Consistent hashing
What is libconhash
libconhash is a consistent hashing library which can be compiled both on Windows and Linux platforms, with the following features:
- High performance and easy to use, libconhash uses a red-black tree to manage all nodes to achieve high performance.
- By default, it uses the MD5 algorithm, but it also supports user-defined hash functions.
- Easy to scale according to the node's processing capacity.
Consistent hashing
Why you need consistent hashing
Now we will consider the common way to do load balance. The machine number chosen to cache object o will be:
hash(o) mod n
Here, n is the total number of cache machines. While this works well until you add or remove cache machines:
- When you add a cache machine, then object o will be cached into the machine:
hash(o) mod (n+1)
- When you remove a cache machine, then object o will be cached into the machine:
Hide Copy Code
hash(o) mod (n-1)
So you can see that almost all objects will hashed into a new location. This will be a disaster since the originating content servers are swamped with requests from the cache machines. And this is why you need consistent hashing.
Consistent hashing can guarantee that when a cache machine is removed, only the objects cached in it will be rehashed; when a new cache machine is added, only a fairly few objects will be rehashed.
Now we will go into consistent hashing step by step.
Hash space
Commonly, a hash function will map a value into a 32-bit key, 0~2^32-1. Now imagine mapping the range into a circle, then the key will be wrapped, and 0 will be followed by 2^32-1, as illustrated in figure 1.

Map object into hash space
Now consider four objects: object1~object4. We use a hash function to get their key values and map them into the circle, as illustrated in figure 2.

hash(object1) = key1;
.....
hash(object4) = key4;
Map the cache into hash space
The basic idea of consistent hashing is to map the cache and objects into the same hash space using the same hash function.
Now consider we have three caches, A, B and C, and then the mapping result will look like in figure 3.
hash(cache A) = key A;
....
hash(cache C) = key C;

Map objects into cache
Now all the caches and objects are hashed into the same space, so we can determine how to map objects into caches. Take object obj for example, just start from where obj is and head clockwise on the ring until you find a server. If that server is down, you go to the next one, and so forth. See figure 3 above.
According to the method, object1 will be cached into cache A; object2 and object3 will be cached into cache C, and object4 will be cached into cache B.
Add or remove cache
Now consider the two scenarios, a cache is down and removed; and a new cache is added.
If cache B is removed, then only the objects that cached in B will be rehashed and moved to C; in the example, see object4 illustrated in figure 4.

If a new cache D is added, and D is hashed between object2 and object3 in the ring, then only the objects that are between D and B will be rehashed; in the example, see object2, illustrated in figure 5.

Virtual nodes
It is possible to have a very non-uniform distribution of objects between caches if you don't deploy enough caches. The solution is to introduce the idea of "virtual nodes".
Virtual nodes are replicas of cache points in the circle, each real cache corresponds to several virtual nodes in the circle; whenever we add a cache, actually, we create a number of virtual nodes in the circle for it; and when a cache is removed, we remove all its virtual nodes from the circle.
Consider the above example. There are two caches A and C in the system, and now we introduce virtual nodes, and the replica is 2, then three will be 4 virtual nodes. Cache A1 and cache A2 represent cache A; cache C1 and cache C2 represent cache C, illustrated as in figure 6.

Then, the map from object to the virtual node will be:
objec1->cache A2; objec2->cache A1; objec3->cache C1; objec4->cache C2
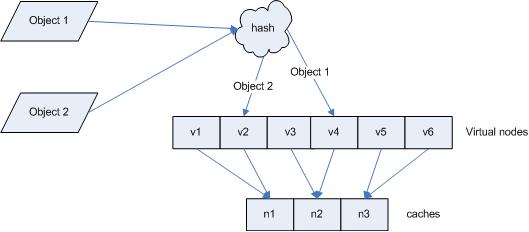
When you get the virtual node, you get the cache, as in the above figure.
So object1 and object2 are cached into cache A, and object3 and object4 are cached into cache. The result is more balanced now.
So now you know what consistent hashing is.
Using the code
Interfaces of libconhash
/* initialize conhash library
* @pfhash : hash function, NULL to use default MD5 method
* return a conhash_s instance
*/
CONHASH_API struct conhash_s* conhash_init(conhash_cb_hashfunc pfhash); /* finalize lib */
CONHASH_API void conhash_fini(struct conhash_s *conhash); /* set node */
CONHASH_API void conhash_set_node(struct node_s *node,
const char *iden, u_int replica); /*
* add a new node
* @node: the node to add
*/
CONHASH_API int conhash_add_node(struct conhash_s *conhash,
struct node_s *node); /* remove a node */
CONHASH_API int conhash_del_node(struct conhash_s *conhash,
struct node_s *node);
... /*
* lookup a server which object belongs to
* @object: the input string which indicates an object
* return the server_s structure, do not modify the value,
* or it will cause a disaster
*/
CONHASH_API const struct node_s*
conhash_lookup(const struct conhash_s *conhash,
const char *object);
Libconhash is very easy to use. There is a sample in the project that shows how to use the library.
First, create a conhash instance. And then you can add or remove nodes of the instance, and look up objects.
The update node's replica function is not implemented yet.
/* init conhash instance */
struct conhash_s *conhash = conhash_init(NULL);
if(conhash)
{
/* set nodes */
conhash_set_node(&g_nodes[0], "titanic", 32);
/* ... */ /* add nodes */
conhash_add_node(conhash, &g_nodes[0]);
/* ... */
printf("virtual nodes number %d\n", conhash_get_vnodes_num(conhash));
printf("the hashing results--------------------------------------:\n"); /* lookup object */
node = conhash_lookup(conhash, "James.km");
if(node) printf("[%16s] is in node: [%16s]\n", str, node->iden);
}
Reference
License
This article, along with any associated source code and files, is licensed under The BSD License
Consistent hashing的更多相关文章
- Consistent hashing —— 一致性哈希
原文地址:http://www.codeproject.com/Articles/56138/Consistent-hashing 基于BSD License What is libconhash l ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性哈希算法 - consistent hashing
1 基本场景比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 ...
- 一致性 hash 算法( consistent hashing )
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在cache 系统中应用越来越广泛: 1 基 ...
- 【转】一致性hash算法(consistent hashing)
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛: 1 ...
- Consistent Hashing算法-搜索/负载均衡
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- 一致性hash算法 - consistent hashing
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛: 1 ...
- Consistent Hashing原理与实现
原理介绍: consistent hashing原理介绍来自博客:http://blog.csdn.net/sparkliang/article/details/5279393, 多谢博主的分享 co ...
- 一致性哈希算法(consistent hashing)样例+測试。
一个简单的consistent hashing的样例,非常easy理解. 首先有一个设备类,定义了机器名和ip: public class Cache { public String name; pu ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
随机推荐
- mongodb 安装部署说明
mongodb.conf 配置文件 # Where the databases will be stored dbpath=/usr/local/mongodb/mongodb-/data/db # ...
- Xcode7 beta 网络请求报错:The resource could not be loaded because the App Transport Security policy requir
今天升级Xcode 7.0 bata发现网络访问失败.输出错误信息 The resource could not be loaded because the App Transport S ...
- 架设HmailServer邮件服务器以及webmail
参考:http://www.it0355.com/a/201207/31/a9275.htm 在安裝Hmailserver前先安裝Apache.php.mysql,如果你想懶點直接到http://ww ...
- 跑测试没有web环境的情况
有时候 当你跑测试的main方法的时候,会有一些莫名其妙的错误,明明mave pom的包是全的,web跑起来不会报错,可是在main方法下就是报错了,这个时候引入 <dependency> ...
- js 正则表达式 验证小数点后几位
function IsFloatByBit (value, state, bit) { if (state == false) { var re ...
- PHP学习笔记(12)分页技术
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 解决Linux环境下Tomcat启动卡住问题
最近发现在服务器上启动tomcat,会存在卡住的情况,这种情况是每次必现,通过搜索发现是随机数生成问题.解决方案如下 将$JAVA_HOME/jre/lib/security/Java.securit ...
- 碉堡完整的高性能PHP应用服务器appserver
完全企业级的开发模式,是一个多线程的 PHP 应用服务器,实现真正多线程的 PHP 编程,高效安全而且快速,以Magento 为例比基于 Nginx的标准安装要快 50%.概念上非常像 Java 的 ...
- Nginx+PHP-FPM优化技巧总结
php-fpm的安装很简单,参见PHP(PHP-FPM)手动编译安装.下面主要讨论下如何提高Nginx+Php-fpm的性能. 1.Unix域Socket通信 之前简单介绍过Unix Doma ...
- Java Drp项目实战——Web应用server
引言 Web应用server如今非常多人都在用,但是究竟什么是Web应用server呢,它与Webserver有什么关系,它与应用server又是什么关系,它是他们两种中的当中一种,还是简单的两种se ...