2025dsfz集训Day7: KMP与Trie树
Day7: KMP与Trie树
\]
特别感谢 此次课的主讲 - Kwling
KMP算法
- \(KMP (Knuth–Morris–Pratt)\) 是一个字符串匹配算法,于1977年由上述三人共同发表。
在线性的时空复杂度内解决字符串匹配。
字符串匹配
给定两个字符串 \(s,t\)(通常来讲我们管较短的串叫做“模式串”,长的叫“匹配串”。我们的任务是在长串内找到短串)。
我们定义记号 \(s[l,r]\) 表示的是 \(s\) 串,从下标 \(l\) 到下标 \(r\) 的子串。(比如说 \(s=“abcabca”\),那么 \(s[2,4]=“bca”,1-index\))
字符串匹配:我们希望对于 s(长串)的每一个前缀 s[1,i],找到最大的 j 使得 s[i-j+1,i]=t[1,j]
例:\(s=“ababc”,t=“aba”:\)
\(i=1: s[1,1]=t[1,1]=“a” ; i=2:\) \(s[1,2]=t[1,2]=“ab”\)
\(i=3: s[1,3]=t[1,3]=“abc”\)(成功匹配); \(i=4: s[3,4]=t[1,2]=“ab”\)
\(i=5: s[6,5]=t[1,0]=\phi\) (未成功匹配,空串)
解法
- 我们希望能够复用尽量多的信息。
- 假设我们此时知道 \(s[1,i]\) 对应的匹配长度 \(k_i\),怎么求出 \(s[1,i+1]\) 的匹配长度?
- 大致思路:先看看 \(s[i+1]\) 和 \(t[k_i+1]\) 一不一样。
- 一样:长度++
- 不一样:模式串前移 \(1\) 位
Border串
我们注意到,实际上我们是在找 \(t[1,j]\) 的一个既是其前缀又是其后缀的最长的子串。(当然需要不是 \(t[1,j]\) 本身)
\(s=“abab”\) 那么 \(s[1,2]=“ab”\) 就是这样的串。
即是前缀又是后缀串的名字是:\(border\) 串。我们可以发现 \(border\) 集合:\(S_i=S_k+{k}\) ( \(k\) 是 \(t[1,i]\) 的最长border)。
- 例:\(BS(“ababa”)={“a”,“aba”}=BS(“aba”)+{“aba”}\)
其中 \(BS\) 是 \(border\ set\) 的意思(即所有的 \(border\) 串构成的集合)
- 例:\(BS(“ababa”)={“a”,“aba”}=BS(“aba”)+{“aba”}\)
这实际上也就是说:\(border\) 集合实际上是一条链
我们不断地去找串 \(S\) 的最长 \(border T\),然后把他加入集合,把 \(S\) 变成 \(T\) 直到 \(S\) 为空。
现在问题变为:如何求出最长 \(border\)?
假设我们知道了 \(s[1,i]\) 的 \(border\),怎么求出 \(s[1,i+1]\) 的 \(border\) 长度?
我们不断地“跳” \(t[1,i]\) 的 \(border\) 来找到 \(t[1,i+1]\) 的 最长 \(border\)。
复杂度
看起来是 \(O(n^2)\) 的,但实则不然。
考虑每次最多让 \(border\) 链 变长 \(1\) ,以 \(border\) 链 长度作为“势能”,便可以分析出 \(O(n)\) 的摊还复杂度。
另一边的字符串匹配亦是同理。(算法,复杂度分析)
假设 \(s[i-j+1,i]\) 匹配到了 \(t[1,j]\)。
- 我们不断地去 “跳” \(t[1,j]\) 的 \(border\),找到一个 \(t[1,k]\) 使得 \(t[k+1]=s[i+1]\)。
- 这样就完成了一次字符串匹配。
我们不难分析出,字符串匹配的复杂度为:\(O(n+m)=O(|S|+|T|)\)
不难发现,实际上 border 集合的结构,可以用一颗树来描述。
以 S=“abababa” 举例。
- \(S[1,1]\) 对应最长 \(border=\phi;\)
- \(S[1,2]\) 对应最长 \(border=\phi 。\)
- \(S[1,3]\) 对应最长 \(border=“a”;\)
- \(S[1,4]\) 对应最长 \(border=“ab”。\)
- \(S[1,5]\) 对应最长 $border=“aba”; $
- \(S[1,6]\) 对应最长 \(border=“abab”。\)
- \(S[1,7]\) 对应最长 \(border=“ababa”。\)
如图,这棵树具有很优良的性质。
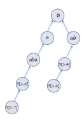
可以发现,我们求解border的算法实际上不过是在 这棵树上进行 dfs。
Trie树
- 我们有这样一个“数据结构”能够去“维护”给定的“串集合” \(S\)。并且能支持“查询”一个串在不在这个“串集合” \(S\) 中。(¥S$ 即为字典)
- 很好理解,如图所示:假设字典 \(S={“she”,“he”,“shy”,“sheep”,“sheet”}\)
- 那么字典树将如图所示:
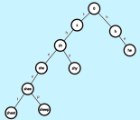
- 每一条边对应一个字母,每一个结点对应一个单词的前缀。
- \(0\) 结点的含义是空串。
- 那么字典树将如图所示:
- 查询就是从 \(0\) 开始查找有没有对应字母的出边。
01Trie树
- \(0-1\)字典树可以很方便的维护形如“最大异或值”这类位运算查询。
- 我们将一个 \(32/64\) 位整数看成一个长为 \(32/64\) 的字符串。
- 例: \(4=(0…0100), 6=(0…0110), 11=(0…01011)\),将他们插入 \(trie\) 中:
- 特点:所有叶子等深。
- 假如我们想查询 \(x\) 与集合里的数最大异或值。
- 比如说 $x=8=(1000) $,我们从高往低按位考虑。
- 在 \(root\) 处的出边是 \(1\),我们看 \(root\) 有无 \(0\) 的出边,
- 然后走向“结点 \(0\)”。(这样才能让异或值最大)
- 接下来同理,我们在“结点 \(0\)” 看有没有 \(1\) 的出边……

题目&参考解法
- AccodersP2076 剪花布条
思路: \(KMP\) 板子
#include<bits/stdc++.h>
using namespace std;
int nextl[1001]={0};//这个数组名不能直接用next,容易报错
string a,b;
int KMP(){
int i=0,j=0,we=0;
int as=a.size(),bs=b.size();
while(i<as){
if(a[i]==b[j]||j==-1){//当单个字符匹配成功或前面没东西
i++;
j++;//i,j都往前挪
if(j==bs){//字符串匹配成功
we++;
j=0;//子串归0
}
}else{
j=nextl[j];//上next数组,移动到下一个位置
}
}
return we;
}
void Next(){//计算next数组值
int bs=b.size();
nextl[0]=-1;//代表前面没东西
int j=0,k=-1;
while(j<bs){
if(k==-1||b[j]==b[k]){//当前面没有东西或j、k对应的字符一样
nextl[j++]=k++;//直接往后挪一位,因为前几位字符=后几位字符或前面啥也没有
}else{
k=nextl[k];
}
}
}
int main(){
while(cin>>a){
if(a=="#"){
break;
}else{
cin>>b;
Next();
cout<<KMP()<<endl;
}
}
}
2025dsfz集训Day7: KMP与Trie树的更多相关文章
- 字符串算法--$\mathcal{KMP,Trie}$树
\(\mathcal{KMP算法}\) 实际上,完全没必要从\(S\)的每一个字符开始,暴力穷举每一种情况,\(Knuth.Morris\)和\(Pratt\)对该算法进行了改进,称为KMP算法. 而 ...
- 字符串 --- KMP Eentend-Kmp 自动机 trie图 trie树 后缀树 后缀数组
涉及到字符串的问题,无外乎这样一些算法和数据结构:自动机 KMP算法 Extend-KMP 后缀树 后缀数组 trie树 trie图及其应用.当然这些都是比较高级的数据结构和算法,而这里面最常用和最熟 ...
- POJ3376 Finding Palindromes —— 扩展KMP + Trie树
题目链接:https://vjudge.net/problem/POJ-3376 Finding Palindromes Time Limit: 10000MS Memory Limit: 262 ...
- [知识点]Trie树和AC自动机
// 此博文为迁移而来,写于2015年5月27日,不代表本人现在的观点与看法.原始地址:http://blog.sina.com.cn/s/blog_6022c4720102w1s8.html 1.前 ...
- 「2017 山东三轮集训 Day7 解题报告
「2017 山东三轮集训 Day7」Easy 练习一下动态点分 每个点开一个线段树维护子树到它的距离 然后随便查询一下就可以了 注意线段树开大点... Code: #include <cstdi ...
- AC自动机——1 Trie树(字典树)介绍
AC自动机——1 Trie树(字典树)介绍 2013年10月15日 23:56:45 阅读数:2375 之前,我们介绍了Kmp算法,其实,他就是一种单模式匹配.当要检查一篇文章中是否有某些敏感词,这其 ...
- 从Trie树(字典树)谈到后缀树
转:http://blog.csdn.net/v_july_v/article/details/6897097 引言 常关注本blog的读者朋友想必看过此篇文章:从B树.B+树.B*树谈到R 树,这次 ...
- 算法笔记--字典树(trie 树)&& ac自动机 && 可持久化trie
字典树 简介:字典树,又称单词查找树,Trie树,是一种树形结构,是哈希树的变种. 优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较. 性质:根节点不包含字符,除根节点外每一个 ...
- 2017 山东二轮集训 Day7 国王
2017 山东二轮集训 Day7 国王 题目大意 给定一棵树,每个点有黑白两种颜色,定义一条简单路径合法当且仅当路径上所有点黑色与白色数量相等,求有多少非空区间 \([L,R]\) ,使得所有编号 \ ...
- hiho一下 第二周&第四周:从Trie树到Trie图
hihocoder #1014 题目地址:http://hihocoder.com/problemset/problem/1014 hihocoder #1036 题目地址: http://hihoc ...
随机推荐
- SOUI4.0发布
4.0在3.x基础上将核心对象全部COM接口化,支持C语言调用SOUI. GIT仓库: gitee: https://gitee.com/setoutsoft/soui4 github: https: ...
- 浅谈Redis的三种集群策略及应用场景
本文分享自天翼云开发者社区<浅谈Redis的三种集群策略及应用场景>,作者:段林 Redis提供了三种集群策略: 1.主从模式:这种模式⽐较简单,主库可以读写,并且会和从库进⾏数据同步,这 ...
- 云电脑Win7系统安装报错详解:问题与解决方案
本文分享自天翼云开发者社区<云电脑Win7系统安装报错详解:问题与解决方案>,作者:每日知识小分享 随着云计算技术的快速发展,越来越多的人开始使用云电脑.然而,在为云电脑安装Win7系统时 ...
- 聊聊GRPO算法——从Open R1来看如何训练DeepSeek R1模型
概述 首发自个人公众号:阿郎小哥的随笔驿站 DeepSeek R1系列建议阅读之前的系列文章: 聊聊DeepSeek R1的一些总结 聊聊DeepSeek R1的开源复现库--Open R1之合成数据 ...
- Q:Tomcat使用的jdk版本而不依赖环境变量
1)在tomcat中显式配置-JVM启动使用内存大小 解决:vim打开tomcat目录下的bin/catalina.sh文件,在文件最上部配置JAVA_OPTS属性. windows下在catalin ...
- mac 安装vue
1.git clone https://github.com/vuejs/vue-devtools.git 切换master分支 cd vue-devtools npm install --regis ...
- npm i 下载太慢
1.在项目内部进入终端 2.输入:npm config set registry https://registry.npmmirror.com 修改npm下载地址为淘宝 3.然后再执行 npm i 进 ...
- 1 前端知识学习-初始Web和Web标准
0️⃣ 初始Web和Web标准 Web Web(World Wide Web) 即全球广域网.也成为万维网.我们常说的Web端就是网页端. 网页 网页是构成网站的基本元素.网页主要由文字.图像 ...
- Vue 页面批量导入其他组件
<template> <div> <template v-for="(item) in names"> <component :is=&q ...
- mySql跳过行数获取多少行
LIMIT :需要获取多少条记录 OFFSET :跳过前面的多少行记录从后面开始获取 SELECT * FROM USER LIMIT 32 OFFSET 1 只获取12行记录 跳过第一条记录 SEL ...