机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent)
题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记。
梯度下降是线性回归的一种(Linear Regression),首先给出一个关于房屋的经典例子,
| 面积(feet2) | 房间个数 | 价格(1000$) |
| 2104 | 3 | 400 |
| 1600 | 3 | 330 |
| 2400 | 3 | 369 |
| 1416 | 2 | 232 |
| 3000 | 4 | 540 |
| ... | ... | .. |
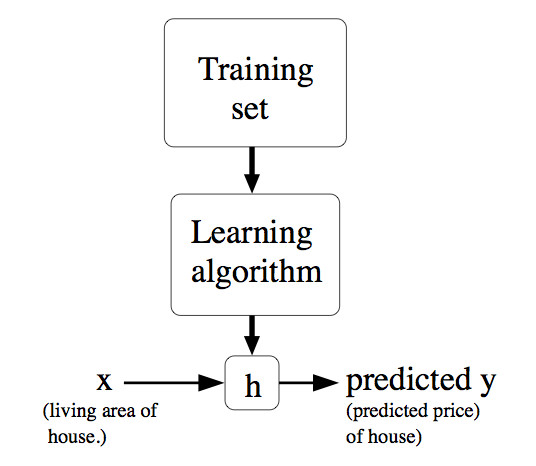
上表中面积和房间个数是输入参数,价格是所要输出的解。面积和房间个数分别表示一个特征,用X表示。价格用Y表示。表格的一行表示一个样本。现在要做的是根据这些样本来预测其他面积和房间个数对应的价格。可以用以下图来表示,即给定一个训练集合,学习函数h,使得h(x)能符合结果Y。
一. 批梯度下降算法
可以用以下式子表示一个样本:

θ表示X映射成Y的权重,x表示一次特征。假设x0=1,上式就可以写成:
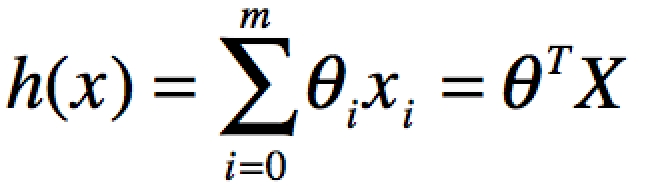
分别使用x(j),y(j)表示第J个样本。我们计算的目的是为了让计算的值无限接近真实值y,即代价函数可以采用LMS算法
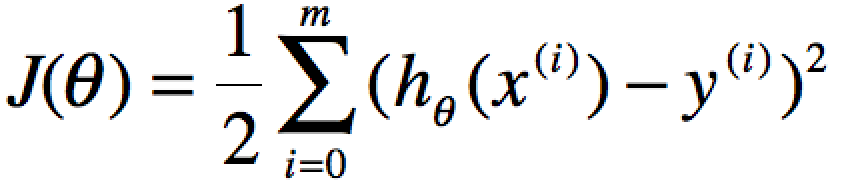
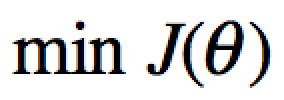
要获取J(θ)最小,即对J(θ)进行求导且为零:
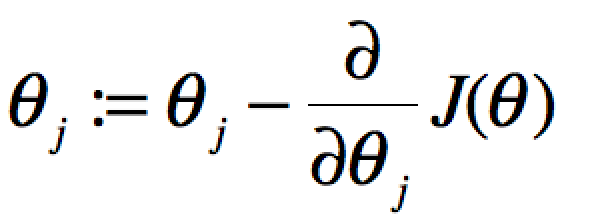
当单个特征值时,上式中j表示系数(权重)的编号,右边的值赋值给左边θj从而完成一次迭代。
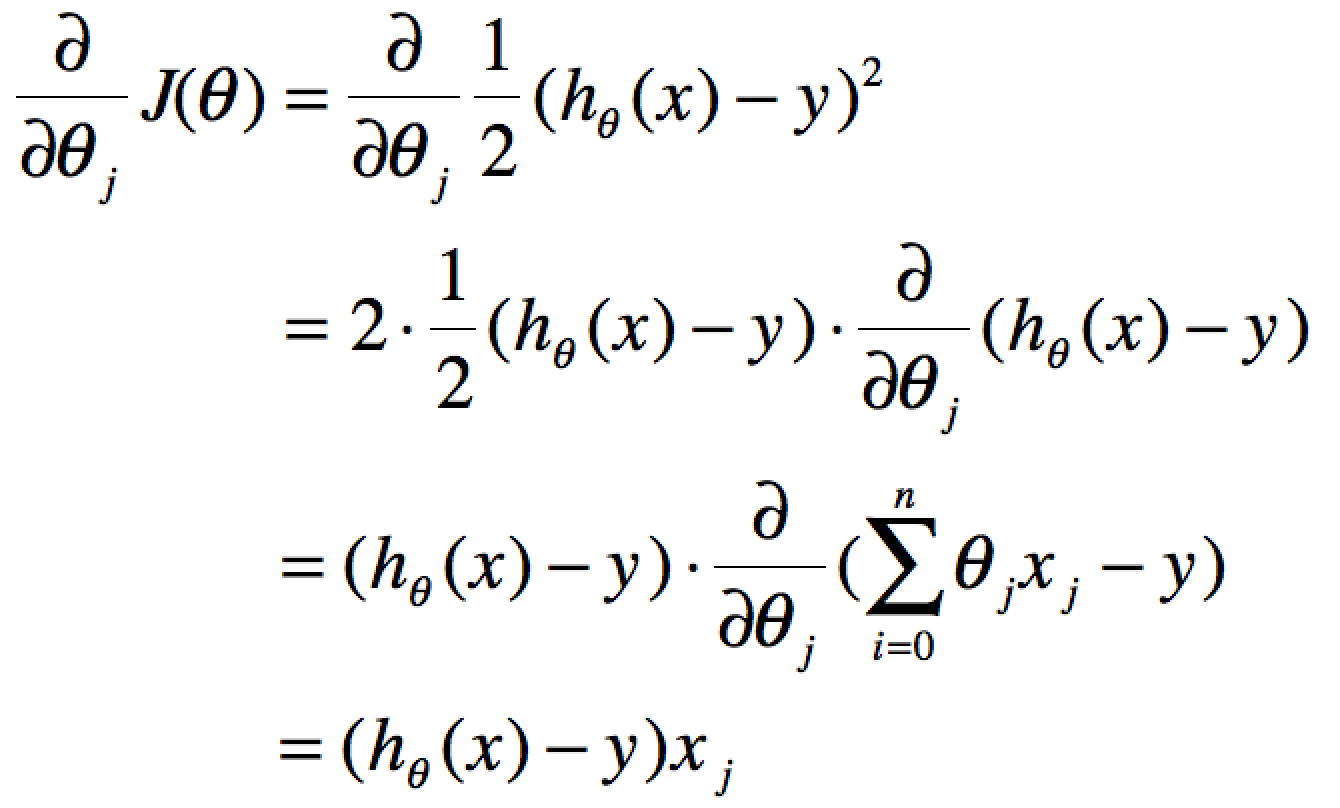
单个特征的迭代如下:

多个特征的迭代如下:
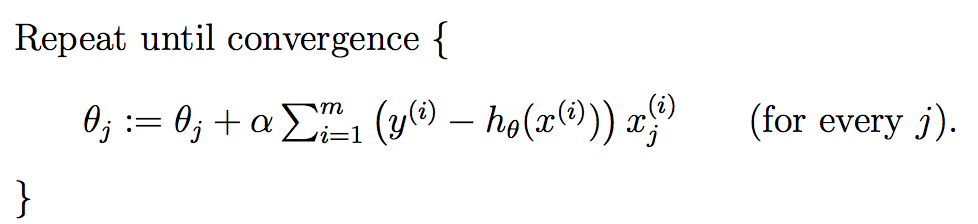
上式就是批梯度下降算法(batch gradient descent),当上式收敛时则退出迭代,何为收敛,即前后两次迭代的值不再发生变化了。一般情况下,会设置一个具体的参数,当前后两次迭代差值小于该参数时候结束迭代。注意以下几点:
二. 随机梯度下降算法
因为每次计算梯度都需要遍历所有的样本点。这是因为梯度是J(θ)的导数,而J(θ)是需要考虑所有样本的误差和 ,这个方法问题就是,扩展性问题,当样本点很大的时候,基本就没法算了。所以接下来又提出了随机梯度下降算法(stochastic gradient descent )。随机梯度下降算法,每次迭代只是考虑让该样本点的J(θ)趋向最小,而不管其他的样本点,这样算法会很快,但是收敛的过程会比较曲折,整体效果上,大多数时候它只能接近局部最优解,而无法真正达到局部最优解。所以适合用于较大训练集的case。
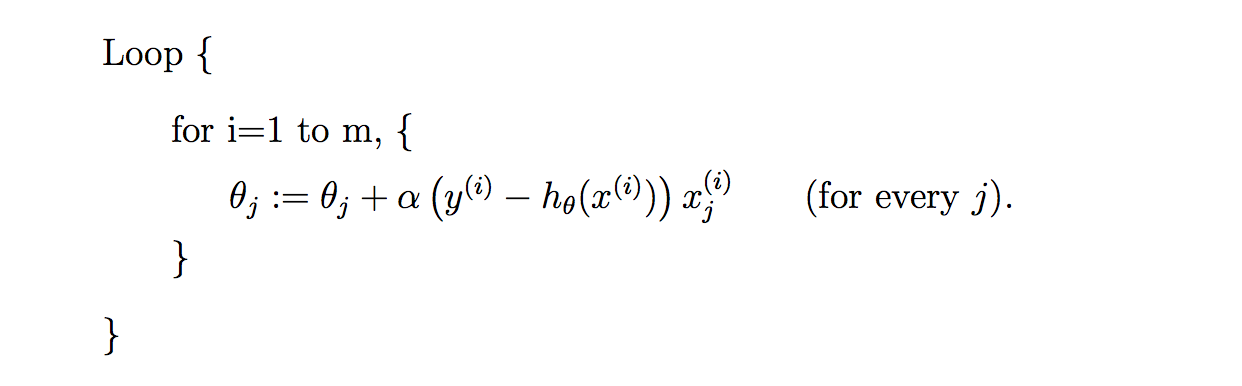
三.代码实现
随机梯度下降算法的python的实现:
# coding=utf-8
#!/usr/bin/python '''
Created on 2014年9月6日 @author: Ryan C. F. ''' #Training data set
#each element in x represents (x0,x1,x2)
x = [(1,0.,3) , (1,1.,3) ,(1,2.,3), (1,3.,2) , (1,4.,4)]
#y[i] is the output of y = theta0 * x[0] + theta1 * x[1] +theta2 * x[2]
y = [95.364,97.217205,75.195834,60.105519,49.342380] epsilon = 0.0001
#learning rate
alpha = 0.01
diff = [0,0]
error1 = 0
error0 =0
m = len(x) #init the parameters to zero
theta0 = 0
theta1 = 0
theta2 = 0 while True: #calculate the parameters
for i in range(m): diff[0] = y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] ) theta0 = theta0 + alpha * diff[0]* x[i][0]
theta1 = theta1 + alpha * diff[0]* x[i][1]
theta2 = theta2 + alpha * diff[0]* x[i][2] #calculate the cost function
error1 = 0
for lp in range(len(x)):
error1 += ( y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] ) )**2/2 if abs(error1-error0) < epsilon:
break
else:
error0 = error1 print ' theta0 : %f, theta1 : %f, theta2 : %f, error1 : %f'%(theta0,theta1,theta2,error1) print 'Done: theta0 : %f, theta1 : %f, theta2 : %f'%(theta0,theta1,theta2)
批梯度下降算法
# coding=utf-8
#!/usr/bin/python '''
Created on 2014年9月6日 @author: Ryan C. F. ''' #Training data set
#each element in x represents (x0,x1,x2)
x = [(1,0.,3) , (1,1.,3) ,(1,2.,3), (1,3.,2) , (1,4.,4)]
#y[i] is the output of y = theta0 * x[0] + theta1 * x[1] +theta2 * x[2]
y = [95.364,97.217205,75.195834,60.105519,49.342380] epsilon = 0.000001
#learning rate
alpha = 0.001
diff = [0,0]
error1 = 0
error0 =0
m = len(x) #init the parameters to zero
theta0 = 0
theta1 = 0
theta2 = 0
sum0 = 0
sum1 = 0
sum2 = 0
while True: #calculate the parameters
for i in range(m):
#begin batch gradient descent
diff[0] = y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] )
sum0 = sum0 + alpha * diff[0]* x[i][0]
sum1 = sum1 + alpha * diff[0]* x[i][1]
sum2 = sum2 + alpha * diff[0]* x[i][2]
#end batch gradient descent
theta0 = sum0;
theta1 = sum1;
theta2 = sum2;
#calculate the cost function
error1 = 0
for lp in range(len(x)):
error1 += ( y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] ) )**2/2 if abs(error1-error0) < epsilon:
break
else:
error0 = error1 print ' theta0 : %f, theta1 : %f, theta2 : %f, error1 : %f'%(theta0,theta1,theta2,error1) print 'Done: theta0 : %f, theta1 : %f, theta2 : %f'%(theta0,theta1,theta2)
通过上述批梯度下降和随机梯度下降算法代码的对比,不难发现两者的区别:
1. 随机梯度下降算法在迭代的时候,每迭代一个新的样本,就会更新一次所有的theta参数。
35 for i in range(m):
36
37 diff[0] = y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] )
38
39 theta0 = theta0 + alpha * diff[0]* x[i][0]
40 theta1 = theta1 + alpha * diff[0]* x[i][1]
41 theta2 = theta2 + alpha * diff[0]* x[i][2]
2. 批梯度下降算法在迭代的时候,是完成所有样本的迭代后才会去更新一次theta参数
35 #calculate the parameters
36 for i in range(m):
37 #begin batch gradient descent
38 diff[0] = y[i]-( theta0 + theta1 * x[i][1] + theta2 * x[i][2] )
39 sum0 = sum0 + alpha * diff[0]* x[i][0]
40 sum1 = sum1 + alpha * diff[0]* x[i][1]
41 sum2 = sum2 + alpha * diff[0]* x[i][2]
42 #end batch gradient descent
43 theta0 = sum0;
44 theta1 = sum1;
45 theta2 = sum2;
因此当样本数量很大时候,批梯度得做完所有样本的计算才能更新一次theta,从而花费的时间远大于随机梯度下降。但是随机梯度下降过早的结束了迭代,使得它获取的值只是接近局部最优解,而并非像批梯度下降算法那么是局部最优解。
因此我觉得以上的差别才是批梯度下降与随机梯度下降最本质的差别。
机器学习(1)之梯度下降(gradient descent)的更多相关文章
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
随机推荐
- __block在ARC和非ARC下有什么不同
一般在block中修改变量都需要事先加block进行修饰.在非arc中,block修饰的变量的引用计算是不变的.在arc中,会引用到,并且计算+1:非arc下可使用(arc直接使用__weak即可) ...
- ORA-01078:failure in processing system parameters
一.使用环境操作系统:rhel 6.5 x64数据库:Oracle 11.2.0.1.0数据库主目录:/u01/app/oracle/product/11.2.0/ 二.问题描述用sys用户登录sql ...
- erlang mnesia数据库设置主键自增
Mnesia是erlang/otp自带的分布式数据库管理系统.mnesia配合erlang的实现近乎理想,但在实际使用当中差强人意,总会有一些不足.mnesia数据表没有主键自增的功能,但在mnesi ...
- 面向新手的Webserver搭建(一)——IIS的搭建
非常多童鞋说自己是做移动开发的,想挂个简单的Web API,但是server又不会搭,这样一来測试就成了问题.看看网上的教程.发现略难懂,并且大多是一个转一个,没价值,所以干脆写几篇文章讲讲简单的We ...
- Git客户端(Windows系统)的使用
本文环境: 操作系统:Windows XP SP3 Git客户端:TortoiseGit-1.8.5.0-32bit 一.安装Git客户端 全部安装均采用默认! 1. 安装支撑软件 msysgit: ...
- [转] javascript对数组的操作
javascript数组操作大全,数组方法总汇 1. shift:删除原数组第一项,并返回删除元素的值:如果数组为空则返回undefined var a = [1,2,3,4,5]; var b = ...
- Proxy 代理模式
简介 代理模式是用一个简单的对象来代替一个复杂的或者创建耗时的对象. java.lang.reflect.Proxy RMI 代理模式是对象的结构模式.代理模式给某一个对象提供一个代理对象,并由代理对 ...
- 从今天开始学习C#啦
此博客为证,在下从今天开始学习C#,并把心得体会记录下来.
- 图片标签的alt与title区别
一.img标签alt属性 1.alt属性是考虑到不支持图像显示或者图像显示被关闭的浏览器的用户,以及视觉障碍的用户和使用屏幕阅读器的用户.当图片不显示的时候,图片的替换文字. 2.alt属性值得长度必 ...
- 解决CSS中float:left后需要clear:both清空的繁琐步骤(转)
之前,因为公司专门有CSS+DIV的切片设计师,所以我一直都是注重程序的设计与开发.现在,因为接了一些Web网站的项目需要制作,就在空闲时间学习起了CSS.Jquery. 现在,大部分的横排导航都 ...