PgSQL · 特性分析 · 谈谈checkpoint的调度
在PG的众多参数中,参数checkpoint相关的几个参数颇为神秘。这些参数与checkpoint的调度有关,对系统的稳定性还是比较重要的,下面我们为大家解析一下,这要先从PG的数据同步机制谈起。
PG的数据同步机制
众所周知,数据库的后台进程在执行用户事务时,发生的数据更改是先写入缓冲池中,对应PG就是shared buffers。PG的缓冲池一般设置为总内存的1/4左右,缓冲池里面的这些数据更改,在事务提交时,是无需同步写入到磁盘的。因为在事务提交时,会先写入WAL日志,有了WAL日志,就可以在异常情况下将数据恢复,保障数据安全,因此数据本身是否在提交时写入磁盘就没那么重要了。PG是只是在需要的时候,例如脏页较多时、或一定时间间隔后,才将数据写回磁盘。
脏页处理的过程分为几个步骤。首先是由background writer将shared buffers里面的被更改过的页面(即脏页),通过调用write写入操作系统page cache。在函数BgBufferSync可以看到,PG的background writer进程,会根据LRU链表,扫描shared buffers(实际上是每次扫描一部分),如果发现脏页,就调用系统调用write。可以通过设置bgwriter_delay参数,来控制background writer每次扫描之间的时间间隔。background writer在对一个页面调用write后,会将该页面对应的文件(实际上是表的segement,每个表可能有多个segment,对应多个物理文件)记录到共享内存的数组CheckpointerShmem->requests中,调用顺序如下:
BackgroundWriterMain -> BgBufferSync -> SyncOneBuffer -> FlushBuffer -> smgrwrite
|
|
V
ForwardFsyncRequest <- register_dirty_segment <- mdwrite
这些request最终会被checkpointer进程读取,放入pendingOpsTable,而真正将脏页回写到磁盘的操作,是由checkpointer进程完成的。checkpointer每次也会调用smgrwrite,把所有的shared buffers脏页(即还没有被background writer清理过得脏页)写入操作系统的page cache,并存入pendingOpsTable。这样pendingOpsTable存放了所有write过的脏页,包括之前background writer已经处理的脏页。随后PG的checkpointer进程会根据pedingOpsTable的记录,进行脏页回写操作(注意每次调用fysnc,都会sync数据表的一个文件,文件中所有脏页都会写入磁盘),调用顺序如下:
CheckPointGuts->CheckPointBuffers->->mdsync->pg_fsync->fsync
如果checkpointer做磁盘写入的频率过高,则每次可能只写入很少的数据。我们知道,磁盘对于顺序写入批量数据比随机写的效率要高的多,每次写入很少数据,就造成大量随机写;而如果我们放慢checkpoint的频率,多个随机页面就有可能组成一次顺序批量写入,效率大大提高。另外,checkpoint会进行fsync操作,大量的fsync可能造成系统IO阻塞,降低系统稳定性,因此checkpoint不能过于频繁。但checkpoint的间隔也不能无限制放大。因为如果出现系统宕机,在进行恢复时,需要从上一次checkpoint的时间点开始恢复,如果checkpoint间隔过长,会造成恢复时间缓慢,降低可用性。整个同步机制如下图所示:
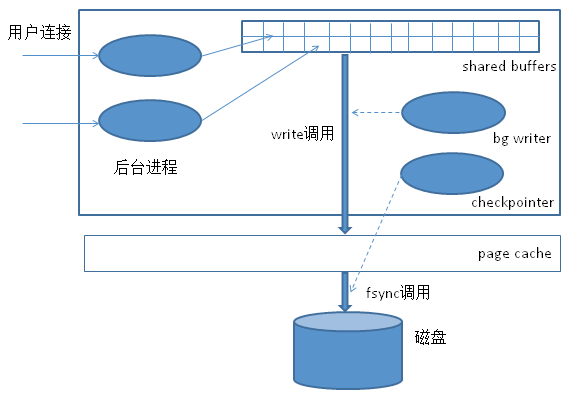
图1. 数据同步机制
checkpoint的调度
那么如何调度checkpoint,即控制checkpoint的间隔呢?PG提供了几个参数:checkpoint_segments、checkpoint_completion_target和checkpoint_timeout。
决定是否做checkpoint有两个指标维度:
系统的数据修改量。
评估修改量,有两种方法:一种是记录shared buffer里面的脏页有多少,占所有buffer的多大比例;另外一种,记录用户事务的数据修改量是多少。如果用系统的脏页数量或所占比例,来评估修改量,会不太准确,用户有可能反复修改相同的页面,脏页不多,但实际修改量很大,这时候也是应该尽快进行checkpoint,减少恢复时间的。而通过记录WAL日志的产生量,可以很好的评估这个修改量,所以就有了checkpoint_segments这个参数,它用于指定产生多少WAL日志后,进行一次checkpoint。例如设置为16时,产生16个WAL日志文件后(如果每个日志文件的大小为16M,即产生16*16M字节的日志),进行一次checkpoint。判断是否触发checkpoint的调用如下:XLogInsert->XLogFlush->XLogWirte->XLogCheckpointNeeded
距离上一次checkpoint的时间。
也就是在上一次checkpoint后,多长时间必须做一次checkpoint。PG提供了checkpoint_timeout这个参数,缺省值为300秒,即如果上一次checkpoint后过了300秒没有做checkpoint了,就强制做一次checkpoint。
那么另外一个参数checkpoint_completion_target是做什么的呢?
checkpoint_completion_target 参数
这个看似不起眼的参数其实对checkpoint调度的影响很大。它是怎么使用的呢?checkpoint会调用BufferSync,将所有shared buffers的页面扫描一遍,如果发现脏页即调用write,写入page cache。每次write完一个脏页后,会调用IsCheckpointOnSchedule()这个函数。这个函数的主要逻辑是,判断新产生的日志文件数除以checkpoint_segments,结果是否小于checkpoint_completion_target。注意,这里的新产生日志文件数,是checkpoint开始后新产生的日志数,不是从上一次checkpoint结束后的新日志数。如果IsCheckpointOnSchedule()返回true,则checkpointer进程会进行sleep,sleep一定时间后,再读取下一个shared buffers页面进行write。这样做的效果是,当所有页面write完成时,新产生的日志页面数占checkpoint_segements的比例约为checkpoint_completion_target的设定值。例如,如果checkpoint_segements为16,checkpoint_completion_target为0.9,则当上一次checkpoint后,新的第16个日志文件产生后,写日志的那个进程会触发一次checkpoint。checkpoiter进程随即调用CreateCheckPoint,做一次checkpoint,checkpointer进程会调用BufferSync,扫描shared buffers写脏页。此时每次write一个脏页后,如果新产生的日志文件数小于16*0.9,即15个日志文件时,会进行sleep。最后当write脏页完成时,从上次checkpoint开始新产生的日志文件约为16+15=31个,即
checkpoint_segments + checkpoint_segments * checkpoint_completion_target
由此可见,checkpoint_completion_target直接控制了checkpoint中的write脏页的速度,使其完成时新产生日志文件数为上述期望值。
除了日志文件数,IsCheckpointOnSchedule()还会检查从checkpoint开始到现在的时间占checkpoint_timeout的比例,是否小于checkpoint_completion_target,以决定是否sleep。按checkpoint_completion_target为0.9,checkpoint_timeout为300秒计算,脏页write的完成时间距离checkpoint开始的时间,大约是270秒。实际上,这个时间上的约束和产生日志文件数的约束是同时起作用的。
当脏页全部被write完,就要进行真正的磁盘操作了,即fsync。此时每个文件的fsync之间没有sleep,是尽快完成的。一般做fsync总时间不会超过10秒,因此会赶在时间间隔到达checkpoint_timeout或新日志文件数到达checkpoint_segments前(都从checkpoint开始时间点开始算起)结束此次checkpoint。
总结起来,每次checkpoint所耗时间可以用下面的公式计算:
min(产生checkpoint_segments*checkpoint_completion_target个日志文件的时间,checkpoint_timeout*checkpoint_completion_target)+ 做fsync的时间
比如上面的例子,将会是:
min (产生15个日志文件的时间,270秒)+ fsync的时间
而这个时间一般小于产生checkpoint_segments个日志或checkpoint_timeout的时间。这样综合的效果是,每产生checkpoint_segments个日志或经历checkpoint_timeout的时间做一次checkpoint。在两次checkpoint的开始时间之间,会在checkpoint_completion_target比例的时间点完成脏页write,随后很快进行完fsync,如下图所示:
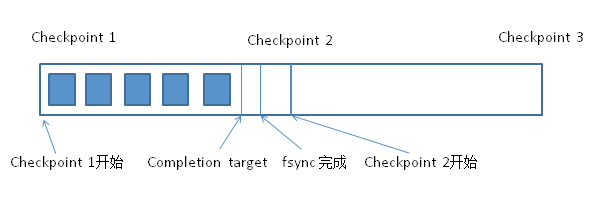
图2. checkpoint过程
以上便是checkpoint的调度机制。我们要注意调整上述几个参数时,不要让checkpoint产生过于频繁,否则频繁的fsync操作会是系统不稳定。比如,checkpoint_segments一般设置为16个以上,checkpoint_completion_target设为0.9,checkpoint_timeout为300秒,这样一般checkpoint的间隔能达到1分钟以上。
参考:
http://mysql.taobao.org/monthly/2015/09/06/
PgSQL · 特性分析 · 谈谈checkpoint的调度的更多相关文章
- PgSQL · 特性分析 · PG主备流复制机制
原文地址:http://mysql.taobao.org/monthly/2015/10/04/ PostgreSQL在9.0之后引入了主备流复制机制,通过流复制,备库不断的从主库同步相应的数据,并在 ...
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
- Spark源码分析之六:Task调度(二)
话说在<Spark源码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这个方法针对接收到的ReviveOffer ...
- Spark源码分析之五:Task调度(一)
在前四篇博文中,我们分析了Job提交运行总流程的第一阶段Stage划分与提交,它又被细化为三个分阶段: 1.Job的调度模型与运行反馈: 2.Stage划分: 3.Stage提交:对应TaskSet的 ...
- Spark源代码分析之六:Task调度(二)
话说在<Spark源代码分析之五:Task调度(一)>一文中,我们对Task调度分析到了DriverEndpoint的makeOffers()方法.这种方法针对接收到的ReviveOffe ...
- MySQL · 特性分析 · MDL 实现分析
http://mysql.taobao.org/monthly/2015/11/04/ 前言 在MySQL中,DDL是不属于事务范畴的,如果事务和DDL并行执行,操作相关联的表的话,会出现各种意想不到 ...
- hive 桶相关特性分析
1. hive 桶相关概念 桶(bucket)是指将表或分区中指定列的值为key进行hash,hash到指定的桶中,这样可以支持高效采样工作. 抽样( sampling )可以在全体数 ...
- SparkSteaming运行流程分析以及CheckPoint操作
本文主要通过源码来了解SparkStreaming程序从任务生成到任务完成整个执行流程以及中间伴随的checkpoint操作 注:下面源码只贴出跟分析内容有关的代码,其他省略 1 分析流程 应用程序入 ...
- 了解与建设有中国特色的Android M&N(Android6.0和7.0新特性分析)
http://geek.csdn.NET/news/detail/110434 Android N已经发布有段时间,甚至马上都要发布android 7.1,相信不少玩机爱好者已经刷入最新的Androi ...
随机推荐
- PAT 07-3 求素数
求素数,这是一个“古老”的问题,每个学过编程的人都应该碰到过,这里是求第M+1到第N个素数,这么经典的问题,当然得给它写上一笔,下面是题设要求及代码实现 /* Name: Copyright: Aut ...
- Bad Hair Day_单调栈
Description Some of Farmer John's N cows (1 ≤ N ≤ 80,000) are having a bad hair day! Since each cow ...
- iOS-appDelegate 生命周期
- (void)applicationWillResignActive:(UIApplication *)application 说明:当应用程序将要入非活动状态执行,在此期间,应用程序不接收消息或事 ...
- 六、CCLayer
一个游戏中可以有很多个场景,每个场景里面又可能包含有多个图层,这里的图层一般就是CCLayer对象.CCLayer本身几乎没什么功能,对比CCNode,CCLayer可用于接收触摸和加速计输入.其实, ...
- Threads Events QObjects
Events and the event loop Being an event-driven toolkit, events and event delivery play a central ro ...
- cocos2d-html5 sprite打印宽高都为0的问题
版本是2.1.4,在程序里直接通过图片路径addChild了一个cc.Sprite,想要缩放时通是不起做用,于是通过打印发现其宽,高都为0,查来查去,发现:原来是图片没有注册到Resource.js里 ...
- USB相关的网络资料
相关资源连接: USB官网:http://www.usb.org/home <USB in a NutShell>: http://www.beyondlogic.org/usbnutsh ...
- PAT (Basic Level) Practise:1005. 继续(3n+1)猜想
[题目链接] 卡拉兹(Callatz)猜想已经在1001中给出了描述.在这个题目里,情况稍微有些复杂. 当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数.例如对n=3进 ...
- 解决:“MediaPlayer error (1, -2147483648)”问题
如果你使用VideoView播放过MP4视频,你可能碰到过类似下面的问题: MediaPlayer error (1, -2147483648) 如果你查阅文档,会发现1其实代表MEDIA_ERR ...
- 修改数据库mysql字符编码为UTF8
Mysql数据库是一个开源的数据库,应用非常广泛.以下是修改mysql数据库的字符编码的操作过程. 步骤1:查看当前的字符编码方法 mysql> show variables like'char ...