Spark任务调度流程及调度策略分析
Spark任务调度
TaskScheduler调度入口:
(1) CoarseGrainedSchedulerBackend 在启动时会创建DriverEndPoint. 而DriverEndPoint中存在一定时任务,每隔一定时间(spark.scheduler.revive.interval, 默认为1s)进行一次调度(给自身发送ReviveOffers消息, 进行调用makeOffers进行调度)。代码如下所示
override def onStart() {
// Periodically revive offers to allow delay scheduling to work
val reviveIntervalMs = conf.getTimeAsMs("spark.scheduler.revive.interval", "1s")
reviveThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReviveOffers))
}
}, , reviveIntervalMs, TimeUnit.MILLISECONDS)
}
(2)当Executor执行完成已分配任务时,会向Driver发送StatusUpdate消息,当Driver接收到消后会调用 makeOffers(executorId)方法,进行任务调度, CoarseGrainedExecutorBackend 状态变化时向Driver (DriverEndPoint)向送StatusUpdate消息
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {
val msg = StatusUpdate(executorId, taskId, state, data)
driver match {
case Some(driverRef) => driverRef.send(msg)
case None => logWarning(s"Drop $msg because has not yet connected to driver")
}
}
Dirver接收到StatusUpdate消息时将会触发设调度(makeOffers),为完成任务的Executor分配任务。
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
case ReviveOffers =>
makeOffers()
case KillTask(taskId, executorId, interruptThread) =>
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.executorEndpoint.send(KillTask(taskId, executorId, interruptThread))
case None =>
// Ignoring the task kill since the executor is not registered.
logWarning(s"Attempted to kill task $taskId for unknown executor $executorId.")
}
}
其中makeOffers方法,会调用TaskSchedulerImpl中的resourceOffers方法,依其的调度策略为Executor分配适合的任务。具体代码如下:
a、为所有资源分配任务
// Make fake resource offers on all executors
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(!executorsPendingToRemove.contains(_))
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
b、为单个executor分配任务
// Make fake resource offers on just one executor
private def makeOffers(executorId: String) {
// Filter out executors under killing
if (!executorsPendingToRemove.contains(executorId)) {
val executorData = executorDataMap(executorId)
val workOffers = Seq(
new WorkerOffer(executorId, executorData.executorHost, executorData.freeCores))
launchTasks(scheduler.resourceOffers(workOffers))
}
}
分配完任务后,向Executor发送LaunchTask指令,启动任务,执行用户逻辑代码
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= akkaFrameSize - AkkaUtils.reservedSizeBytes) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.akka.frameSize (%d bytes) - reserved (%d bytes). Consider increasing " +
"spark.akka.frameSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, akkaFrameSize,
AkkaUtils.reservedSizeBytes)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
Spark任务调度策略
Ò FIFO
FIFO(先进先出)方式调度Job,如下图所示,每个Job被切分成多个Stage.第一个Job优先获取所有可用资源,接下来第二个Job再获取剩余可用资源。(每个Stage对应一个TaskSetManager)
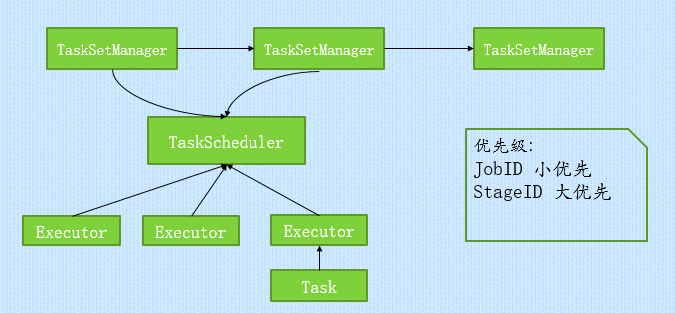
Ò FAIR
FAIR共享模式调度下,Spark以在多Job之间轮询方式为任务分配资源,所有的任务拥有大致相当的优先级来共享集群的资源。FAIR调度模型如下图:
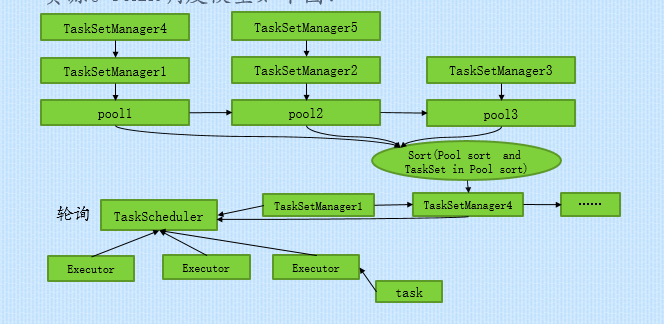
下面从源码的角度对调度策略进行说明:
当触发调度时,会调用TaskSchedulerImpl的resourceOffers方法,方法中会依照调度策略选出要执行的TaskSet, 然后取出适合(考虑本地性)的task交由Executor执行, 其代码如下:
/**
* Called by cluster manager to offer resources on slaves. We respond by asking our active task
* sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so
* that tasks are balanced across the cluster.
*/
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
for (o <- offers) {
executorIdToHost(o.executorId) = o.host
activeExecutorIds += o.executorId
if (!executorsByHost.contains(o.host)) {
executorsByHost(o.host) = new HashSet[String]()
executorAdded(o.executorId, o.host)
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
} // Randomly shuffle offers to avoid always placing tasks on the same set of workers.
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
} // Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
} if (tasks.size > ) {
hasLaunchedTask = true
}
return tasks
}
经过分析可知,通过rootPool.getSortedTaskSetQueue对队列中的TaskSet进行排序,getSortedTaskSetQueue的具体实现如下:
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}
由上述代码可知,其通过算法做为比较器对taskSet进行排序, 其中调度算法有FIFO和FAIR两种,下面分别进行介绍。
FIFO
优先级(Priority): 在DAGscheduler创建TaskSet时使用JobId做为优先级的值。
FIFO调度算法实现如下所示
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == ) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
if (res < ) {
true
} else {
false
}
}
}
由源码可知,FIFO依据JobId进行挑选较小值。因为越早提交的作业,JobId越小。
对同一个作业(Job)来说越先生成的Stage,其StageId越小,有依赖关系的多个Stage之间,DAGScheduler会控制Stage是否会被提交到调度队列中(若其依赖的Stage未执行完前,此Stage不会被提交),其调度顺序可通过此来保证。但若某Job中有两个无入度的Stage的话,则先调度StageId小的Stage.
Fair
Fair调度队列相比FIFO较复杂,其可存在多个调度队列,且队列呈树型结构(现阶段Spark的Fair调度只支持两层树结构),每用户可以使用sc.setLocalProperty(“spark.scheduler.pool”, “poolName”)来指定要加入的队列,默认情况下会加入到buildDefaultPool。每个队列中还可指定自己内部的调度策略,且Fair还存在一些特殊的属性:
schedulingMode: 设置调度池的调度模式FIFO或FAIR, 默认为FIFO.
minShare:最少资源保证量,当一个队列最少资源未满足时,它将优先于其它同级队列获取资源。
weight: 在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配给各个应用程序,而该参数则将打破这种平衡。例如,如果用户配置一个指定调度池权重为2, 那么这个调度池将会获得相对于权重为1的调度池2倍的资源。
以上参数,可通过conf/fairscheduler.xml文件配置调度池的属性。
Fair调度算法实现如下所示:
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare: Int =
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < ) {
true
} else if (compare > ) {
false
} else {
s1.name < s2.name
}
}
}
由原码可知,未满足minShare规定份额的资源的队列或任务集先执行;如果所有均不满足minShare的话,则选择缺失比率小的先调度;如果均不满足,则按执行权重比进行选择,先调度执行权重比小的。如果执行权重也相同的话则会选择StageId小的进行调度(name=“TaskSet_”+ taskSet.stageId.toString)。
以此为标准将所有TaskSet进行排序, 然后选出优先级最高的进行调度。
Spark 任务调度之任务本地性
当选出TaskSet后,将按本地性从中挑选适合Executor的任务,在Executor上执行。
(详细见http://www.cnblogs.com/barrenlake/p/4550800.html一小节相关内容)
文章地址: http://www.cnblogs.com/barrenlake/p/4891589.html
Spark任务调度流程及调度策略分析的更多相关文章
- 【Spark】Spark任务调度相关知识
文章目录 准备知识 DAG 概述 shuffle 概述 SortShuffleManager 普通机制 bypass机制 Spark任务调度 流程 准备知识 要弄清楚Spark的任务调度流程,就必须要 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Spark RPC框架源码分析(三)Spark心跳机制分析
一.Spark心跳概述 前面两节中介绍了Spark RPC的基本知识,以及深入剖析了Spark RPC中一些源码的实现流程. 具体可以看这里: Spark RPC框架源码分析(二)运行时序 Spark ...
- Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend
本文是Scheduler模块源码分析的第二篇,第一篇Spark Scheduler模块源码分析之DAGScheduler主要分析了DAGScheduler.本文接下来结合Spark-1.6.0的源码继 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Spark RPC框架源码分析(二)RPC运行时序
前情提要: Spark RPC框架源码分析(一)简述 一. Spark RPC概述 上一篇我们已经说明了Spark RPC框架的一个简单例子,Spark RPC相关的两个编程模型,Actor模型和Re ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(二)
本文由 网易云发布. 本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 2.Spark Streaming架构及特性分析 2.1 基本架构 ...
- 第二篇:Spark SQL Catalyst源码分析之SqlParser
/** Spark SQL源码分析系列文章*/ Spark SQL的核心执行流程我们已经分析完毕,可以参见Spark SQL核心执行流程,下面我们来分析执行流程中各个核心组件的工作职责. 本文先从入口 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(2)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 2.Spark Streaming架构及特性分析 2.1 基本架构 基于是spark core的spark s ...
随机推荐
- SQL 截图
- bda_百度百科
bda_百度百科 bda
- iOS利用Runtime自定义控制器POP手势动画
前言 苹果在iOS 7以后给导航控制器增加了一个Pop的手势,只要手指在屏幕边缘滑动,当前的控制器的视图就会跟随你的手指移动,当用户松手后,系统会判断手指拖动出来的大小来决定是否要执行控制器的Pop操 ...
- SWOT分析法
SWOT(Strengths Weakness Opportunity Threats)分析法,又称为态势分析法或优劣势分析法,用来确定企业自身的竞争优势(strength).竞争劣势(weaknes ...
- POJ3273:Monthly Expense(二分)
Description Farmer John is an astounding accounting wizard and has realized he might run out of mone ...
- clang和gcc消除警告
1. clang命令,它的作用是用来消除特定区域的clang的编译警告,-Wgnu则是消除?:警告, 例: #pragma clang diagnostic push #pragma clang di ...
- JavaScript MVC 框架[转载]
MVC,MVP 和 MVVM 的图示 http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html http://blog.nodejitsu.com ...
- swift学习资料初探
1. http://code.csdn.net/news/2820075
- Swift Core Data 图片存储与读取Demo
实体的模型定义: 实体的class定义: @objc(ImageEntity) class ImageEntity: NSManagedObject { @NSManaged var imageDat ...
- QTimerLine类学习
QTimeLine类提供了控制动画的时间轴. 类型:enum CurveShape{EaseInCurve,EaseOutCurve,EaseInOutCurve,LinearCurve,Sine ...