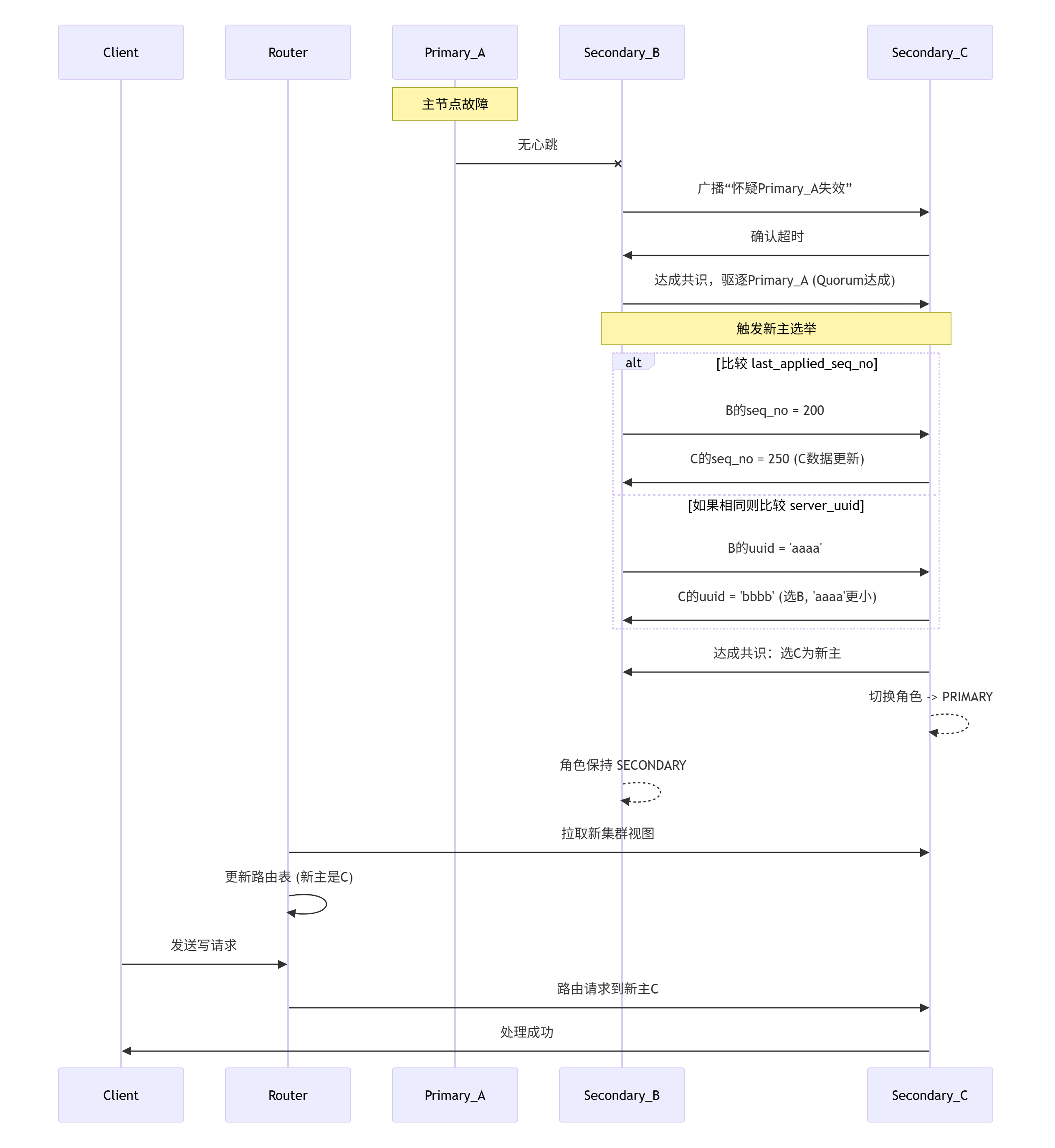
总结关键点
前提:剩余节点构成 Quorum( > N/2 )。
故障检测:基于心跳超时 + 分布式投票驱逐。
选举核心:
last_applied_seq_no(选数据最新者)。平局处理:
server_uuid(小者优先)。自动化:整个过程(检测 -> 驱逐 -> 选举 -> 切换 -> 视图更新)由 MGR 自动完成。
切换时间:通常在旧主失效被确认(
group_replication_member_expel_timeout时间已过)后,选举本身非常快(毫秒级),加上通知Router和应用重建连接,客户端感知的中断时间通常在 20-60 秒**。透明性:应用通过 MySQL Router 连接,Router 会自动重定向流量到新主。
因此,MGR 通过可靠的分布式故障检测机制和基于最新数据优先的共识选举协议,实现了高可用的自动故障切换(Failover)。
MySQL Group Replication (MGR) 主节点故障自动切换和选举过程的更多相关文章
- Mysql Group Replication 简介及单主模式组复制配置【转】
一 Mysql Group Replication简介 Mysql Group Replication(MGR)是一个全新的高可用和高扩张的MySQL集群服务. 高一致性,基于原生复制及p ...
- 使用ProxySQL实现MySQL Group Replication的故障转移、读写分离(一)
导读: 在之前,我们搭建了MySQL组复制集群环境,MySQL组复制集群环境解决了MySQL集群内部的自动故障转移,但是,组复制并没有解决外部业务的故障转移.举个例子,在A.B.C 3台机器上搭建了组 ...
- 使用ProxySQL实现MySQL Group Replication的故障转移、读写分离(二)
在上一篇文章<使用ProxySQL实现MySQL Group Replication的故障转移.读写分离(一) > 中,已经完成了MGR+ProxySQL集群的搭建,也测试了ProxySQ ...
- mysql group replication 主节点宕机恢复
一.mysql group replication 生来就要面对两个问题: 一.主节点宕机如何恢复. 二.多数节点离线的情况下.余下节点如何继续承载业务. 在这里我们只讨论第一个问题.也就是说当主结点 ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
- MySQL Group Replication 介绍
2016-12-12,一个重要的日子,mysql5.7.17 GA版发布,正式推出Group Replication(组复制) 插件,通过这个插件增强了MySQL原有的高可用方案(原有的Replica ...
- mysql group replication观点及实践
一:个人看法 Mysql Group Replication 随着5.7发布3年了.作为技术爱好者.mgr 是继 oracle database rac 之后. 又一个“真正” 的群集,怎么做到“ ...
- MySQL Group Replication配置
MySQL Group Replication简述 MySQL 组复制实现了基于复制协议的多主更新(单主模式). 复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事 ...
- Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication
Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication Overview Galera Cluster 由 Coders ...
- MySQL group replication介绍
“MySQL group replication” group replication是MySQL官方开发的一个开源插件,是实现MySQL高可用集群的一个工具.第一个GA版本正式发布于MySQL5.7 ...
随机推荐
- Httprunner 文件上传场景
使用Httprunner在做接口自动化的时候,经常会遇到需要上传文件的场景,下面讲一下关于Httpruner文件上传的用例编写. 1. 建项目 首先我们使用httprunner的脚手架快速搭建一个工程 ...
- HarmonyNEXT手动申请权限以及使用系统控件获取地址坐标的案例(区别)
一.手动申请位置权限 1.1.申请位置权限 申请ohos.permission.LOCATION.ohos.permission.APPROXIMATELY_LOCATION权限. "req ...
- 以RRT为例分析创新点的产生
1.找到基本算法的问题 1.1 喂文章和专利给GPT并分析提出的问题 1.2 整理问题 分析当前问题属于基本算法的那个阶段 2.1 固定参数问题:以双向RRT为例子:步长.采样方向.局部优化范围.交换 ...
- GC-QA-RAG 智能问答系统的文档切片
本章节介绍 GC-QA-RAG 智能问答系统的文档切片原理,即如何将原始文档的知识点切片后存入向量数据库. 1. 原始思路 将整个文档作为输入,交由大语言模型自动生成问答对(QA Pairs),以支持 ...
- ubuntu2004 ROS1安装
ubuntu初始环境配置ROS1 1.换源并更新数据库 ubuntu2004换源 # 备份原来的源并且另存 sudo cp -v /etc/apt/sources.list /etc/apt/sour ...
- Vue获取钉钉免登陆授权码(vue中的回调函数实践)
作者:故事我忘了¢个人微信公众号:程序猿的月光宝盒 目录 1.背景 2.技术栈 3.需求 4.实现步骤 4.1 配合webpack安装对应的npm包 4.2 抽取获得code的js方法 4.3 在需要 ...
- 关于cc3复现以及绕过思路
关于cc3复现以及绕过思路 (文章简略许多,可以的话,可以看看之前之前发布的文章) 绕过思路:动态加载字节码绕过Runtime,exec被过滤 在前面两个篇章中我们学习了cc1,cc6和动态加载字节码 ...
- 《刚刚问世》系列初窥篇-Java+Playwright自动化测试-16- iframe操作-监听事件和执行js脚本 (详细教程)
1.简介 前边主要讲解和分享了一下iframe的基础知识,以及一些常见的定位方法,最后进行了一下总结.今天主要来讲解和分享一下如何监听iframe上的事件和在iframe上如何执行JavaScript ...
- SM30里DEC数据显示0
需求:DEC数据在维护的时候显示0 1,设置数据元素对于的域带转换历程. 2,写转换历程函数(注意两个历程的输入和输出类型,这个需要修改) FUNCTION conversion_exit_zdays ...
- Unity Shader入门精要个人学习笔记
Unity Shader入门精要 渲染流水线 数学基础 1.点和矢量 类型 定义 表达 含义 性质 点(point) 点 (point) 是n 维空间(游戏中主要使用二维和三维空间)中的一个位置,它没 ...