spring ai 函数调用
1.概要
我们使用AI大模型开发程序时,比如我需要查一下平台中有多少个客户。这个时候大模型肯定时不知道的,如果大模型不知道,他可能会回答不知道或者胡乱回答,这个时候就需要借助函数时调用来解决这些问题。
大模型胡乱回答实际是大模型幻觉的问题,解决幻觉问题有以下方案
- 模型微调
这种情况一般公司不用做,因为需要自己训练,费用比较贵效果不一定好。 - 检索增强生成 (RAG)
- 使用外部的知识库,作为大模型知识的来源
- 使用向量的相似性查找相关文档
- 相关的文档作为大模型的一部分
- 方法调用 (function calling)
- 将问题和函数作为问题一起发给大模型
- 大模型解析出函数的参数
- 应用调用函数返回结果
- 将结果和上下文的数据丢给大模型,由大模型返回结果
2.函数调用过程
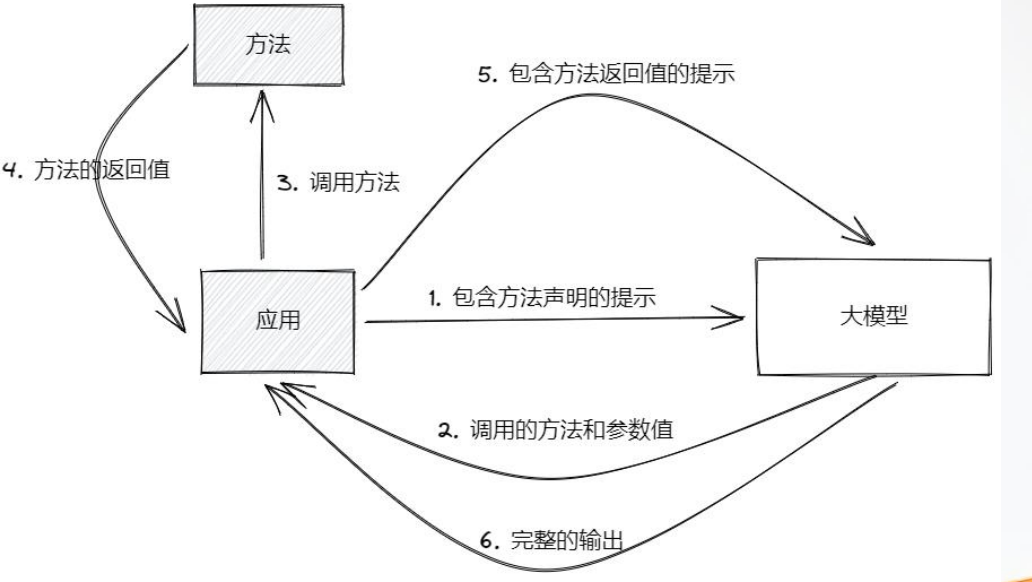
- 应用构造用户的问题和我们定义的函数的信息提交给大模型。
请求信息
{
"model": "qwen-plus",
"input": {
"messages": [
{
"role": "user",
"content": "广州有多少叫张三的人"
}
]
},
"parameters": {
"temperature": 0,
"result_format": "message",
"tools": [
{
"function": {
"name": "add",
"description": "add two numbers",
"parameters": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"v1": {
"type": "integer",
"format": "int32"
},
"v2": {
"type": "integer",
"format": "int32"
}
}
}
},
"type": "function"
},
{
"function": {
"name": "loation",
"description": "某地区有多少叫什么名字的人",
"parameters": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"address": {
"type": "string"
},
"name": {
"type": "string"
}
}
}
},
"type": "function"
}
]
}
}
我们将问题和配置的函数一起发给大模型,如果大模型判断当前的问题是否需要调用函数,它会返回是否需要函数调用,并同时计算出函数的参数。
- 大模型解析出是否需要调用函数,如果不需要则直接返回
{
"choices": [
{
"finish_reason": "tool_calls",
"message": {
"role": "assistant",
"tool_calls": [
{
"function": {
"name": "loation",
"arguments": "{\"address\": \"广州\", \"name\": \"张三\"}"
},
"id": "",
"type": "function"
}
],
"content": ""
}
}
]
}
- 如果需要 那么应用则调用函数。
spring ai 框架会去调用函数,获取函数名和参数,调用我们定义的参数。 - 函数返回结果,并将返回结果组成提示词再次发给大模型
- 大模型获取数据后得到完整的输出。
3.主要代码如下
3.1 定义函数
public class LocationFunction implements Function<LocationRequest, LocationResponse> {
private final Logger LOGGER = LoggerFactory.getLogger(getClass());
@Override
public LocationResponse apply(LocationRequest locationRequest) {
LOGGER.info("调用某个地方有多少叫什么的人 {}", locationRequest);
int amount=10;
if(locationRequest.name().equals("张三")){
amount=5;
}
return new LocationResponse(amount);
}
}
请求参数定义
public record LocationRequest(String name, String address) {
}
返回数据定义
public record LocationResponse (int amount){
}
配置函数
@Bean
@Description("某地区有多少叫什么名字的人")
public Function<LocationRequest, LocationResponse> loation() {
return new LocationFunction();
}
定义 chatclient
@Bean
public ChatClient chatClient(
FunctionCallbackContext functionCallbackContext) {
return new DashscopeChatClient(new DashscopeApi(),
DashscopeChatOptions.builder()
//使用千问plus 数据
.withModel(DashscopeModelName.QWEN_PLUS)
.withTemperature(0.0f)
//定义函数
.withFunction("add")
//定义第二个函数
.withFunction("loation")
.build(),
functionCallbackContext);
}
这里我们可以定义多个函数,但是还是不要定义太多的函数,这样发送给大模型的包太大,会需要消耗更多的token ,会影响大模型收费。
spring ai 函数调用的更多相关文章
- 完全自制的五子棋人机对战游戏(VC++实现)
五子棋工作文档 1说明: 这个程序在创建初期的时候是有一个写的比较乱的文档的,但是很可惜回学校的时候没有带回来……所以现在赶紧整理一下,不然再过一段时间就忘干净了. 最初这个程序是受老同学所托做的,一 ...
- Spring AOP详解
一.前言 在以前的项目中,很少去关注spring aop的具体实现与理论,只是简单了解了一下什么是aop具体怎么用,看到了一篇博文写得还不错,就转载来学习一下,博文地址:http://www.cnbl ...
- Artificial intelligence(AI)
ORM: https://github.com/sunkaixuan/SqlSugar 微软DEMO: https://github.com/Microsoft/BotBuilder 注册KEY:ht ...
- spring的AOP
最近公司项目中需要添加一个日志记录功能,就是可以清楚的看到谁在什么时间做了什么事情,因为项目已经运行很长时间,这个最初没有开来进来,所以就用spring的面向切面编程来实现这个功能.在做的时候对spr ...
- JPA in Spring
JPA(Java Persistence API):Sun官方提出的Java持久化规范,定义了对象-关系映射(ORM)以及实体对象持久化的标准接口.Sun引入JPA出于两个原因:一.简化现有Java ...
- Spring Bean
一.Spring的几大模块:Data access & Integration.Transcation.Instrumentation.Core Spring Container.Testin ...
- 非Spring下的Quartz
转自:Nick Huang. http://www.cnblogs.com/nick-huang/ 阅读目录 > 参考的优秀资料 > 版本说明 > 简单的搭建 > 在We ...
- Spring AOP在函数接口调用性能分析及其日志处理方面的应用
面向切面编程可以实现在不修改原来代码的情况下,增加我们所需的业务处理逻辑,比如:添加日志.本文AOP实例是基于Aspect Around注解实现的,我们需要在调用API函数的时候,统计函数调用的具体信 ...
- Struts2、Spring MVC4 框架下的ajax统一异常处理
本文算是struts2 异常处理3板斧.spring mvc4:异常处理 后续篇章,普通页面出错后可以跳到统一的错误处理页面,但是ajax就不行了,ajax的本意就是不让当前页面发生跳转,仅局部刷新, ...
- 【五子棋AI循序渐进】——开局库
首先,对前面几篇当中未修复的BUG致歉,在使用代码时请万分小心…………尤其是前面关于VCF\VCT的一些代码和思考,有一些错误.虽然现在基本都修正了,但是我的程序还没有经过非常大量的对局,在这之前,不 ...
随机推荐
- manim边学边做--通用多边形
manim提供了通用多边形模块,可以绘制任意的多边形. 通用多边形模块有两种,Polygon和Polygram. Polygon是一个几何学术语,主要指的是由三条或三条以上的线段首尾顺次连接所组成的平 ...
- Angular 18+ 高级教程 – Animation 动画
前言 Angular 有一套 built-in 的 Animation 方案.这套方案的底层实现是基于游览器原生的 Web Animation API. CSS Transition -> CS ...
- JavaScript – Sort
前言 排序是很常见的需求. 虽然看似简单, 但其实暗藏杀机. 一不小心就会搞出 Bug 哦. 这篇就来聊聊 JS 的排序. 参考 原生JS数组sort()排序方法内部原理探究 值的比较 js中的loc ...
- ASP.NET Core – Thread, Task, Async 线程与异步编程
前言 平常写业务代码, 很少会写到多线程. 久了很多东西都忘光光了. 刚好最近在复习 RxJS. 有一篇是讲 scheduler 的. 会讲到 JavaScript 异步相关的资讯. 既然如此那就一次 ...
- CSS & JS Effect – Show More
效果 show more 是很常被使用的效果, 因为空间总是不够的丫. 比起 scroll, show more 的体验通常会好一些, 尤其在手机, 它有更好的引导. 实现思路 1. 卡片需要一个 ...
- Java 之跨docker容器备份数据库
Java 之跨docker容器备份数据库 摘] java中执行数据库备份,每隔10分钟备份一次,保留四份备份文件,项目在windows系统下运行备份命令没问题.项目采用docker部署后,jar部署在 ...
- Servlet——Request请求转发
Request请求转发 特点:
- Unity中的光源类型(向前渲染路径进行光照计算)
Unity中的光源类型 Unity中共支持4种光源类型: 平行光 点光源 聚光灯 面光源(在光照烘焙时才可以发挥作用) 光源的属性: 位置 方向(到某个点的方向) 颜色 强度 衰减(到某个点的衰减) ...
- [The Trellor] Chapter 1
翻译软件真的翻不好,读英文小说要相信你的脑子. There's only one thing to do in Berlen - that is listening the sound of wind ...
- Hive--hbase--spark
hive创建hbase表 create external table events.hb_train( row_key string, user_id string, event_id string, ...