k-means聚类算法python实现
K-means聚类算法
算法优缺点:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
算法思想
k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去。
1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好。另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚类你可能就会考虑分成三类(L,M,S)等
2.然后我们需要选择最初的聚类点(或者叫质心),这里的选择一般是随机选择的,代码中的是在数据范围内随机选择,另一种是随机选择数据中的点。这些点的选择会很大程度上影响到最终的结果,也就是说运气不好的话就到局部最小值去了。这里有两种处理方法,一种是多次取均值,另一种则是后面的改进算法(bisecting K-means)
3.终于我们开始进入正题了,接下来我们会把数据集中所有的点都计算下与这些质心的距离,把它们分到离它们质心最近的那一类中去。完成后我们则需要将每个簇算出平均值,用这个点作为新的质心。反复重复这两步,直到收敛我们就得到了最终的结果。
函数
loadDataSet(fileName)
从文件中读取数据集distEclud(vecA, vecB)
计算距离,这里用的是欧氏距离,当然其他合理的距离都是可以的randCent(dataSet, k)
随机生成初始的质心,这里是虽具选取数据范围内的点kMeans(dataSet, k, distMeas=distEclud, createCent=randCent)
kmeans算法,输入数据和k值。后面两个事可选的距离计算方式和初始质心的选择方式show(dataSet, k, centroids, clusterAssment)
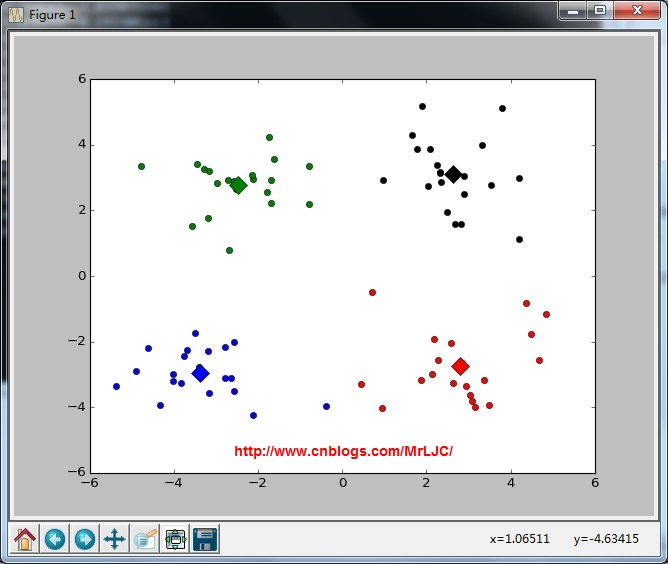
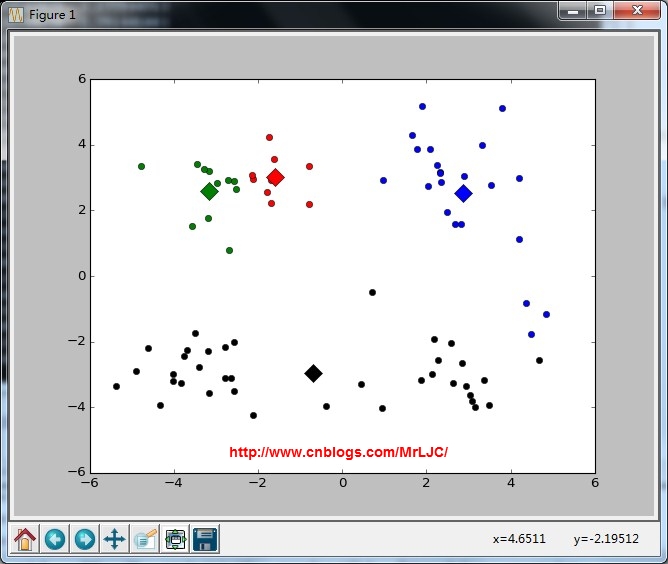
可视化结果
#coding=utf-
from numpy import * def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataMat.append(fltLine)
return dataMat #计算两个向量的距离,用的是欧几里得距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, ))) #随机生成初始的质心(ng的课说的初始方式是随机选K个点)
def randCent(dataSet, k):
n = shape(dataSet)[]
centroids = mat(zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(array(dataSet)[:,j]) - minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k,)
return centroids def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[]
clusterAssment = mat(zeros((m,)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf
minIndex = -
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**
print centroids
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,].A==cent)[]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=) #assign centroid to mean
return centroids, clusterAssment def show(dataSet, k, centroids, clusterAssment):
from matplotlib import pyplot as plt
numSamples, dim = dataSet.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for i in xrange(numSamples):
markIndex = int(clusterAssment[i, ])
plt.plot(dataSet[i, ], dataSet[i, ], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
for i in range(k):
plt.plot(centroids[i, ], centroids[i, ], mark[i], markersize = )
plt.show() def main():
dataMat = mat(loadDataSet('testSet.txt'))
myCentroids, clustAssing= kMeans(dataMat,)
print myCentroids
show(dataMat, , myCentroids, clustAssing) if __name__ == '__main__':
main()
机器学习笔记索引
k-means聚类算法python实现的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- K-means聚类算法及python代码实现
K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的) 1.概述 K-means算法是集简单和经典于一身的基于距离的聚类算法 采用距离作为相似性的评价指标,即认为两个对象的距离越近,其 ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
随机推荐
- COGS729. [网络流24题] 圆桌聚餐
«问题描述:假设有来自m 个不同单位的代表参加一次国际会议.每个单位的代表数分别为ri(i=1,2,3...m), .会议餐厅共有n张餐桌,每张餐桌可容纳c i(i=1,2...n) 个代表就餐.为了 ...
- 【整理】Word OpenXML常用标签
一.背景 最近在做关于Word内容自动标引,需要了解Word的底层结构,顺便梳理一下OpenXML的标签含义,方便后续开发,提高对OpenXML标签的查找效率,也是一个熟悉的过程. 二.内容 < ...
- <<< ajaxfileupload介绍
ajaxfileupload,jquery的一个异步上传插件,使用此插件你可以不用建立form,他会自动生成表单,且自动设置好enctype="multipart/form-data&quo ...
- C#成员函数直接调用和反射+委托的性能比较
using System; using System.Reflection; using System.Diagnostics; namespace Refl { class Test { publi ...
- WeakReference
https://msdn.microsoft.com/en-us/library/ms404247(v=vs.110).aspx http://stackoverflow.com/questions/ ...
- [Head First设计模式]饺子馆(冬至)中的设计模式——工厂模式
系列文章 [Head First设计模式]山西面馆中的设计模式——装饰者模式 [Head First设计模式]山西面馆中的设计模式——观察者模式 [Head First设计模式]山西面馆中的设计模式— ...
- linux shell脚本查找重复行/查找非重复行/去除重复行/重复行统计
转自:http://blog.sina.com.cn/s/blog_6797a6700101pdm7.html 去除重复行 sort file |uniq 查找非重复行 sort file |uniq ...
- tyvj1102 单词的划分
描述 有一个很长的由小写字母组成字符串.为了便于对这个字符串进行分析,需要将它划分成若干个部分,每个部分称为一个单词.出于减少分析量的目的,我们希望划分出的单词数越少越好.你就是来完成这一划分工作的. ...
- Sublime编辑器安装使用
用习惯了VS2010强大的IDE工具,但也被它折腾过.烦恼过,当vs加载超过万行的脚本代码时,界面半天才反应,经常卡死,电脑配置决定算得上顶呱呱. 不喜欢逆来顺受,于是选择了txt文本编辑器,最原始的 ...
- ASP.NET 导出数据表格
功能:可以实现导出整个数据表格或整个页面 public bool ExportGv(string fileType, string fileName) { bool ...