JVM-总结列表
第一章 JVM内存结构
1、为什么要了解JVM内存管理机制
- JVM自动的管理内存的分配与回收,这会在不知不觉中浪费很多内存,导致JVM花费很多时间去进行垃圾回收(GC)
- 内存泄露,导致JVM内存最终不够用
2、JVM内存结构
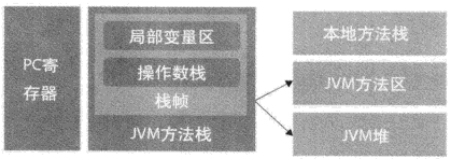
根据上图,JVM内存结构包括:
- 方法区 - Java虚拟机规范
- <jdk8 之前的实现是永久代,java8里彻底被移除,取而代之的是元数据区
- 堆
- 栈(在hotspot JVM中,JVM方法栈--Java虚拟栈,与本地方法栈是同一个)
- PC寄存器(程序计数器)
还有一块:
- 直接内存:直接向系统内存申请的一块内存区域,javaNIO会使用,速度优于java堆内存。- 隶属于物理内存,不属于JVM内存
注意点:
- 堆是GC的主要区域,方法区、直接内存也会发生GC
- 栈与PC寄存器是每个线程都会创建的私有区域,不会GC
- 直接内存使用速度由于堆内存,但是内存的申请速度低于堆内存
2.1、方法区
- 存放内容(类的各种信息-包括属性和方法、类static属性、常量池)
- 已经加载的类的信息(名称、修饰符等)
- 类中的field信息
- 类中的方法信息
- 类中的static变量
- 类中定义为final常量
- 运行时常量池:编译器生成的各种字面量和符号引用(编译期)存储在class文件的常量池中,这部分内容会在类加载之后进入运行时常量池,class文件的常量池查看 第三章 类文件结构与javap的使用
- 使用实例:反射,在程序中通过Class对象调用getName等方法获取信息数据时,这些信息数据来源于方法区。
- 调节参数
- -XX:PermSize:指定方法区的最小值,默认为16M
- -XX:MaxPermSize:指定方法区的最大值,默认为64M
- 所抛错误
- 方法区域要使用的内存超过了其允许的大小时,抛出OutOfMemoryError
- 内存回收的主要目标
- 对类的卸载(这也是为什么很多企业使用velocity等模板引擎做前端而不是使用jsp的原因之一)
- 针对常量池的回收
- 总结
- 一般而言,在企业开发中,-XX:PermSize==-XX:MaxPermSize
- 通常,这个大小设置为256M就没问题了,当然还要根据自己的程序去预估,并在运行过程中去调整,这里以在Resin服务器中配置为例
<jvm-arg>-XX:PermSize=256M</jvm-arg>
<jvm-arg>-XX:MaxPermSize=256M</jvm-arg> - 类中的static变量会在方法区分配内存,但是类中的实例变量不会(类中的实例变量会随着对象实例的创建一起分配在堆中,当然若是基本数据类型的话,会随着对象的创建直接压入操作数栈)
- 关于方法区的存放内容,可以这样去想所有的通过Class对象可以反射获取的都是从方法区获取的(包括Class对象也是方法区的,Class是该类下所有其他信息的访问入口)
注意:常量池在jdk1.6在方法区;在jdk1.7在堆
附:元数据区
- 调节参数:-XX:MaxMetaspaceSize,如果不指定大小,极限情况下可能耗尽系统所有内存
- 元数据区是堆外的一块直接内存
2.2、堆
- 存放内容
- 对象实例(类中的实例变量会随着对象实例的创建一起分配在堆中,当然若是基本数据类型的话,会随着对象的创建直接压入操作数栈),这一点查看 第四章 类加载机制
- 数组值
- 使用实例
- 所有通过new创建的对象都在这块儿内存分配,具体分配到年轻代还是年老代需要根据配置参数而定(新建对象直接分配到年老代有两种情况,看下边)
- 调节参数
- -Xmx:最大堆内存,默认为物理内存的1/4但小于1G
- -Xms:最小堆内存,默认为物理内存的1/64但小于1G
- -XX:MinHeapFreeRatio,默认当空余堆内存小于最小堆内存的40%时,堆内存增大到-Xmx
- -XX:MaxHeapFreeRatio,当空余堆内存大于最大堆内存的70%时,堆内存减小到-Xms
- 注意点
- 在实际使用中,-Xmx与-Xms配置成相等的,这样,堆内存就不会频繁的进行调整了
- 抛出错误
- OutOfMemoryError:在堆中没有内存完成实例分配(关于实例内存的分配,之后再说),此时堆内存已达到最大无法扩展时。
- 堆内存划分
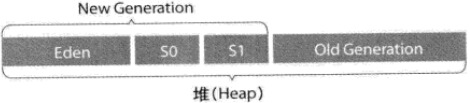
- 新生代
- 组成:Eden+From(S0)+To(S1)
- -Xmn:整个新生代的大小
- -XX:SurvivorRatio:调整Eden:From(To)的比率,默认为8:1
- 年老代
- 新建对象直接分配到年老代,两种情况
- 大对象:-XX:PretenureSizeThreshold(单位:字节)参数来指定大对象的标准,在Parallel Scavenge GC下可能无效,具体见《第五章 JVM垃圾收集器(1) 》
- 大数组:数组中的元素没有引用任何外部的对象
- 新建对象直接分配到年老代,两种情况
- 新生代
- 总结
- 企业开发中,-Xmx==-Xms
- -Xmx的设置要根据自己的程序去预估,并在运行过程中去调整,这里以在Resin服务器中配置为例
<jvm-arg>-Xms2048m</jvm-arg>
<jvm-arg>-Xmx2048m</jvm-arg>
<jvm-arg>-Xmn512m</jvm-arg>
<jvm-arg>-XX:SurvivorRatio=8</jvm-arg>
<jvm-arg>-XX:MaxTenuringThreshold=15</jvm-arg>可以看到,-Xms==-Xmx==2048m,年轻代大小-Xmn==512m,这样,年老代大小就是2048-512==1536m,这个比率值得记住,在企业开发中,年轻代:年老代==1:3,而此时,我们配置的-XX:MaxTenuringThreshold=15(这也是默认值),年轻代对象经过15次的复制后进入到年老代(关于这一点,在之后的GC机制中会说),
- -XX:MaxTenuringThreshold与-XX:PretenureSizeThreshold不一样,不要看错
2.3、栈
- 注意点
- 每条线程都会分配一个栈,每个栈中有多个栈帧(每一个方法对应一个栈帧)
- 线程创建的时候创建一个线程的java栈
- 每个方法在执行的同时都会创建一个栈帧,每个栈帧用于存储当前方法的局部变量表、操作数栈等,具体查看本文第一个图,每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程,说的更明白一点,就是方法执行时创建栈帧,方法结束时释放栈帧所占内存
- 存放内容
- 局部变量表:八大基本数据类型数据、对象引用。该空间在编译期已经分配好,运行期不变。
- 操作数栈:是执行引擎直接操作的部分
- 调节参数
- -Xss:设置栈的大小,通常设置为1m就好
<jvm-arg>-Xss1m</jvm-arg>
- -Xss:设置栈的大小,通常设置为1m就好
- 支持native方法执行(本地方法栈)
- 所抛错误
- StackOverFlowError:线程请求的栈深度大于虚拟机所允许的深度。
- 栈的深度就是方法调用嵌套的层数,受限于-Xss的大小
- 典型场景:没有终止条件的递归(递归基于栈)。
- 每个方法的栈的深度在javac编译之后就已经确定了,查看 第三章 类文件结构与javap的使用
- OutOfMemoryError:虚拟机栈可以动态扩展,如果扩展的时候无法申请到足够的内存。
- 需要注意的是,栈可以动态扩展,但是栈中的局部变量表不可以。
- StackOverFlowError:线程请求的栈深度大于虚拟机所允许的深度。
2.4、PC寄存器(程序计数器)
- 概念:当前线程所执行的字节码的行号指示器,用于字节码解释器对字节码指令的执行。
- 多线程:通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个时刻,一个处理器(也就是一个核)只能执行一条线程中的指令,为了线程切换后能恢复到正确的执行位置,每条线程都要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。
附:对象分配(《实战java虚拟机》)
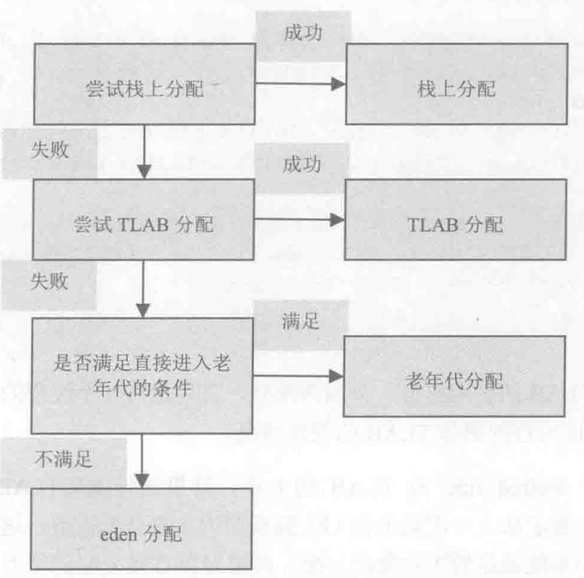
第二章 JVM内存分配
1、创建一个真正对象的基本过程
六步:
- 1. 类加载机制检查
- JVM首先检查一个new指令的参数是否能在常量池中定位到一个符号引用,并且检查该符号引用代表的类是否已被加载、解析和初始化过(实际上就是在检查new的对象所属的类是否已经执行过类加载机制)。如果没有,先进行类加载机制加载类。关于类加载机制,之后再说。
- 2. 分配内存
- 把一块儿确定大小的内存从Java堆中划分出来
- 3. 初始化对象
- 初始化零值(操作实例数据部分--对象内存布局三部分之一)
- 对象的实例字段不需要赋初始值也可以直接使用其默认零值,就是这里起得作用
- 每一种类型的对象都有不同的默认零值
- 设置对象头(操作对象头部分--对象内存布局三部分之一)
- 参看对象内存布局《附 Java对象内存布局》
- 执行<init>
- 为对象的字段赋值(在第三步只是初始化了零值,这里会根据所写程序给实例赋值)
- 初始化零值(操作实例数据部分--对象内存布局三部分之一)
- 4.将创建的对象指向分配的内存
注意:第三步和第四步可能发生指令重排序,这也是单例模式使用 volatile 修饰对象的原因。
2、内存分配概念
- 在类加载完成后,一个对象所需的内存大小就可以完全确定了,具体的情况查看对象的内存布局。
- 为对象分配空间,即把一块儿确定大小(上述确定下来的对象内存大小)的内存从Java堆中划分出来
3、内存分配两种方式
- 指针碰撞
- 适用场合:堆内存规整(即没有内存碎片)的情况下
- 原理:用过的内存全部整合到一边,没有用过的内存放在另一边,中间有一个分界值指针,只需要向着没用过的内存方向将该指针移动对象内存大小位置即可
- GC收集器:Serial、ParNew
- 空闲列表
- 适用场合:堆内存不规整的情况下
- 原理:虚拟机会维护一个列表,该列表中会记录哪些内存块是可用的,在分配的时候,找一块儿足够大的内存块儿来划分给对象实例(这一块儿可以类比memcached的slab模型),最后更新列表记录。关于memcached slab内存模型介绍查看《第六章 memcached剖析》
- GC收集器:CMS
- 注意
- 选择以上两种方式中的哪一种,取决于Java堆内存是否规整
- Java堆内存是否规整,取决于GC收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的
4、内存分配并发问题
堆内存是各个线程的共享区域,所以在操作堆内存的时候,需要处理并发问题。处理的方式有两种:
- CAS+失败重试
- 具体的做法与AtomicInteger的getAndSet(int newValue)方法的实现方式类似,关于AtomicInteger的源码解析,查看《第十一章 AtomicInteger源码解析》
- TLAB(Thread Local Allocation Buffer)
- 原理:为每一个线程预先在Eden区分配一块儿内存,JVM在给线程中的对象分配内存时,首先在TLAB分配,当对象大于TLAB中的剩余内存或TLAB的内存已用尽时,再采用上述的CAS进行内存分配
- -XX:+/-UseTLAB:是否使用TLAB
- -XX:TLABWasteTargetPercent设置TLAB可占用的Eden区的比率,默认为1%
- JVM会根据以下三个条件来给每个线程分配合适大小的TLAB
- -XX:TLABWasteTargetPercent
- 线程数量
- 线程是否频繁分配对象
- -XX:PrintTLAB:查看TLAB的使用情况
5、总结
- 尽量少创建对象
- 根据第一块儿所说,创建一个对象的过程比较复杂,耗时较多,所以尽量减少对象的创建
- 对象创建的少,将来垃圾收集器收集的垃圾也就少,提高效率
- 对象创建的少,占用内存也就少,那么剩余的系统内存也就相对多,系统运行也就快
- 避免在经常使用的方法中或循环中创建对象
- 多个小的对象比大对象分配起来更加高效
- 这是根据TLAB得出来的,多个小对象可以并行在各自的TLAB分配内存,而大对象的话,可能只能通过CAS同步来分配内存
- 衡量上述两点
- 对于String
- 尽量使用直接量:eg. String str = "hello";//常量会直接存在"常量池",而非String str = new String("hello");//除了将"hello"存在"常量池"之外,还会创建一个char[]
- 不要使用String去拼接字符串,会形成许多临时字符串:如下,
String s1 = "hello1";
String s2 = "hello2";
String s3 = "hello3";
String s4 = s1+s2+s3;实际上,我们只想要字符串s1+s2+s3,但是在上述的拼接过程中,会形成s1+s2的临时字符串。拼接字符串,使用StringBuilder,该类相较于StringBuffer由于不是同步类,其运行效果会更好。
- 尽早释放无用对象的引用(帮助垃圾回收)
public void info(){
Object obj = new Object();
System.out.println(obj.hashCode());
obj = null;//显式释放无用对象
}如上边方法所示,其中的obj是一个局部变量,在方法执行结束后,栈帧就会出栈并被回收,栈帧中所存储的局部变量一起被回收掉了,所以这里的"obj=null;"就没用了,但是看下边
public void info(){
Object obj = new Object();
System.out.println(obj.hashCode());
obj = null;//显式释放无用对象
//下边还有一些很耗时、很耗内存的操作,这些操作与obj无关
}这时候,如果我们加上了"obj=null;"这一句,那么就有可能在方法执行结束之前,obj被回收。
- 尽量少使用static变量,因为static变量属于类变量,存储于方法区,其所占内存无法被垃圾回收器回收掉,除非static所属的类被卸载掉。
- 常用的对象放入缓存或连接池(其实,连接池也可以看做是一个缓存)
- 考虑使用SoftReference(关于几种引用方式,之后会说)
- 当内存足够时,功能等同于普通变量
- 当内存不足时,释放软引用所引用的对象
- 一般用于大数组、大对象
- 通过软引用所获取的对象可能为null(当内存不足时,释放软引用所引用的对象),在应用程序中需要显示判断对象是否为null,若为null,需要重建对象
第三章 JVM内存回收区域+对象存活的判断+引用类型+垃圾回收线程
1、内存回收的区域
- 堆:这是GC的主要区域
- 方法区:回收两样东西
- 无用的类
- 废弃的常量
- 栈和PC寄存器是线程私有区域,不发生GC
2、怎样判断对象是否存活
垃圾回收:回收掉死亡对象所占的内存。判断对象是否死亡,有两种方式:
- 引用计数法
- 原理:给对象添加一个引用计数器,每当有一个地方引用它时,计数器值+1;引用失效时,计数器值-1
- 实际中不用,不用的两个原因
- 每次为对象赋值时,都要进行计数器值的增减,消耗较大
- 对于A、B相互引用这种情况处理不了(这一点是不用的主要原因)
- 可达性分析(跟踪收集)
- 原理:从根集合(GC Roots)开始向下扫描,根集合中的节点可以到达的节点就是存活节点,根集合中的节点到达不了的节点就是将要被回收的死亡节点,如下图中的A/B/C是存活节点,D/E是死亡节点:

- 根集合中的节点包括:简单来讲,就是全局性的引用(常量和静态属性)和栈引用(下边第一、三)
- Java栈中的对象引用(存在于局部变量表中,注意:局部变量表中存放的是基本数据类型和对象引用)
- 这是垃圾回收最多考虑的地方,所以有时,我们也会将死亡对象称为"没有引用指向的对象"
- 方法区中:常量+静态(static)变量
- 传到本地方法中,还没有被本地方法释放的对象引用
- Java栈中的对象引用(存在于局部变量表中,注意:局部变量表中存放的是基本数据类型和对象引用)
- 根集合中的节点包括:简单来讲,就是全局性的引用(常量和静态属性)和栈引用(下边第一、三)
3、3种引用类型
- 强引用(Strong Reference):A a = new A();//a是强引用
- 软引用(Soft Reference):当内存不足时,释放软引用所引用的对象;当内存足够时,就是一个普通对象(强引用)
- 弱引用(Weak Reference):弱引用对象只能存活到下一次垃圾回收之前,一旦发生垃圾回收,立刻被回收掉
4、方法区的回收
- 废弃常量:例如,没有任何一个引用指向常量池中的"abc"字符串,则"abc"字符串被回收
- 无用的类:满足以下三个条件
- Java堆中不存在该类的任何实例
- 加载该类的ClassLoader被回收
- 该类的Class对象没有在任何地方被引用
注意:
- 在实际开发中,尽量不用JSP去做前端,而是用velocity、freemarker这样的模板引擎去做
- 与类相关常用的三个参数:
- -XX:+PrintClassHistogram:输出类统计状态
- -XX:-TraceClassLoading:打印类加载信息
- -XX:-TraceClassUnloading:打印类卸载信息
5、垃圾回收线程
系统的垃圾回收是由垃圾回收线程来检测操作的,该线程是一个后台线程(daemon thread)。
5.1、后台线程与我们使用的前台线程而言,有一个特点:当JVM中的前台线程数量为0时,后台线程自动消亡。可以这样讲,后台线程依托于前台线程而存在。
5.2、垃圾回收线程为什么要设置成为后台线程呢?
我们想一下,当前台一个线程都没有时,垃圾还会有吗?或者说垃圾回收还有必要吗?答案是没有必要,所以此时垃圾回收线程也就失去了存活的意义。
所以可以这样讲,将一个线程是否设置为后台线程,就看这条线程在没有其他线程存在的情况下,是否还有存活的意义。
例如,在我们使用Apache mina2做RPC时,我们在消息的接收端直接开启一个后台线程启动服务来接受消息发送端发来的消息事件请求就可以。试着去想,如果在整个JVM中只有当前的这一个后台线程了,那么这个线程还有必要存活下来吗?当然没有必要,因为消息永远都不会再发送了(前台线程都没了)
第四章 JVM垃圾回收算法
1、三种垃圾回收算法
- 标记-清除(年老代)
- 标记-整理(即标记-压缩)(年老代)
- 复制(年轻代)
1.1、标记-清除算法

原理:
- 从根集合节点进行扫描,标记出所有的存活对象,最后扫描整个内存空间并清除没有标记的对象(即死亡对象)
适用场合:
- 存活对象较多的情况下比较高效
- 适用于年老代(即旧生代)
缺点:
- 容易产生内存碎片,再来一个比较大的对象时(典型情况:该对象的大小大于空闲表中的每一块儿大小但是小于其中两块儿的和),会提前触发垃圾回收
- 扫描了整个空间两次(第一次:标记存活对象;第二次:清除没有标记的对象)
注意:
1.2、标记整理算法
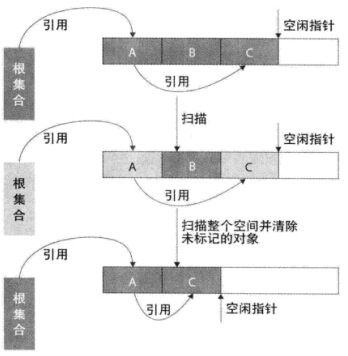
原理:
- 从根集合节点进行扫描,标记出所有的存活对象,最后扫描整个内存空间并清除没有标记的对象(即死亡对象)(可以发现前边这些就是标记-清除算法的原理),清除完之后,将所有的存活对象左移到一起。
适用场合:
- 用于年老代(即旧生代)
缺点:
- 需要移动对象,若对象非常多而且标记回收后的内存非常不完整,可能移动这个动作也会耗费一定时间
- 扫描了整个空间两次(第一次:标记存活对象;第二次:清除没有标记的对象)
优点:
- 不会产生内存碎片
注意:
- 在该情况下,内存规整,对象的内存分配采用"指针碰撞法",见《第二章 JVM内存分配》
1.3、复制算法
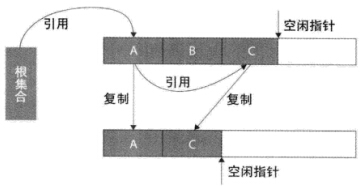
原理:
- 从根集合节点进行扫描,标记出所有的存活对象,并将这些存活的对象复制到一块儿新的内存(图中下边的那一块儿内存)上去,之后将原来的那一块儿内存(图中上边的那一块儿内存)全部回收掉
适用场合:
- 存活对象较少的情况下比较高效
- 扫描了整个空间一次(标记存活对象并复制移动)
- 适用于年轻代(即新生代):基本上98%的对象是"朝生夕死"的,存活下来的会很少
缺点:
- 需要一块儿空的内存空间
- 需要复制移动对象
注意:
- 在该情况下,内存规整,对象的内存分配采用"指针碰撞法",见《第二章 JVM内存分配》
- 以空间换时间:通过一块儿空内存的使用,减少了一次扫描
2、垃圾回收机制
根据《第一章 JVM内存结构》所说,年轻代分为Eden区和survivor区(两块儿:from和to),且Eden:from:to==8:1:1
1)新产生的对象优先分配在Eden区(除非配置了-XX:PretenureSizeThreshold,大于该值的对象会直接进入年老代);
2)当Eden区满了或放不下了,这时候其中存活的对象会复制到from区(这里,需要注意的是,如果存活下来的对象from区都放不下,则这些存活下来的对象全部进入年老代),之后Eden区的内存全部回收掉;注意:如果是Eden区没有满,但是来了一个小对象Eden区放不下,这时候Eden区存活对象复制到from区后,清空Eden区,之后刚才的小对象再进入Eden区
3)之后产生的对象继续分配在Eden区,当Eden区又满了或放不下了,这时候将会把Eden区和from区存活下来的对象复制到to区(同理,如果存活下来的对象to区都放不下,则这些存活下来的对象全部进入年老代),之后回收掉Eden区和from区的所有内存;
4)如上这样,会有很多对象会被复制很多次(每复制一次,对象的年龄就+1),默认情况下,当对象被复制了15次(这个次数可以通过:-XX:MaxTenuringThreshold来配置),就会进入年老代了
5)当年老代满了或者存放不下将要进入年老代的存活对象的时候,就会发生一次Full GC(这个是我们最需要减少的,因为耗时很严重)
总结:
- 年轻代:复制算法
- 年老代:标记-清除或标记-整理(前者相较于后者会快一些但是会产生内存碎片,后者相较于前者不会产生内存碎片但是由于要移动存活对象所以会慢一些)
- 以上这种年轻代与年老代分别采用不同回收算法的方式称为"分代收集算法",这也是当下企业使用的一种方式
- 每一种算法都会有很多不同的垃圾回收器去实现,在实际使用中,根据自己的业务特点做出选择就好
第六章 JVM垃圾收集器
1、G1

说明:
- 从上图来看,G1与CMS相比,仅在最后的"筛选回收"部分不同(CMS是并发清除),实际上G1回收器的整个堆内存的划分都与其他收集器不同。
- CMS需要配合ParNew,G1可单独回收整个空间
原理:
- G1收集器将整个堆划分为多个大小相等的Region
- G1跟踪各个region里面的垃圾堆积的价值(回收后所获得的空间大小以及回收所需时间长短的经验值),在后台维护一张优先列表,每次根据允许的收集时间,优先回收价值最大的region,这种思路:在指定的时间内,扫描部分最有价值的region(而不是扫描整个堆内存),并回收,做到尽可能的在有限的时间内获取尽可能高的收集效率。
运作流程:
- 初始标记:标记出所有与根节点直接关联引用对象。需要STW
- 并发标记:遍历之前标记到的关联节点,继续向下标记所有存活节点。
- 在此期间所有变化引用关系的对象,都会被记录在Remember Set Logs中
- 最终标记:标记在并发标记期间,新产生的垃圾。需要STW
- 筛选回收:根据用户指定的期望回收时间回收价值较大的对象(看"原理"第二条)。需要STW
优点:
- 停顿时间可以预测:我们指定时间,在指定时间内只回收部分价值最大的空间,而CMS需要扫描整个年老代,无法预测停顿时间
- 无内存碎片:垃圾回收后会整合空间,CMS采用"标记-清理"算法,存在内存碎片
- 筛选回收阶段:
- 由于只回收部分region,所以STW时间我们可控,所以不需要与用户线程并发争抢CPU资源,而CMS并发清理需要占据一部分的CPU,会降低吞吐量。
- 由于STW,所以不会产生"浮动垃圾"(即CMS在并发清理阶段产生的无法回收的垃圾)
适用范围:
- 追求STW短:若ParNew/CMS用的挺好,就用这个;若不符合,用G1
- 追求吞吐量:用Parallel Scavenge/Parallel Old,而G1在吞吐量方面没有优势
2、几点注意
问题1、G1以外的其他收集器在回收垃圾的时候:要不只是扫描年轻代,要不只是扫描年老代。在年轻代的回收过程中,如果旧生代中的对象引用了年轻代的对象,那么我们只扫描年轻代就不行了,但是由于年老代一般而言是年轻代的3倍大小,如果年轻代、年老代一起去扫描的话,效率会急剧下降,这个问题怎么处理?
答:JVM采用remember set来做的这个事儿,当发现一个引用对象被赋值时,JVM发出一个write barrier指令来暂时中断写操作,检查被赋值的引用对象是不是处于年老代,且其引用的对象是不是处于新生代(即是不是年老代对象引用了年轻代对象),如果是,将相关引用信息记录到remember set。之后的扫描,我们会从根集合+remember set向下进行扫描。(也就是说真正的根集合,是JVM定义的根集合+remember set)
问题2、G1收集器为了做到GC时间可预测,采用扫描部分价值最大的region来实现,那么如果这部分region中的对象被其他region中的对象所引用,那么仅扫描前者可能就不行了,但是如果扫描全部region的话,又无法做到GC时间可预测,效率会大大下降,怎么办?
答:G1同理,为每一个region分配一个remember set,当发现一个引用对象被赋值时,JVM发出一个write barrier指令来暂时中断写操作,检查被赋值的引用对象与其引用的对象是不是处于不同的region(eg.a=b;检查a与b是不是在不同的region),如果是,将相关引用信息记录到当前region的remember set。之后的扫描,我们会从根集合+remember set向下进行扫描。
问题3、CMS与G1在并发标记的时候若发部分引用对象的引用关系发生了变化,怎么处理才能让重新标记的时候仅仅扫描出这些变化?
答:在并发标记期间,对象的引用关系若发生了变化,这些相关的记录就会记录到remember set logs;在重新标记阶段,将该logs的信息加入到remember set中去,然后再从remember set去向下trace节点。
第七章 JVM性能监控与故障处理工具
1、定位系统问题
- 依据
- GC日志
- 堆转储快照(heapdump/hprof文件)
- 线程快照(threaddump/javacore文件)
- 运行日志
- 异常堆栈
- 分析依据的工具
- jps:显示指定系统内的所有JVM进程
- jstat:收集JVM各方面的运行数据
- jinfo:显示JVM配置信息
- jmap:形成堆转储快照(heapdump文件)
- jhat:分析heapdump文件
- jstack:显示JVM的线程快照
- jconsole
- visualVM
说明:后边两种是具有图形化界面的。
2、jps(是其他所有命令的基础)
作用:列出所有的JVM虚拟机进程。
格式:jps -l
jps是jdk提供的一个查看当前java进程的小工具, 可以看做是JavaVirtual Machine Process Status Tool的缩写。非常简单实用。
命令格式:jps [options ] [ hostid ]
[options]选项 :
-q:仅输出VM标识符,不包括classname,jar name,arguments in main method
-m:输出main method的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption:传递参数到vm,例如:-J-Xms512m
————————————————
3、jstat(是没有GUI界面的情况下,在运行期定位JVM性能问题的首选)
作用:查看gc数据和类加载卸载数据,它可以显示Java虚拟机中的类加载、内存、垃圾收集、即时编译等运行状态的信息。
格式:jstat option PID interval count
意义:每隔interval毫秒做一次option,一共做count次

说明:S0(from区)使用了41.74%;S1(to区)使用了0;E(Eden区)使用了54.35%;O(Old,年老代)使用了62.41%;P(Perment,永久代)使用了99.63%;YGC(Young GC)了32次,YGCT(Young GC Time)花销0.132秒;FGC(Full GC)了1次,FGCT(Full GC Time)花销0.102秒;GCT(GC Time)总花销0.234秒。
分析:其实上边这个查询结果可以直接看出,我们需要加大P(永久代大小)

说明:加载了3683个类,总共占有4355.3字节;卸载了0个类,卸载的类的字节数为0,类的加载与卸载共花销3.16秒
更多的jstat的使用,参看 http://my.oschina.net/skyline520/blog/304805
命令语法:
jstat generalOptions
jstat outputOptions [-t] [-h<lines>] <vmid> [<interval> [<count>]]
命令参数说明:
generalOptions:通用选项,如果指定一个通用选项,就不能指定任何其他选项或参数。它包括如下两个选项:
-help:显示帮助信息。
-options:显示outputOptions参数的列表。
outputOptions:输出选项,指定显示某一种Java虚拟机信息。
-t:把时间戳列显示为输出的第一列。这个时间戳是从Java虚拟机的开始运行到现在的秒数。
-h n:每显示n行显示一次表头,其中n为正整数。默认值为 0,即仅在第一行数据显示一次表头。
vmid:虚拟机唯一ID(LVMID,Local Virtual Machine Identifier),如果查看本机就是Java进程的进程ID。
interval:显示信息的时间间隔,单位默认毫秒。也可以指定秒为单位,比如:1s。如果指定了该参数,jstat命令将每个这段时间显示一次统计信息。
count:显示数据的次数,默认值是无穷大,这将导致jstat命令一直显示统计信息,直到目标JVM终止或jstat命令终止。
————————————————
输出选项
如果不指定通用选项(generalOptions),则可以指定输出选项(outputOptions)。输出选项决定jstat命令显示的内容和格式,具体如下:
-class:显示类加载、卸载数量、总空间和装载耗时的统计信息。
-compiler:显示即时编译的方法、耗时等信息。
-gc:显示堆各个区域内存使用和垃圾回收的统计信息。
-gccapacity:显示堆各个区域的容量及其对应的空间的统计信息。
-gcutil:显示有关垃圾收集统计信息的摘要。
-gccause:显示关于垃圾收集统计信息的摘要(与-gcutil相同),以及最近和当前垃圾回收的原因。
-gcnew:显示新生代的垃圾回收统计信息。
-gcnewcapacity:显示新生代的大小及其对应的空间的统计信息。
-gcold: 显示老年代和元空间的垃圾回收统计信息。
-gcoldcapacity:显示老年代的大小统计信息。
-gcmetacapacity:显示元空间的大小的统计信息。
-printcompilation:显示即时编译方法的统计信息。
jstat命令的显示输出被格式化为一个表,列用空格分隔。接下来,我来了解一下每条输出选项的列名。
————————————————
4、jinfo
作用:查看和运行期修改JVM的配置参数
格式:
- jinfo -flags PID
- jinfo -flag parameter PID

说明:查看3732进程下的MaxTenuringThreshold参数值。

说明:修改3732进程下的MaxTenuringThreshold参数值,但是windows下失败。
jinfo使用方法
// 常规使用方法
jinfo [option] <pid>
// 打印特定参数
jinfo [option] <executable <core>
// 远程连接
jinfo [option] [server_id@]<remote server IP or hostname>
option命令详解
如果不加option,将会输出全部的参数和系统属性,就像这样:jinfo 4780
flag name :输出对应名称的参数
flag [+|-]name :开启或者关闭对应名称的参数
flag name=value :设定对应名称的参数
flags :输出全部的参数
sysprops :输出所有系统属性
————————————————
5、jmap
作用:生成堆转储快照和查看最占内存的元素,用于分析内存泄露问题
格式(生成堆转储快照):jmap -dump:format=b,file=文件名 PID

说明:生成了3732进程的堆转储文件myfile
格式(查看最占内存的元素):jmap -histo PID

说明:结果自己去看,太多了
使用方法
命令格式:
jmap [options] <pid>
options参数命令详解
no option:不带参数查询进程,就像这样jmap 12271,查看内存中共享对象信息;,类似Solaris pmap命令;
heap: 显示java堆详细信息
histo[:live] :显示堆中对象的统计信息,加:live值打印存活的对象,如果不加:live则查询所有的对象;
clstats:打印类加载信息
finalizerinfo:显示在F-Queue队列等待被清理的对象;在发生GC之前某些对象可能要被回收,那么在回收之前,这些对象就会放到F-Queue队列中;清理时会执行对象的finalizer()方法;
dump :生成堆转储快照;
————————————————
1、获取heap的概要信息,GC使用的算法,heap(堆)的配置及JVM堆内存的使用情况jmap -heap 进程id
2、获取每个class的实例数目,字节数,类全名信息。如果live子参数加上后,只统计活的对象数量。jmap -histo:live 进程id
查看对象数最多的对象,并按降序排序输出:jmap -histo <pid>|grep alibaba|sort -k 2 -g -r|less
查看占用内存最多的最象,并按降序排序输出:jmap -histo <pid>|grep alibaba|sort -k 3 -g -r|less
3、获取正等候回收的对象的信息jmap -finalizerinfo 进程id
4、查看堆内存快照,输出jvm的heap内容到文件, live子选项是可选的,假如指定live选项,那么只输出活的对象到文件jmap -dump:live,format=b,file=myjmapfile.txt 进程id
————————————————
6、jhat
作用:分析堆转储快照(与jmap配合)
格式:jhat 文件名
说明:执行上述命令后,打开localhost:7000,找到如下红框部分打开,这里才是我们最关注的东西。
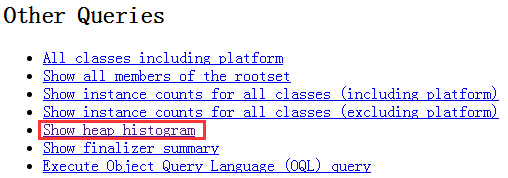
注意:该工具是万不得已才用的。
推出命令使用"ctrl+c"
简介
- jhat命令解析Java堆转储文件,可以将堆中的对象以html的形式显示出来,包括对象的数量、大小等等。
- jhat命令支持预先设计的查询,例如,显示一个已知类MyClass的所有实例,以及对象查询语言(OQL)。
- 本命令在以后的版本中可能不再支持。
语法
jhat [-stack <bool>] [-refs <bool>] [-port <port>] [-baseline <file>] [-debug <int>] [-version] [-h|-help] <heap-dump-file>
heap-dump-file:要分析的Java二进制堆转储文件,对于包含多个堆转储的转储文件,您可以通过在文件名后面附加#来指定文件中的转储,例如,myfile.hprof#3。
生成堆转储文件的几种方式
- 使用【jmap -dump:[live,]format=b,file=<filename>】命令
- 使用jconsole命令,可以在运行时通过 HotSpotDiagnosticMXBean 获取堆转储文件
- JVM配置-XX:+HeapDumpOnOutOfMemoryError参数,当抛出OutOfMemoryError时,自动生成堆转储文件。
- 使用hprof命令。
参数
-stack false|true
关闭跟踪对象分配调用堆栈。
如果在堆转储中无法获得分配站点信息,则必须将该标志设置为false。默认为true。
-refs false|true
关闭对对象的引用跟踪。默认是true。
默认情况下,为堆中的所有对象计算反向指针,反向指针是指向指定对象(如引用或传入引用)的对象。
-port port-number
设置jhat HTTP服务器的端口。默认是7000。
-exclude exclude-file
指定一个文件,该文件列出应从可达对象查询中排除的数据成员。
例如,如果文件中列出java.lang.String。value,然后,无论何时计算从特定对象o可到达的对象列表,涉及java.lang.String.value字段的引用路径都不会被考虑。
-baseline exclude-file
指定基线堆转储。
两个堆转储中具有相同对象ID的对象被标记为不是新的。
其他对象被标记为新的。这对于比较两个不同的堆转储非常有用。
-debug int
设置此工具的调试级别。
0级别表示没有调试输出。想要更详细的调试级别,则需要设置更高的值。
-version
显示版本号。
-h or -help
显示jhat命令的帮助信息
-Jflag
将flag传递给正在运行jhat命令的Java虚拟机。
7、jstack
作用:生成线程快照,定位线程长时间卡顿的原因(线程间死锁、死循环、请求外部资源导致的长时间等待)
格式:jstack -l PID

说明:查看3732进程中的所有线程的堆栈信息
《深入理解Java虚拟机》的作者提供了一个工具jsp页面,使得我们可以在程序运行时,随时运行该jsp页面,来查看线程堆栈信息,代码如下:
<%@ page language="java" contentType="text/html; charset=UTF-8"
2 pageEncoding="UTF-8" import="java.util.Map"%>
3 <!DOCTYPE html>
4 <html>
5 <head>
6 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
7 <title>jstack</title>
8 </head>
9 <body>
10 <%
11 for(Map.Entry<Thread, StackTraceElement[]> stackTrace : Thread.getAllStackTraces().entrySet()){
12 Thread thread = (Thread)stackTrace.getKey();
13 StackTraceElement[] elements = (StackTraceElement[])stackTrace.getValue();
14
15 /* if(thread.equals(Thread.currentThread())){
16 continue;
17 } */
18 out.println("\n线程:"+thread.getName()+"\n");
19 for(StackTraceElement ele : elements){
20 out.println("\t"+ele+"\n");
21 }
22 }
23 %>
24 </body>
25 </html>
注意:代码中我注释掉一段,是因为想也查出当前线程的堆栈信息,作者并没有这个注释。
jstack命令
Usage:
jstack [-l] <pid>
(to connect to running process)
jstack -F [-m] [-l] <pid>
(to connect to a hung process)
jstack [-m] [-l] <executable> <core>
(to connect to a core file)
jstack [-m] [-l] [server_id@]<remote server IP or hostname>
(to connect to a remote debug server)
Options:
-F to force a thread dump. Use when jstack <pid> does not respond (process is hung)
-m to print both java and native frames (mixed mode)
-l long listing. Prints additional information about locks
-h or -help to print this help message
-F 当’jstack [-l] pid’没有响应的时候强制打印栈信息,如果直接jstack无响应时,用于强制jstack,一般情况不需要使用
-l 长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表,会使得JVM停顿得长久得多(可能会差很多倍,比如普通的jstack可能几毫秒和一次GC没区别,加了-l 就是近一秒的时间),-l 建议不要用。一般情况不需要使用
-m 打印java和native c/c++ 框架的所有栈信息.可以打印JVM的堆栈,显示上Native的栈帧,一般应用排查不需要使用
将jstack堆栈信息生成到文件中
- 首先确定当前项目的pid是多少(也就是进程ID),如图所示(也可以使用其他命令查询id,如jps等)

- 通过命令将信息 打入到文件中 jstack 8566 >> /home/test.txt
- 我们再用IBM Thread and Monitor Dump Analyzer for Java这个工具来分析。这里可以清晰的看到线程数状态统计,和每个线程的状态。
关于jstack Dump 日志文件中的线程状态
dump 文件里,值得关注的线程状态有:
- 死锁,Deadlock(重点关注)
- 执行中,Runnable
- 等待资源,Waiting on condition(重点关注)
- 等待获取监视器,Waiting on monitor entry(重点关注)
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 阻塞,Blocked(重点关注)
- 停止,Parked
含义分析如下:
Deadlock:死锁线程
一般指多个线程调用间,进入相互资源占用,导致一直等待无法释放的情况。
Runable:
一般指该线程正在执行状态中,该线程占用了资源,正在处理某个请求,有可能正在传递SQL到数据库执行,有可能在对某个文件进行操作,有可能进行数据类型转换。
Waiting on condition:
等待资源,或等待某个条件的发生。具体原因需结合stacktrace来分析。如果堆栈信息明确是应用代码,则证明该线程正在等待资源。一般是大量读取某资源,且该资源采用了资源锁的情况下,线程进入了等待状态,等待资源的读取。或正在等待其他现场的执行。如果发现有大量的线程都处在Wait on Condition,从线程的stack看,正等待网络读写,这可能是一个网络瓶颈的征兆,是因为网络阻塞导致线程无法执行,一种情况是网络非常忙,几乎消耗了所有带宽,仍然有大量的数据等待网络读写;另一种情况也可能是网络空闲,但由于路由等问题,导致包无法正常的到达。又或者是该线程在sleep,等待sleep的时间到了,将被唤醒
Blocked:线程阻塞
是指当前线程执行过程中,所需要的资源长时间等待却一直未能获取到,被容器的线程管理器表示为阻塞状态,可以理解为等待资源超时的线程。
Waiting for monitor entry 和 in Object.wait():
monitor是java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者Class的锁。每一个对象都有且只有一个monitor。当某个线程期待获得Monitor及对象的锁,而在锁被其他线程拥有的时候,这个线程就会进入Entry Set区域。曾经获得过锁,但是其他必要条件不满足而需要wait的线程就进入了Wait Set区域。
利用IBM Thread and Monitor Dump Analyzer for Java打开刚刚的test日志文件查看,如图所示#
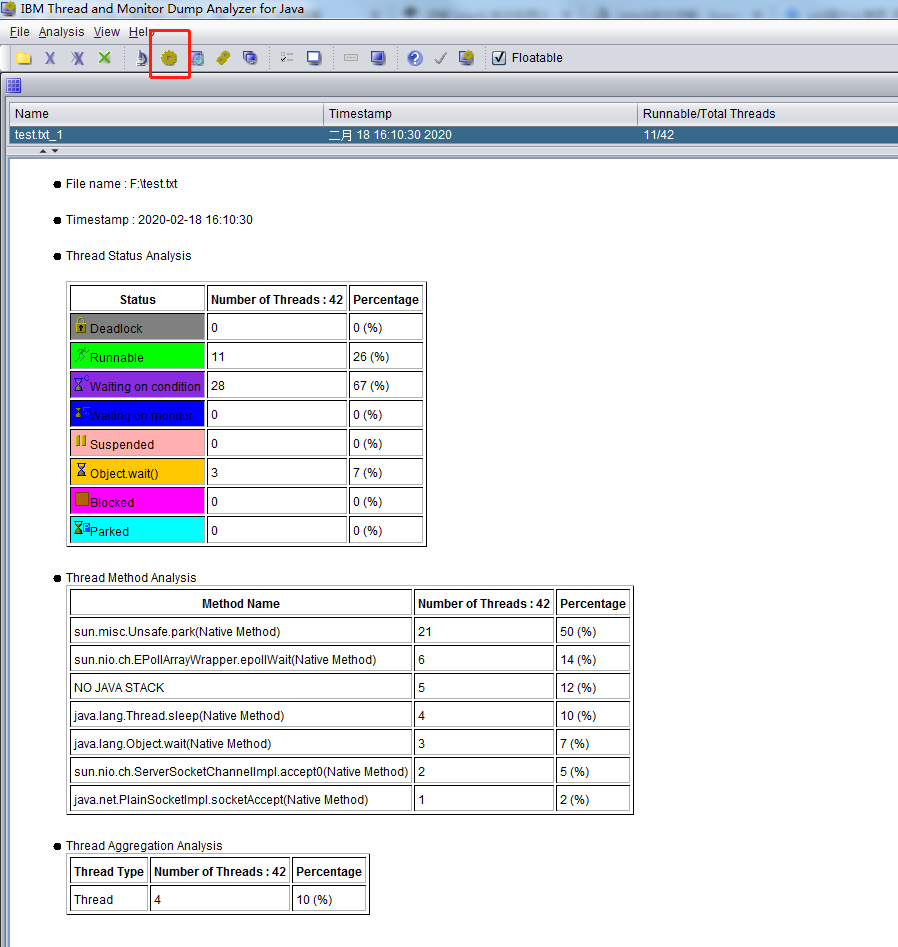
其中线程的详细信息可以点击红框按钮,如图所示: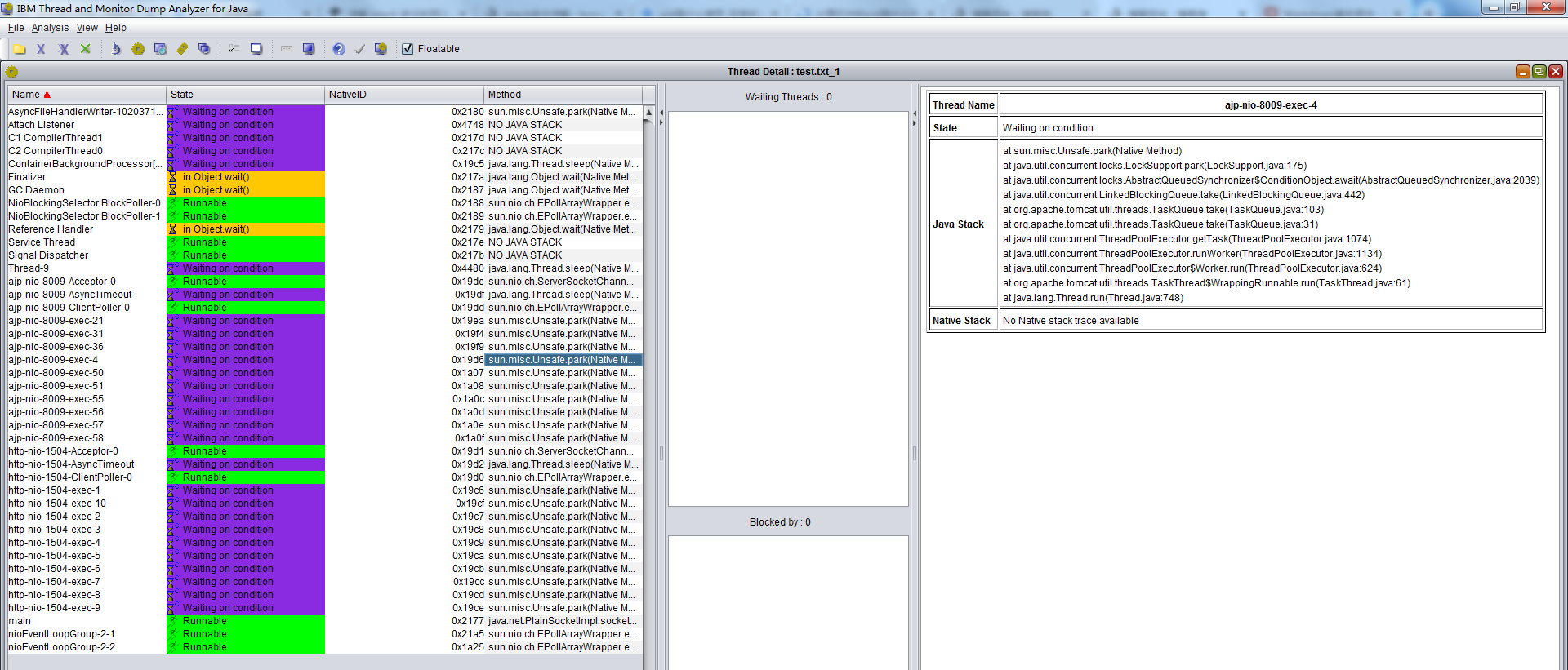
可以根据上文中jstack Dump日志文件中的线程状态中描述值得重点关注的线程状态,查看各个线程是否有异常情况
总结:
- JVM性能相关的6个常用的JDK命令
- jps:查询JVM中的所有进程,找出将要操作的PID,是所有命令的基础
- jstat:查看相应JVM进程的gc、类加载卸载信息,是没有GUI界面查看JVM运行数据的首选
- jinfo:查看和在运行期动态修改JVM配置参数
- jmap:生成堆转储快照和比较占内存的对象
- jhat:配合jmap分析堆转储日志,除非没有其他工具可做这个事儿,否则就不用该工具
- jstack:生成线程快照,定位线程长时间卡顿的原因(线程间死锁、死循环、请求外部资源导致的长时间等待)
- 输出gc信息到控制台
- -XX:+PrintGCDetails:输出GC的详细信息
- -XX:+PrintGCTimeStamps:输出GC的时间信息
- -XX:+PrintGCApplicatonStoppedTime:GC造成的应用暂停的时间
- 输出gc信息到文件
- 以上三个参数在这里依旧适用
- -Xloggc:文件路径/gc.log:输出到文件
第八章 JVM性能监控与故障处理工具
1、图像化的故障处理工具
- Jconsole
- visualVM
2、Jconsole
进入"E:\Java\jdk1.6\bin",双击"jconsole.exe",弹出如下框:
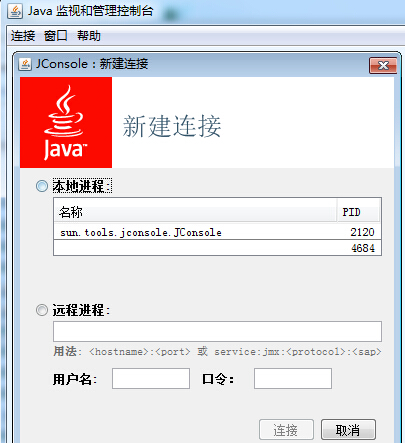
说明:这里列出了所有的JVM进程,一个Jconsole进程,一个eclipse(PID:4684),这相当于jps命令。
选中其中一个PID,假设选中了eclipse,双击,出现下图:(注:之后的各个叶签,都是每4秒刷新一次)
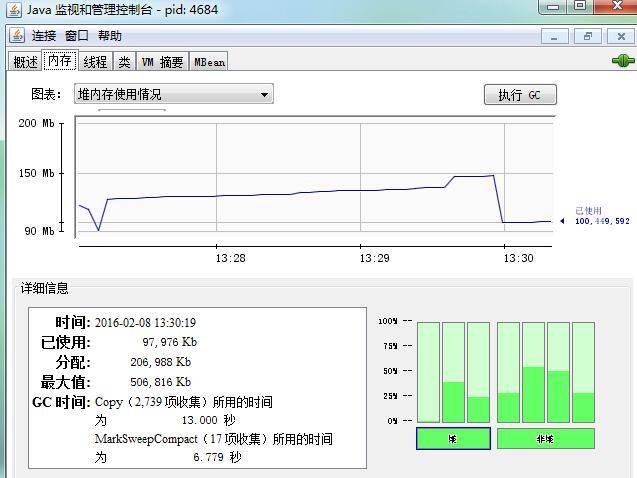
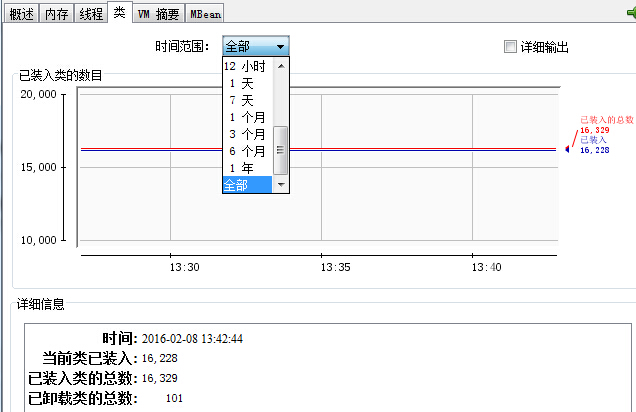
"内存":相当于jstat -gc,在上图中的详细信息部分,该部分对应的信息就是头部图表部分所写的参数(这里是"整个堆"的情况),同时对应的也是右下角部分柱状图所选中的柱子(这里是"堆"),对于"非堆"指的就是"方法区"(或者称为"永久代")。当然,这里也可以选择时间范围来查看相应的信息。
"类":相当于jstat -class,列出了装载类和卸载类的相关信息。
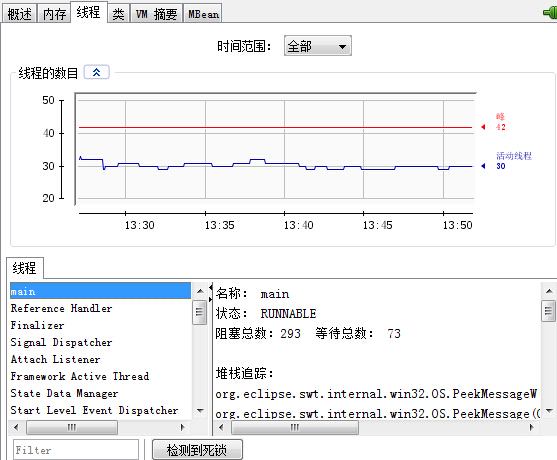
"线程":相当于jstack,折线图显示了线程数目的变化情况,包括峰值线程数量、活动线程数量;左下角展示了所有线程名称。双击相应的线程名称
"VM摘要":相当于jinfo

最后,测试一下线程死锁的现象。代码如下:
1 package thread;
2
3 /**
4 * 测试线程
5 */
6 class XXthread implements Runnable{
7 int a,b;
8
9 public XXthread(int a, int b) {
10 this.a = a;
11 this.b = b;
12 }
13
14 public void run() {
15 synchronized (Integer.valueOf(a)) {
16 synchronized (Integer.valueOf(b)) {
17 System.out.println(a + b);
18 }
19 }
20 }
21 }
22
23 public class TestDeadLockThread {
24 public static void main(String[] args) {
25 for(int i=0;i<100;i++){
26 new Thread(new XXthread(1, 2)).start();
27 new Thread(new XXthread(2, 1)).start();
28 }
29 }
30 }
执行main()方法,之后去查看"线程"标签,点击"检测死锁",如下:


发现线程Thread-95和Thread-106死锁(彼此拥有对方想要的锁)
分析:
1)Integer缓存机制
Integer.valueOf(int xxx),该方法为了减少对象的创建,节省内存,会将xxx转化成的Integer对象缓存起来,之后只要是相同的xxx,那么这个方法都会直接从缓存中取出对象来。假设代码中的Integer.valueOf(1)生成的对象是java.lang.Integer@987197,而Integer.valueOf(2)生成的对象是java.lang.Integer@15e293a,那么之后无论调用多少次Integer.valueOf(1),也无论是哪一个线程去调用该方法,返回的都只是同一个对象java.lang.Integer@987197。也就是说上边的这段代码中的Integer.valueOf(i)只会生成两个不同的对象,就是java.lang.Integer@987197和java.lang.Integer@15e293a,而这两个对象也就是我们的锁对象。
2)死锁发生的时机
假设线程"Thread-95"执行到其第一个synchronized块中时(假设刚刚获取了锁对象java.lang.Integer@987197),这时候CPU时间片切换给了线程"Thread-106",而"Thread-106"执行其第一个synchronized块(获取了锁对象java.lang.Integer@15e293a),之后"Thread-106"要执行第二个synchronized块儿来获取锁对象java.lang.Integer@987197,这时候就获取不到了,因为这个锁对象正被"Thread-95"所持有,于是"Thread-106"就阻塞在java.lang.Integer@987197这个锁对象上,这时,假设CPU时间片又切换给了"Thread-95",该线程要执行第二个synchronized块来获取java.lang.Integer@15e293a,就获取不到了,因为该锁对象已被"Thread-106"所持有
3)结果
"Thread-95"持有锁对象java.lang.Integer@987197,阻塞在锁对象java.lang.Integer@15e293a;
"Thread-106"持有锁对象java.lang.Integer@15e293a,阻塞在锁对象java.lang.Integer@987197
3、visualVM
是一块更加全面的GUI监视工具,包含很多插件(需要自己下载),具体的见《深入理解Java虚拟机(第二版)》
第九章 JVM调优推荐
1、JVM的调优主要是内存的调优,主要调两个方面:
- 各个代的大小
- 垃圾收集器选择
2、各个代的大小
- 常用的调节参数
- -Xmx
- -Xms
- -Xmn
- -XX:SurvivorRatio
- -XX:MaxTenuringThreshold
- -XX:PermSize
- -XX:MaxPermSize
- 原则
- -Xmx==-Xms:防止堆内存频繁进行调整
- -Xmn:通常设为-Xmx/4(这是我在企业中实习时的设置方式,系统运行正常、平稳、速度也快),林昊推荐的是-Xmx/3,所以-Xmn==-Xmx/4~-Xmx/3
- 调节时机:minor GC太频繁
- -Xmn过小:minor GC太频繁;小对象可能也会直接进入年老代,提前导致Full GC
- -Xmn过大:年轻代大了,minor GC的时间变长了;年老代变小了,Full GC会频繁
- 调节策略:若-Xmx可调大,则调大,且保持-Xmn==-Xmx/4~-Xmx/3;若-Xmx不可调大,在保持-Xmn==-Xmx/4~-Xmx/3的范围内增大-Xmn,若-Xmn也不可调了,则试着调大-XX:SurvivorRatio来看看情况
- -XX:SurvivorRatio:默认8
- -XX:SurvivorRatio过大:Eden变大,Survivor变小,minor GC可能减少,但是由于suvivor减小了,所以如果minor GC存活下来的对象大于suvivor,则会直接进入年老代
- -XX:SurvivorRatio过小:Eden变小,Survivor变大,minor GC可能增多,但是由于suvivor变大了,能够存储更多存活下来的对象,进入年老代的对象可能会减少
- -XX:MaxTenuringThreshold:默认为15
- -XX:SurvivorRatio过大:对象在年轻代的存活时间变长,可能在年轻代就被回收掉而不必进入年老代,但是相应的复制的时候survivor区就会被占用更多的空间。
- -XX:SurvivorRatio过大:对象在年轻代的存活时间变短,可能会早早进入年老代而失去在年轻代被回收的机会,但是相应的复制的时候survivor区也就有更多内存了,这样可能会避免部分大对象直接进入年老代
- -XX:MaxPermSize==-XX:PermSize
- 在实际开发中,前台不要使用jsp,使用velocity等模板引擎技术
- 不要引入无关的jar
3、垃圾收集器选择
企业中最常用的两个组合:(这里由于大部分大型企业用的还是JDK1.6,所以G1不说)
关于下边两组垃圾收集器的详细原理见:第五章 JVM垃圾收集器(1)
- Parallel Scavenge/Parallel Old
- 注重吞吐量(吞吐量越大,说明CPU利用率越高)
- 主要用于处理很多的CPU计算任务而用户交互任务较少的情况
- 也用于让JVM自动调优而我们袖手旁观的情况(-XX:+UseParallelOldGC,-XX:GCTimeRatio,-Xmx,-XX:+UseAdaptiveSizePolicy)
- -XX:+UseParallelOldGC:指定使用该组合
- ParNew/CMS
- 注重STW的缩短(该时间越短,用户体验越好,而且会减少部分请求的请求超时问题)
- -XX:+UseConcMarkSweepGC:指定使用该组合
- -XX:CMSInitiatingOccupancyFraction:来指定当年老代空间满了多少后(百分比)进行垃圾回收
- 关于上边两种组合的说明
- 一般而言,在企业中,机器的CPU数量都比较多,且CPU的计算能力也不会成为瓶颈,所以对于CMS的并发标记与并发清除阶段,会占用CPU资源的问题,其实不是大事儿;而对于Parallel的注重吞吐量的问题也就不是什么大事儿了,毕竟CPU是强大的
- 所以,ParNew/CMS是首选(在G1不能用的情况下),Parallel Scavenge/Parallel Old只在想让JVM自动管理内存的情况下使用
注意:在实际调优过程中,可以使用jstat、jconsole、visualVM或GC日志的检测数据来调,具体的示例见《深入理解java虚拟机(第二版)》p142对eclipse运行速度的调优。
关于GC日志的参数含义与每一种垃圾收集器的GC日志的格式,查看《深入理解Java虚拟机(第二版)》的P89和《深入分析java web技术内幕(修订版)》的P224
第十章 常用的JVM参数记录
GC
- -XX:+PrintGC 打印GC日志
- -XX:+PrintGCDetails 打印详细的GC日志
- -Xloggc:/var/gc.log 将GC日志打印在根目录的var文件夹下的gc.log文件中
class
- -verbose:class 打印类加载和卸载信息
堆内存
- -Xmx2048m 最大堆内存
- -Xms2048m 最小堆内存
- -Xmn512m 新生代内存
- -XX:SurvivorRatio 值为eden/from=eden/to
- -XX:+HeapDumpOnOutOfMemoryError 在内存溢出时导出整个堆信息
- -XX:HeapDumpPath=/var/heap.dump 指定导出堆的存放路径
方法区
- -XX:PermSize=50m 方法区大小
- -XX:MaxPermSize=50m 方法区最大大小
Metaspace
- -XX:MaxMetaspaceSize 指定元空间的大小,默认情况下,只受限于系统内存大小
栈
- -Xss1m
直接内存
- -XX:MaxDirectMemorySize 最大可用直接内存,默认最大值为-Xmx,直接内存使用量达到该值时,触发垃圾回收
垃圾回收器
- -XX:UseSerialGC 使用serial/serial old垃圾回收器
- -XX:PrintGCApplicationStoppedTime:查看STW时间
- -XX:UseParNewGC 使用parNew/serial old
- -XX:ParallelGCThreads parNew的GC线程数
Parallel
- -XX:+UseParallelGC 使用Parallel Scavenge/serial Old //TODO
- -XX:+UseParallelOldGC 使用Parallel Scavenge/Parallel Old
- -XX:GCTimeRatio:直接设置吞吐量大小,假设设为19,则允许的最大GC时间占总时间的1/(1+19),默认值为99,即1/(1+99)
- -XX:MaxGCPauseMillis:最大GC停顿时间,该参数并非越小越好
- -XX:+UseAdaptiveSizePolicy:开启该参数,-Xmn/-XX:SurvivorRatio/-XX:PretenureSizeThreshold这些参数就不起作用了,虚拟机会自动收集监控信息,动态调整这些参数以提供最合适的的停顿时间或者最大的吞吐量(GC自适应调节策略),而我们需要设置的就是-Xmx,-XX:+UseParallelOldGC或-XX:GCTimeRatio两个参数就好(当然-Xms也指定上与-Xmx相同就好)
CMS
- -XX:+UseConcMarkSweepGC 使用parNew/CMS
- -XX:CMSInitiatingOccupancyFraction 指定当年老代空间满了多少后进行垃圾回收。默认68,即68%
- -XX:+UseCMSCompactAtFullCollection (默认是开启的)在CMS收集器顶不住要进行FullGC时开启内存碎片整理过程,该过程需要STW
- -XX:CMSFullGCsBeforeCompaction 指定多少次FullGC后才进行整理
- -XX:ParallelCMSThreads 指定CMS回收线程的数量,默认为:(CPU数量+3)/4
- -XX:+CMSPermGenSweepingEnabled与-XX:+CMSClassUnloadingEnabled 使用CMS进行方法区的回收
G1
- -XX:+UseG1GC 使用G1
对象进入年老代
- -XX:MaxTenuringThreshold=15 复制过15次后
- -XX:PretenureSizeThreshold=1000 大于1000字节的对象直接进入年老代
JIT
- -XX:CounterHalfLifeTime 半衰周期
- -XX:CompileThreshold 默认server模式是10000,即在半衰周期内方法调用次数达到10000次,将该方法编译为机器码
- -XX:-UseCounterDecay 关闭上述机制,即半衰周期的无穷大
- -XX:OnStackReplacePercent 用于计算循环体执行的次数,server模式下通过该值算出来的回边数是10700,即循环体执行10700次时便以为机器码
JVM-总结列表的更多相关文章
- 8.JVM技术_JVM参数列表
1.JVM参数列表 通常情况下启动一个Java应用程序就会启动JVM的虚拟机,虚拟机在启动时可以通过java 指令传递参数给JVM. java -Xmx3550m -Xms3550m -Xmn2g - ...
- Tomcat7调优及JVM性能优化for Linux环境
标签: tomcat7 jvm 性能 分享到: 出处:http://www.iteye.com 该优化针对Linux X86_X64环境 1. Tomcat优化其实就是对server.xml优化(开户 ...
- 最近5年183个Java面试问题列表及答案[最全]
Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别(String 类型和 StringBuffer 类型的主要性能区别其实在于 Stri ...
- jvm间歇性崩溃分析
http://www.cnblogs.com/LBSer/p/4417148.html 1 问题描述 某服务有两台机器,每隔几天会报警load高,一开始看监控发现gc时间抖动很大,以为是发生了full ...
- Java JVM技术
.1. java监控工具使用 .1.1. jconsole jconsole是一种集成了上面所有命令功能的可视化工具,可以分析jvm的内存使用情况和线程等信息. 启动jconsole 通 ...
- Java高级特性—JVM
1).java监控工具使用 jconsole是一种集成了上面所有命令功能的可视化工具,可以分析jvm的内存使用情况和线程等信息 visualvm 提供了和jconsole的功能类似,提供了一大堆的插件 ...
- JVM技术部分总结
1.JVM内存模型 1.1 JVM内存模型图解 Java虚拟机在执行Java程序的过程中,会把它所管理的内存划分为若干个不同的数据区.这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程 ...
- java之jvm
1.JVM内存模型 线程独占:栈,本地方法栈,程序计数器线程共享:堆,方法区 回答以上问题是需回答两个要点:1. 各部分功能2. 是否是线程共享 2.JMM与内存可见性JMM是定义程序中变量的访问规则 ...
- 转 最近5年183个Java面试问题列表及答案[最全]
Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别(String 类型和 StringBuffer 类型的主要性能区别其实在于 Stri ...
- JVM参数概述
标准参数(-) 所有的JVM实现都必须实现这些参数的功能,而且向后兼容. 通过命令 java 查看如下: 用法: java [-options] class [args...] (执行类) 或 jav ...
随机推荐
- Issac_GYM对Go2机器人的仿真心得
override 覆盖 torques 扭矩 1 args()参数信息等 cd /home/yyds/桌面/Gym2/legged_robot_competition-master/legged_gy ...
- Xor-FWT 的另一种理解方式
Xor-FWT 的另一种理解方式 学习 \(\text{Fennec's Algorithm}\) 的额外收获,顺手记录一下. 假设我们要求两个长度为 \(n\) 的数组的异或卷积,为方便起见令 \( ...
- 多进程可以共享内存,那么多进程是否可以共享显存呢?(CPU->内存,GPU->显存)
多进程可以共享内存,那么多进程是否可以共享显存呢?(CPU->内存,GPU->显存) 答案:不能.多进程可以共享内存,但是多进程不能共享显存(NVIDIA GPU 显存不能被多进程共享). ...
- PicGo+CloudFire搭建免费图床
目录 CloudFire对象存储 创建bucket 配置域名 配置 Bucket 访问 API PicGO配置 参考博客 CloudFire对象存储 | CloudFire提供对象存储服务,每个月有1 ...
- Nuxt.js 应用中的 vite:extend 事件钩子详解
title: Nuxt.js 应用中的 vite:extend 事件钩子详解 date: 2024/11/11 updated: 2024/11/11 author: cmdragon excerpt ...
- .NET9 - 新功能体验(三)
书接上回,我们继续来聊聊.NET9和C#13带来的新变化. 01.Linq新方法 CountBy 和 AggregateBy 引入了新的方法 CountBy 和 AggregateBy后,可以在不经过 ...
- NetBox使用教程1-组织架构
前言 本教程用于学习NetBox的基础使用,练习可使用官方Demo:https://demo.netbox.dev/ NetBox 使用教程系列:https://songxwn.com/tags/ne ...
- Impala学习--Impala概述,Impala系统架构
Imapla概述 Impala是Cloudera公司的一个实时海量查询产品.是对于已有Hive产品的补充.Impala采用了和Hive相同的类SQL接口,但并没有采用MapRed框架执行任务,而是采用 ...
- JUC.Condition学习笔记
目录 Condition的概念 大体实现流程 I.初始化状态 II.await()*作 III.signal()*作 3个主要方法 Condition的数据结构 线程何时阻塞和释放 await()方法 ...
- js逆向之常用算法
[Python] encode & decode from urllib import parse # url进行编码与解码 url = '你好啊' url_encode = parse.qu ...