Python代码将大量遥感数据的值缩放指定倍数的方法
本文介绍基于Python中的gdal模块,批量读取大量多波段遥感影像文件,分别对各波段数据加以数值处理,并将所得处理后数据保存为新的遥感影像文件的方法。
首先,看一下本文的具体需求。我们现有一个文件夹,其中含有大量.tif格式的遥感影像文件;其中,这些遥感影像文件均含有4个波段,每1个波段都表示其各自的反射率数值。而对于这些遥感影像文件,有的文件其各波段数值已经处于0至1的区间内(也就是反射率数据的正常数值区间),而有的文件其各波段数值则是还没有乘上缩放系数的(在本文中,缩放系数是0.0001)。
例如,如下图所示,即为文件夹中某一景遥感影像。可以看到其各波段数值都是大于1的,这是因为其数值都是还没有乘上缩放系数的,即是真实的反射率数值的10000倍。
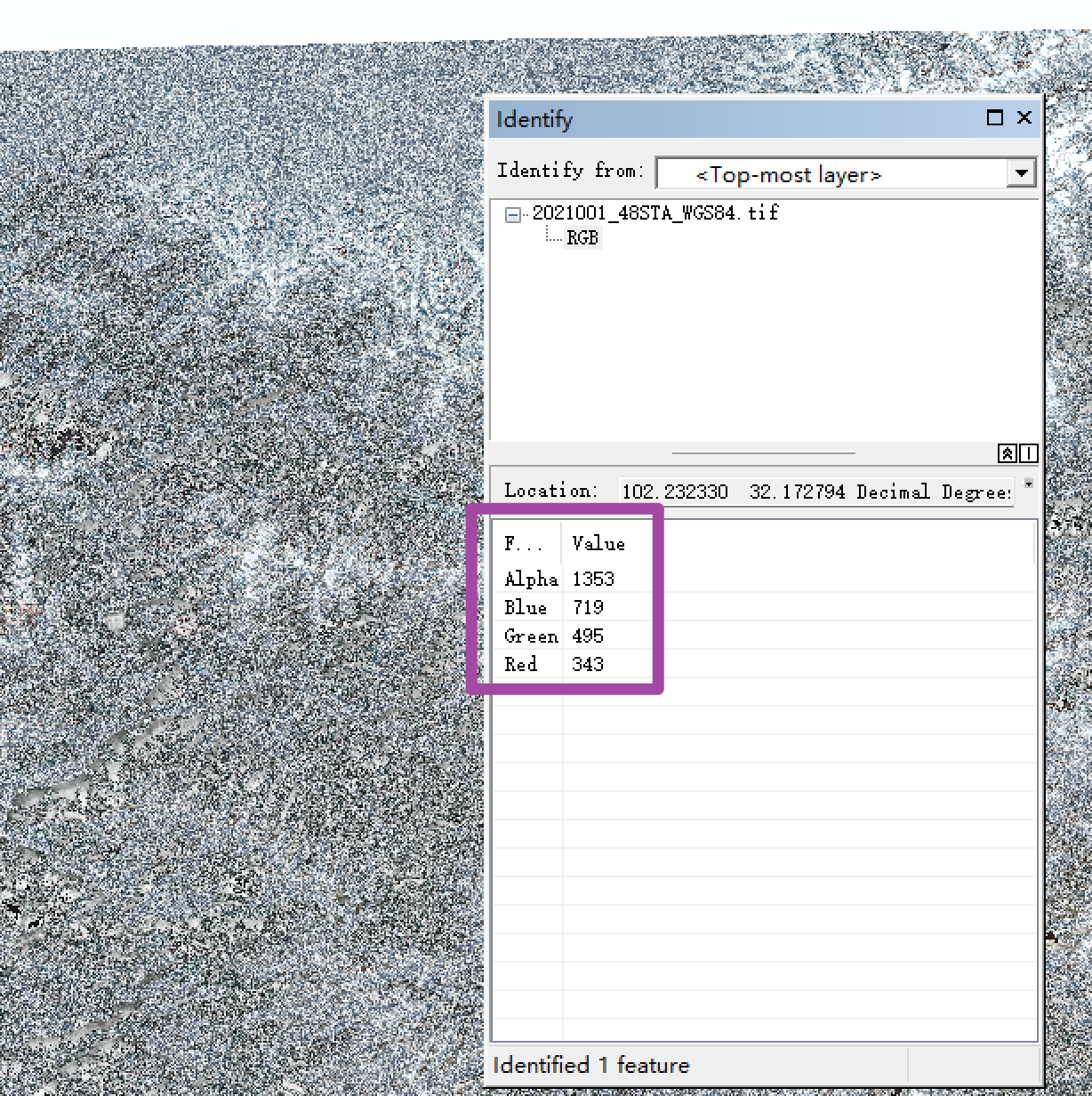
我们希望实现的是,对于这些遥感影像中,还没有乘上缩放系数0.0001的遥感影像,将其像元值乘上这个缩放系数;而对于已经缩放过(也就是像元数值已经落在0至1区间内)的遥感影像,则不加以任何处理。最后,将经过上述操作后的所有图像(无论是否执行缩放)均保存至指定的输出结果文件夹中。
本文所需代码如下。
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 18 12:37:22 2024
@author: fkxxgis
"""
import os
from osgeo import gdal
original_folder = r"E:\04_Reconstruction\99_MODIS\new_data\GF_Original"
output_folder = r"E:\04_Reconstruction\99_MODIS\new_data\GF_Rec"
for filename in os.listdir(original_folder):
if filename.endswith('.tif'):
dataset = gdal.Open(os.path.join(original_folder, filename), gdal.GA_ReadOnly)
width = dataset.RasterXSize
height = dataset.RasterYSize
band_count = dataset.RasterCount
driver = gdal.GetDriverByName('GTiff')
output_dataset = driver.Create(os.path.join(output_folder, "New_" + filename), width, height, band_count, gdal.GDT_Float32)
for band_index in range(1, band_count + 1):
band = dataset.GetRasterBand(band_index)
data = band.ReadAsArray()
if band_index == 1:
data = data.astype(float)
data[data > 1] /= 10000
elif band_index == 2:
data = data.astype(float)
data[data > 1] /= 10000
elif band_index == 3:
data = data.astype(float)
data[data > 1] /= 10000
elif band_index == 4:
data = data.astype(float)
data[data > 1] /= 10000
output_band = output_dataset.GetRasterBand(band_index)
output_band.WriteArray(data)
output_band.FlushCache()
output_dataset.SetGeoTransform(dataset.GetGeoTransform())
output_dataset.SetProjection(dataset.GetProjection())
dataset = None
output_dataset = None
首先,我们使用os.listdir()函数遍历原始数据文件夹中的所有文件,并使用if语句筛选出以.tif结尾的文件;随后,使用gdal.Open()函数打开原始影像数据集,并指定只读模式;接下来,使用dataset.RasterXSize和dataset.RasterYSize获取影像数据集的宽度和高度。
随后,使用dataset.RasterCount获取波段数量,并使用gdal.GetDriverByName()创建输出数据集的驱动程序对象;紧接着,通过Create()方法创建输出数据集,并指定输出文件的路径、宽度、高度、波段数量和数据类型(gdal.GDT_Float32表示浮点型)。
接下来,就可以开始使用循环,对每个文件的每个波段进行处理。首先,使用dataset.GetRasterBand()方法获取当前波段对象,然后使用band.ReadAsArray()将波段数据读取为数组;根据波段索引的不同,对波段数据进行处理。在本文中,对4个波段进行的其实是相同的处理,即将大于1的像素值除以10000。
其次,使用output_dataset.GetRasterBand()方法获取输出数据集中的当前波段对象,并使用output_band.WriteArray()方法将处理后的数据写入输出数据集。
再次,使用dataset.GetGeoTransform()和dataset.GetProjection()分别获取原始数据集的地理转换和投影信息,并使用output_dataset.SetGeoTransform()和output_dataset.SetProjection()设置输出数据集的地理转换和投影信息。
最后一步,关闭数据集对象。至此,代码就完成了对每个.tif文件的处理,并将处理后的数据保存到输出文件夹中。
此时,打开本文开头展示的那1景遥感影像,可以看到其像素数值已经是乘上缩放系数之后的了,也就是落在了0至1的区间内;如下图所示。
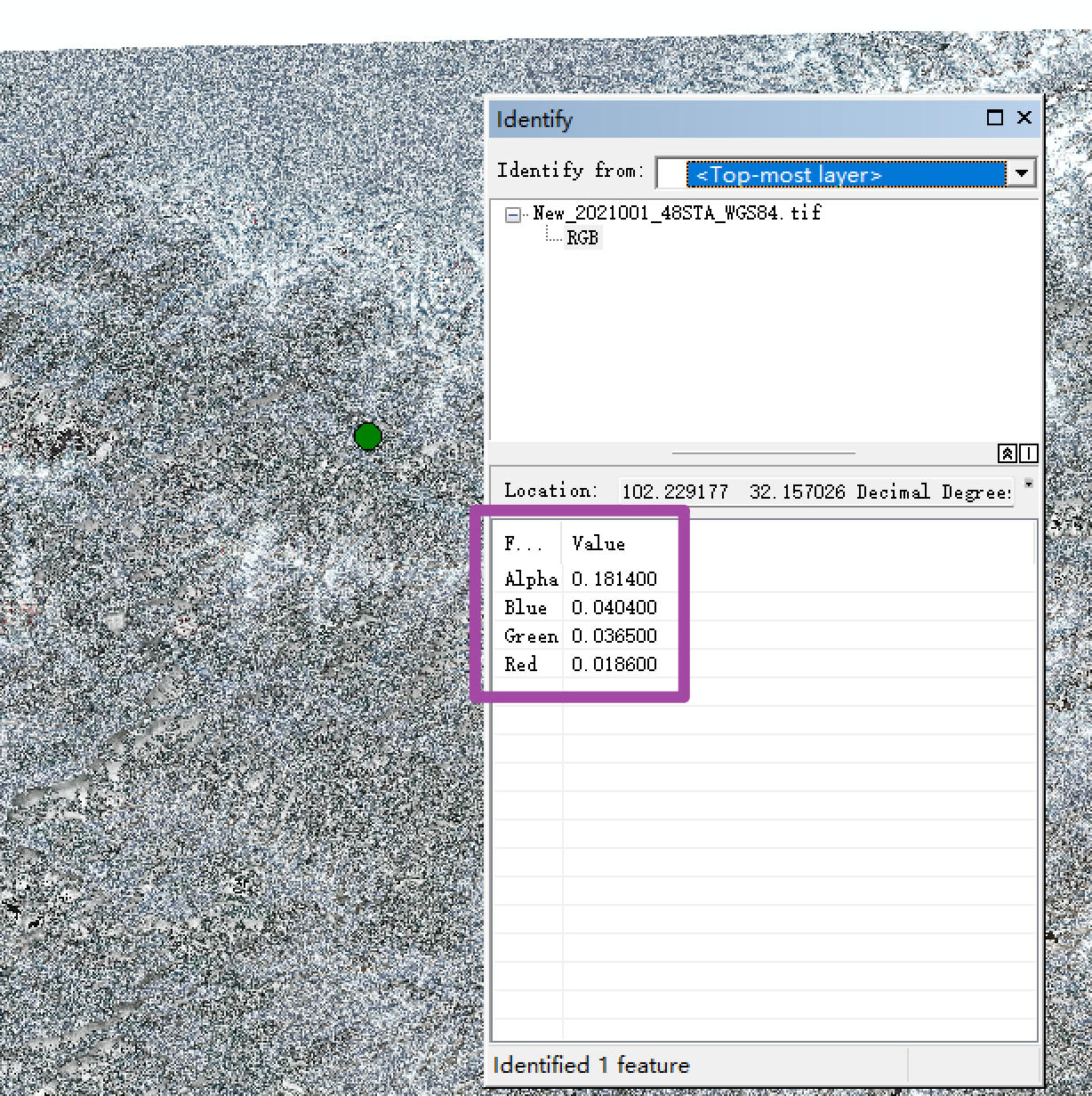
至此,大功告成。
Python代码将大量遥感数据的值缩放指定倍数的方法的更多相关文章
- python代码块,小数据池,驻留机制深入剖析
一,什么是代码块. 根据官网提示我们可以获知: 根据提示我们从官方文档找到了这样的说法: A Python program is constructed from code blocks. A blo ...
- python代码块和小数据池
id和is 在介绍代码块之前,先介绍两个方法:id和is,来看一段代码 # name = "Rose" # name1 = "Rose" # print(id( ...
- OpenCV中图像以Mat类型保存时各通道数据在内存中的组织形式及python代码访问各通道数据的简要方式
以最简单的4 x 5三通道图像为例,其在内存中Mat类型的数据组织形式如下: 每一行的每一列像素的三个通道数据组成一个一维数组,一行像素组成一个二维数组,整幅图像组成一个三维数组,即: Mat.dat ...
- 关于千里马招标网知道创宇反爬虫521状态码的解决方案(python代码模拟js生成cookie _clearence值)
一.问题发现 近期我在做代理池的时候,发现了一种以前没有见过的反爬虫机制.当我用常规的requests.get(url)方法对目标网页进行爬取时,其返回的状态码(status_code)为521,这是 ...
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
- 用不到 50 行的 Python 代码构建最小的区块链
引用 译者注:随着比特币的不断发展,它的底层技术区块链也逐步走进公众视野,引起大众注意.本文用不到50行的Python代码构建最小的数据区块链,简单介绍了区块链去中心化的结构与其实现原理. 尽管一些人 ...
- Python基础学习Day6 is id == 区别,代码块,小数据池 ---->>编码
一.代码块 Python程序是由代码块构造的.块是一个python程序的文本,他是作为一个单元执行的. 代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块. 而作为交互方式输入的每个命令都是 ...
- 5 种使用 Python 代码轻松实现数据可视化的方法
数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使 ...
- Python代码块缓存、小数据池
引子 前几天遇到了这样一道Python题目:a='123',b='123',下列哪个是正确的? A. a != b B. a is b C. a==123 D. a + b =246 正确答案是B 是 ...
- [转]5 种使用 Python 代码轻松实现数据可视化的方法
数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使 ...
随机推荐
- CSP模拟50联测12 T2 赌神
CSP模拟50联测12 T2 赌神 题面与数据规模 Ps:超链接为衡水中学OJ. 思路 \(subtask2\): 由于\(x_i\)较小,考虑 dp. 假设一开始球的颜色为红和蓝,设 \(dp[i] ...
- Pylon C++ Programmer's Guide
移步至Pylon C++ Programmer's Guide观看效果更佳 Getting Started pylon编程指南是一个关于如何使用Basler pylon C++ API进行编程的快速指 ...
- CodeForces - 1398C Good Subarrays
CodeForces - 1398C 挺简单的题目,但是没有想到还是整理一下 方法1 把每个元素都减1,那么满足题意的就是一段和的值是0,然后维护前缀和,如果发现这个前缀和之前出现过,就说明有满足题意 ...
- 教育账号无法登录OneDrive的一种解决方法
众所周知,微软的服务总是能出现一些奇奇怪怪的问题,比如说教育账号无法登录OneDrive,尝试使用网上的临时解决方案失败 onedrive学生账号无法登录win10 OneDrive客户端 用户可以在 ...
- (Redis基础教程之十) 如何在Redis中运行事务
介绍 Redis是一个开源的内存中键值数据存储.Redis允许您计划一系列命令,然后一个接一个地运行它们,这一过程称为_transaction_.每个事务都被视为不间断且隔离的操作,以确保数据完整性. ...
- memcached简介及java使用方法
一. 概念 Memcached是danga.com(运营LiveJournal的技术团队)开发的一套分布式内存对象缓存系统,用于在动态系统中减少数据库负载,提升性能. 二. 适用场合 1. 分布式应用 ...
- 如何实现LLM的通用function-calling能力?
众所周知,LLM的函数function-calling能力很强悍,解决了大模型与实际业务系统的交互问题.其本质就是函数调用. 从openai官网摘图: 简而言之: LLM起到决策的作用,告知业务系统应 ...
- AFL分析与实战
文章一开始发表在微信公众号 https://mp.weixin.qq.com/s?__biz=MzUyNzc4Mzk3MQ==&mid=2247486292&idx=1&sn= ...
- 规模法则(Scaling Law)与参数效率的提高,
上一篇:<人工智能大语言模型起源篇(三),模型规模与参数效率> 规模法则与效率提高 如果你想了解更多关于提高变换器效率的各种技术,我推荐阅读2020年的<Efficient Tran ...
- 基于知识图谱的医疗问答系统(dockerfile+docker-compose)
目录 一.搭建 Neo4j 图数据库 1.方式选择 2.Dockerfile+docker-compose部署neo4j容器 2.1.更新 yum 镜像源 2.2.安装 docker-ce 社区版 2 ...