微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache
开篇介绍
先简单的演示一下使用 Lookup 组件实现一个简单示例 - 从数据源表 A 中导出数据到目标数据表 B,如果 A 数据在 B 中不存在就插入新数据到B,如果存在就更新B 和 A 表数据保持统一。
随后再来解释在这个过程中使用到的一些术语,以及分析一下 Lookup 中出现的几种缓存模式,各自的特点以及常用的场合。
案例讲解
两张表,一张是目标表 DEMO_LK_Customer,一张是 DEMO_LK_LegacyCustomer 旧系统表。我们可以理解我们这个示例要实现的目标是 DEMO_LK_Customer 表的数据要和DEMO_LK_LegacyCustomer 实现同步,保持一致。
USE BIWORK_SSIS
GO -- Look up demo table
IF OBJECT_ID('DEMO_LK_Customer','U') IS NOT NULL
DROP TABLE DEMO_LK_Customer
GO IF OBJECT_ID('DEMO_LK_LegacyCustomer','U') IS NOT NULL
DROP TABLE DEMO_LK_LegacyCustomer
GO CREATE TABLE DEMO_LK_Customer
(
CustomerID INT PRIMARY KEY,
CustomerCompany NVARCHAR(255),
CustomerName NVARCHAR(20),
CustomerAddress NVARCHAR(255)
) CREATE TABLE DEMO_LK_LegacyCustomer
(
CustomerID INT PRIMARY KEY,
CustomerCompany NVARCHAR(255),
ContactName NVARCHAR(20),
ContactTitle NVARCHAR(50),
CustomerAddress NVARCHAR(255)
) INSERT INTO DEMO_LK_Customer VALUES
(1,'HFBZG','Allen,Michael','Obere Str. 0123'),
(2,'MLTDN','Hassall, Mark','Avda. de la Constitución 5678'),
(3,'KBUDE','Peoples, John','Mataderos 1000') INSERT INTO DEMO_LK_LegacyCustomer VALUES
(1,'NRZBB','Allen,Michael','Sales Representative','Obere Str. 0123'),
(2,'MLTDN','Hassall, Mark','Owner','Avda. de la Constitución 5678'),
(3,'KBUDE','Peoples, John','Owner','Mataderos 7890'),
(4,'HFBZG','Arndt, Torsten','Sales Representative','7890 Hanover Sq.'),
(5,'HGVLZ','Higginbotham, Tom','Order Administrator','Berguvsvägen 5678') SELECT * FROM DEMO_LK_Customer
SELECT * FROM DEMO_LK_LegacyCustomer --UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ? --UPDATE DEMO_LK_Customer SET CustomerName = ? WHERE CustomerID = ? --UPDATE DEMO_LK_Customer SET CustomerAddress = ? WHERE CustomerID = ?
在测试数据中,我们认为两张表的 ID 都是不变的唯一的,第1条数据和第3条数据不一致,第4条和第5条数据在目标表中不存在。
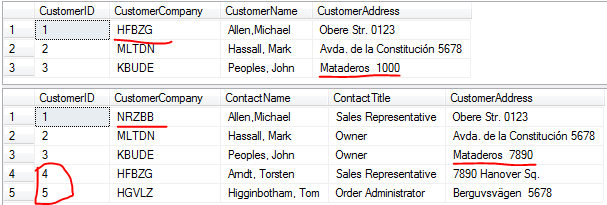
先看一下实现这个例子的 SSIS Package 结构,最外面的是一个数据流 DF_Lookup。

在数据流中,数据源 OLE_SRC_LegacyCustomer 在这个例子中使用的是 SQL Server 数据库表,但是这个数据源也可以是文本文件,Excel 或者其它数据库的表或者查询的结果集。
这个数据源相对于 Lookup 组件 LKP_Customer 来说是 Lookup 组件的输入项。
LKP_Customer 之后有两个分支 - 匹配和不匹配分支,做的事情就是匹配的数据做更新,不匹配的数据做插入动作。
输入源 OLE_SRC_LegacyCustomer 的配置

输入源中要向下输出的列 - 相对于 Lookup 组件,它的输出是 Lookup 的输入。

LKP_Customer 的缓存模式选择的是默认模式 - Full Cache 完全缓存,连接类型 OLE DB Connection 。

从上一个组件中输出的列即这里的数据源 Input 要到下面展示的表或者视图 DEMO_LK_Customer 中查找匹配项,下面的 DEMO_LK_Customer 在Lookup 组件中被称为 - Reference Table/Set 引用表/引用集,前面默认的 Full Cache 缓存的就是这里的 Reference Table - DEMO_LK_Customer。

解释一下这个关联和配置的含义 -
左边 Available Input Columns 来源于 Input 即数据源中输出的列,这些列会作为 Lookup 组件继续向下一个组件输出的列。
Available Lookup Columns 来源于 Reference table 即在缓存中的数据,已选中的 CustomerID 也会作为 Lookup 组件继续向下一个组件输出的列。
中间的黑色实心线描述了查询时的关联规则,以左边为驱动表到右边缓存表中查找 CustomerID 一致的数据,找到了则匹配成功,找不到则不匹配。

设置了如果不匹配则输出不匹配的选项,因此在 Lookup 组件之后能看到 Lookup Match Output 和 Lookup No Match Output 选项。
我们要把匹配的 CustomerID, 将 Input 作为源,将 Reference Table 作为目标表,将 CustomerID 匹配的其它列的数据更新到目标表中。
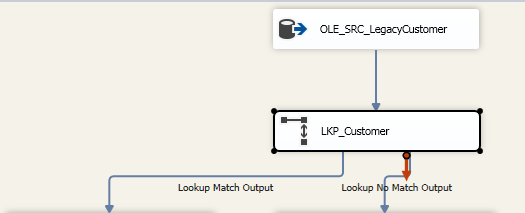
添加组件 OLE_Command 来更新 DEMO_LK_Customer 目标表,选择的是 Lookup Match Output -
UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ?

设置参数,这里就能看到有两个 CustomerID,一个是来源于 Input 的 CustomerID,一个则是上一个数据源中 OLE_SRC_LegacyCustomer 的 CustomerID,这里随便制定哪一个 CustomerID 都可以。

添加一个新组件 OLE DB Destination 连接的是 Lookup NO Match Output,并设置 DEMO_LK_Customer 为目标表,表示如果不匹配则添加新数据。

输入输出的 Mapping 关系。

执行 Package,看到从数据源中向下输出 5 条数据,其中有 3 条数据与 Reference Table 通过 CustomerID 匹配上,因此根据 CustomerID 将最新的从 Input 中输出的信息更新到已存在的目标表中。另外两条不匹配,则添加到目标表中。
注意这里提到的几个表虽然有的是同一张表,但是它们的角色是不一样的 -
- OLE_SRC_LegacuCustomer 中的表 DEMO_LK_LegacyCustomer - 作为 Lookup 组件 LKP_Customer 中的输入源,被称为 Input Table。
- LKP_Customer 中引用的表 DEMO_LK_Customer 在 Lookup 组件中被称为 Reference Table。
- OLE_CMD_UpdateCustomer 和 OLE_DST_InsertNewCustomer 中出现的表 DEMO_LK_Customer 是目标表。

对于一下最后源表和目标表的数据,保持了同步,前提就是 CustomerID 在两张表中都能够唯一确定一条数据。在数据仓库的设计中,也会设计一个 Key 能够唯一确定业务系统和数据仓库中的一条数据,使它们能够在逻辑上能够关联起来。

但是这里有一个问题,就是第2条数据没有变化,但是也会执行一次 Update 操作,可以看上面的例子中,Update 操作显示的是3条数据输入了。如果数据量比较多的情况下,像这样的 Update 是没有必要的。
因此下面要对这个例子进行一个简单的改造,假设只有 CustomerCompany 和 CustomerAddress 会不一致的情况下,可以如何处理来避免无谓的更新操作。
我的改造是在查找匹配之后,添加一个组件 Conditional Split - CS_CheckValues 对输出列做一个判断,只在 CustomerCompany 和 CustomerAddress 不一致的情况下做出更新。
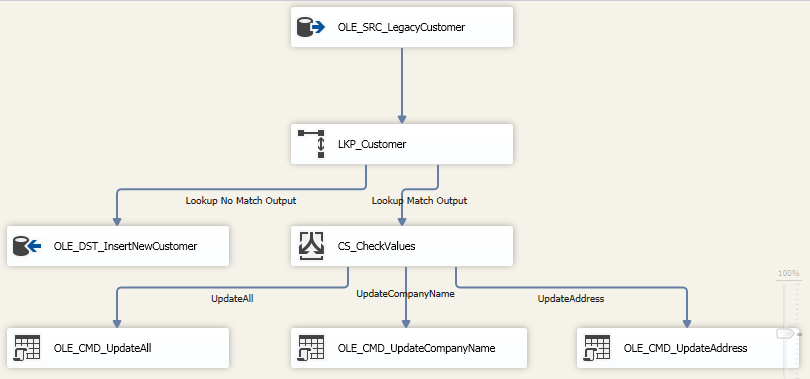
并且在 Lookup 组件中做出修改,因为要比较 Input table 和 Reference table 的两个列,因此选中右边的几个列。

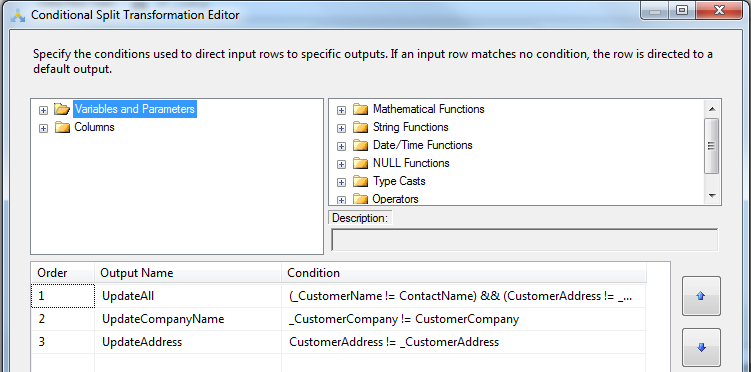
检查的规则有3个,当两个列都不一致的时候,到某一个列不一致的时候,并且也应该按照这种顺序来确保第一种规则应该最先检查。
(_CustomerName != ContactName) && (CustomerAddress != _CustomerAddress) && (CustomerCompany != _CustomerCompany)
_CustomerCompany != CustomerCompany
CustomerAddress != _CustomerAddress
最后添加相应的组件按照不同的规则执行对应的更新语句 -
--UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ?
--UPDATE DEMO_LK_Customer SET CustomerName = ? WHERE CustomerID = ?
--UPDATE DEMO_LK_Customer SET CustomerAddress = ? WHERE CustomerID = ?
再次执行这个 Package 的时候就能看到更新的时候只有两条数据更新了,这样就避免了不必要的全部更新。

这个例子往小了说就是一个表到另外一个表根据那些列然后关联查询出一些列合并或者不合并输出,往大了说可以想象一下更多的场景。比如数据源是一个或者一批文件,Excel,需要定期将文件或者Excel中的数据同步更新到一个数据表中。比如将业务系统中的表数据更新到数据仓库中,更新一下数据仓库中的一些维度属性或者事实数据(事实数据一般很少更新),或者添加一些新的事实数据。所以,Lookup 的使用在 SSIS 中相当于大多数组件来说使用的频率还是比较高的。虽然,它的某些功能实现完全可以用其它的组件或者逻辑来代替,甚至直接使用 SQL 语句。但是某些时候,我们还是还考虑使用 Lookup,因为 Lookup 里有一些缓存的设计,可以提高我们处理数据的效率,特别是在 SSIS Package 中反复使用到同一个 Reference 对象的时候。
了解 Lookup 的缓存模式
下面提到的缓存模式只适用于 OLE DB Connection Manager, Cache connection manager 类似于 OLE DB Connection Manager 中的 Full Cache Mode。
Full Cache 完全缓存模式

这是 Lookup 的默认选项,选择这个模式后,在数据流 Data flow 真正执行之前就会将表中的数据或者对应查询结果的数据一次性的从数据源中将数据缓存到内存中。
特点:
- 数据流(SSIS)执行之前缓存全部结果集。
- 消耗内存大,增加了数据流的启动时间。
- 在数据流启动之后执行速度要快,数据不需要从数据源中再次读取。
- 数据源中的数据更新此时将不再影响到缓存中的数据。
- 缓存中的数据可以被后面的组件重复使用。
什么时候该使用 Full Cache?
- Lookup 数据集比较大的时候,一次加载到内存可以反复使用,而不需要反复的去查询数据库。
- 数据库服务器不在本地,为了减少查询次数的情况下也要考虑使用 Full Cache。
使用 Full Cache 模式时要注意的地方:
- 数据全部缓存在内存中,如果内存不够并不会将超出部分的数据缓存到磁盘上,而是直接报错 - Run out of memory。
- 由于数据集缓存在内存中,所以在使用 Lookup 的时候不应该直接使用表对象,而应该通过写 SELECT 语句来减少不必要的列输出并且可以加上 WHERE 条件来限定一下数据集的大小,简而言之缓存的数据应该只包含有用的数据。
- 数据一旦缓存,那么在数据流执行过程中就不会再去检测之前源数据是否发生改变或者更新等等,除非数据流重新启动执行。
Partial Cache 部分缓存模式
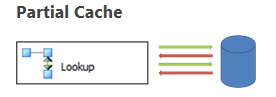
部分缓存模式下,数据流开始时缓存还是空的。当时数据流开始执行后,当 Lookup 组件需要根据输入行找匹配数据的时候,这时 Lookup 组件会先检查一下缓存有没有匹配的数据,如果没有就查询数据库,如果在数据库中查到匹配的数据行的时候就把这个数据行缓存起来,以便下次使用。
查询的过程可以这样理解,比如 Input Source 中有一个 ID1 与 Lookup 对象的 ID2 匹配,那么每次就是拿 ID1 到 Lookup 的缓存中查一下有没有 ID2的值和ID1的值匹配,如果没有的话就用 ID1的值作为一个参数到 ID2 所在的数据库进行查询,因为每次查询的结构是一样的,所以只通过传参数的形式,某种程序上重用了查询语句。
特点:
- 数据流启动之前,缓存为空,数据流启动时间要比完全缓存的情况下要快。
- Lookup 的时候会慢,因为总要检查缓存,如果有的话就直接用,如果没有的话就需要查询数据库,每次查询都是一次开销。如果数据量比较大的话,那么开销就会非常大。
- 可以在 Advanced Options 中设置最大缓存,一旦缓存中的实际数据大小超过这个最大值的话,就会自动清理那些较少使用的数据为新的数据腾出空间。
什么时候该使用部分缓存?
- Lookup 缓存对象数据量较少的时候,不需要花时间等待全部缓存结束后再开始数据流的执行。
No Cache 无缓存模式

每次匹配查询都会去数据库查一次。这种缓存模式下,数据量不大并且内存比较紧张的情况下才会使用,当然它对内存的消耗也相对最小。
以上三种都是 OLE DB 的连接模式,从 SQL Server 2008 开始也支持了一种新的缓存模式 - 文件缓存模式。文件缓存是将 Reference table 中的数据存放到一个共享文件中可以供后面使用同一 Reference table 的 lookup 使用。它对内存的消耗很少,文件的数据直接存放在磁盘上,因此可以处理非常大的 Reference table 数据。
我个人觉得大多数情况下会选择 OLE DB 下的 Full Cache, 因为一般的BI项目数据量比较大并且数据大多主要是分析历史数据,所以对数据的实时性要求不高。同时,现在大多数服务器的环境也有条件让我们一次性加载足够多G的数据放到内存中缓存起来以重复使用。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache的更多相关文章
- 微软BI 之SSIS 系列 - Lookup 中的字符串比较大小写处理 Case Sensitive or Insensitive
开篇介绍 前几天碰到这样的一个问题,在 Lookup 中如何设置大小写不敏感比较,即如何在 Lookup 中的字符串比较时不区分大小写? 实际上就这个问题已经有很多人提给微软了,但是得到的结果就是 C ...
- 微软BI 之SSIS 系列 - 再谈Lookup 缓存
开篇介绍 关于 Lookup 的缓存其实在之前的一篇文章中已经提到了 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache ...
- 微软BI 之SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
开篇介绍 关于 Slowly Changing Dimension 缓慢渐变维度的理论概念请参看 数据仓库系列 - 缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型 ...
- 微软BI 之SSIS 系列 - Merge, Merge Join, Union All 合并组件的使用以及Sort 排序组件同步异步的问题
开篇介绍 SSIS Data Flow 中有几个组件可以实现不同数据源的数据合并功能,比如 Merger, Merge Join 和 Union All.它们的功能比较类似,同时也比较容易混淆,下面是 ...
- 微软BI 之SSIS 系列 - 使用 Script Component Destination 和 ADO.NET 解析不规则文件并插入数据
开篇介绍 这一篇文章是 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧 的续篇,在上篇文章中介绍到了对于这种不规则文件输出的处理方式.比如下图中 ...
- 微软BI 之SSIS 系列 - 在 SSIS 中导入 ACCESS 数据库中的数据
开篇介绍 来自 天善学院 一个学员的问题,如何在 SSIS 中导入 ACCESS 数据表中的数据. 在 SSIS 中导入 ACCESS 数据库数据 ACCESS 实际上是一个轻量级的桌面数据库,直接使 ...
- 微软BI 之SSIS 系列 - MVP 们也不解的 Scrip Task 脚本任务中的一个 Bug
开篇介绍 前些天自己在整理 SSIS 2012 资料的时候发现了一个功能设计上的疑似Bug,在 Script Task 中是可以给只读列表中的变量赋值.我记得以前在 2008 的版本中为了弄明白这个配 ...
- 微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件
原文:微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件 开篇介绍 大多数情况下我们的 SSIS 包都会配置在 SQL Agent ...
- 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧
案例背景与需求介绍 之前做过一个美国的医疗保险的项目,保险提供商有大量的文件需要发送给比如像银行,医疗协会,第三方服务商等.比如像与银行交互的 ACH 文件,传送给协会的 ACH Credit 等文件 ...
随机推荐
- poj3321 dfs序+树状数组单点更新 好题!
当初听郭炜老师讲时不是很懂,几个月内每次复习树状数组必看的题 树的dfs序映射在树状数组上进行单点修改,区间查询. /* 树状数组: lowbit[i] = i&-i C[i] = a[i-l ...
- Android Monkey压力测试环境搭建及使用
Android Monkey压力测试学习笔记 步骤:下载SDK -> 解压进入SDK Manager下载系统 -> 配置环境变量 -> 创建虚拟设备或连接真机 -> 进入命令模 ...
- Python 多环境配置管理
一.概述 实际工程开发中常常会对开发.测试和生产等不同环境配置不同的数据库环境,传统方式可以通过添加不同环境的配置文件达到部署时的动态切换的效果.这种方式还不错,不过不同环境间往往会共享相同的配置而造 ...
- day8--socket文件传输
FTP server 1.读取文件名 2.检测文件是否存在 3.打开文件 4.检测文件大小(告诉客户端发送文件的大小) 5.发送文件大小和MD5值给客户端,MD5 6.等待客户端确认(防止粘包) 7. ...
- 第八章| 2. MySQL数据库|数据操作| 权限管理
1.数据操作 SQL(结构化查询语言),可以操作关系型数据库 通过sql可以创建.修改账号并控制账号权限: 通过sql可以创建.修改数据库.表: 通过sql可以增删改查数据: 可以通过SQL语句中 ...
- ACM题目中的时间限制与内存限制 复杂度的估计
运行时限为1s,这很常见,对于该时限,我们设计的算法复杂度不能超过百万级别,即不要超过一千万.假如你的算法时间复杂度为O(n^2),则n不应该大于3000 空间限制是32MB,即你程序中申请的内存不能 ...
- U盘装机教程
http://winpe.uqidong.asia/upzxpxt/upzxpxt.html
- js算法初窥03(搜索及去重算法)
前面我们了解了一些常用的排序算法,那么这篇文章我们来看看搜索算法的一些简单实现,我们先来介绍一个我们在实际工作中一定用到过的搜索算法——顺序搜索. 1.顺序搜索 其实顺序搜索十分简单,我们还是以第一篇 ...
- linux manjaro 配置 pytorch gpu 环境
manjaro目前中国资料偏少,踩了很多坑. 安装gpu版本就这么几个步骤 1 安装英伟达的驱动cuda 2 安装 cudnn 3 安装支持gpu的pytorch 或者其他的运算框架 manja ...
- PlantUML windows android
dot执行程序. 渲染 url 连接(花费大量时间) 错误 和 语法注释 (是还在实验的) 缓存大小 5 在键入和渲染之间的延迟 (毫秒) 100