【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解。
第一步.随机生成质心
由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两个质心分为两堆就对了。如下图所示:
第二步.根据距离进行分类
红色和蓝色的点代表了我们随机选取的质心。既然我们要让这一堆点的分为两堆,且让分好的每一堆点离其质心最近的话,我们首先先求出每一个点离质心的距离。假如说有一个点离红色的质心比例蓝色的质心更近,那么我们则将这个点归类为红色质心这一类,反之则归于蓝色质心这一类,如图所示: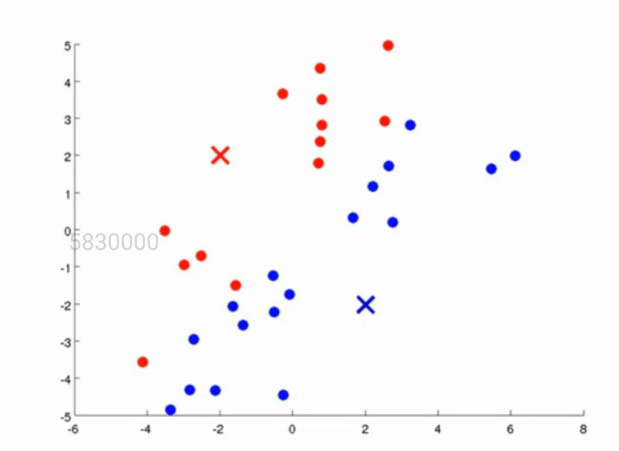
第三步.求出同一类点的均值,更新质心位置
在这一步当中,我们将同一类点的x\y的值进行平均,求出所有点之和的平均值,这个值(x,y)则是我们新的质心的位置,如图所示:
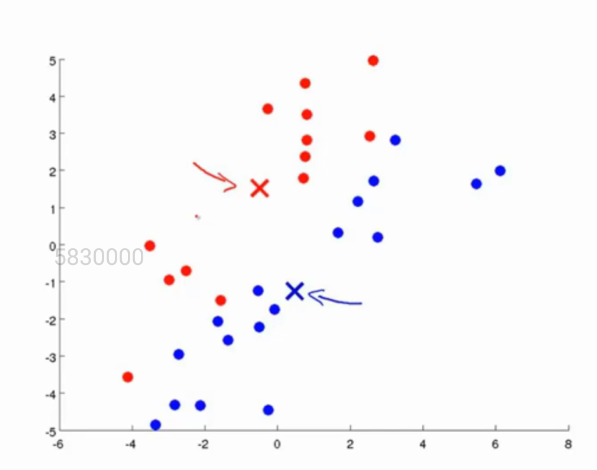
我们可以看到,质心的位置已经发生了改变。
第四步.重复第二步,第三步
我们重复第二步和第三部的操作,不断求出点对质心的最小值之后进行分类,分类之后再更新质心的位置,直到得到迭代次数的上限(这个迭代次数是可以我们自己设定的,比如10000次),或者在做了n次迭代之后,最后两次迭代质心的位置已经保持不变,如下图所示:

这个时候我们就将这一堆点按照它们的特征在没有监督的条件下,分成了两类了!!
五.如果面对多个特征确定的一个点的情况,又该如何实现聚类呢?
首先我们引入一个概念,那就是欧式距离,欧式距离是这样定义的,很容易理解:

很显然,欧式距离d(xi,xj)等于我们每一个点的特征去减去另一个点在该维度下的距离的平方和再开根号,十分容易理解。
我们也可以用另一种方式来理解kmeans算法,那就是使某一个点的和另一些点的方差做到最小则实现了聚类,如下图所示:
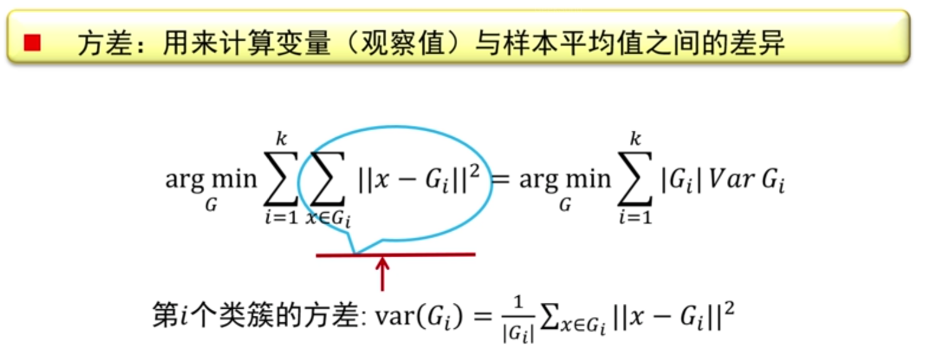
得解!
六:代码实现
我们现在使用Python语言来实现这个kmeans均值算法,首先我们先导入一个名叫make_blobs的数据集datasets,然后分别使用两个变量X,和y进行接收。X表示我们得到的数据,y表示这个数据应该被分类到的是哪一个类别当中,当然在我们实际的数据当中不会告诉我们哪个数据分在了哪一个类别当中,只会有X当中数据。在这里写代码的时候比较特殊,make_blobs库要求我们必须接受这两个参数,不能够只接受X这个数据参数,代码如下
plt.figure(figsize=(15,15))#规定我们绘图的大小为12*12 X, y=make_blobs(n_samples=1600,random_state=170)#一共取用1600个sample,同时状态设定为随机
#不知道这个状态随机是什么意思,只能查有关这个库的官方文档,同时这个数据集规定了是具备三个数据中心,也就是三个簇
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(X) plt.subplot(221)#表示四个方格当中的第一格
plt.scatter(X[:,0],X[:,1],c=y_pred)#表示数据的第0个和第1个维度,同时数据的colour与predict的结果有关
plt.title("The result of the Kmeans") plt.subplot(222)#表示四个方格当中的第一格
plt.scatter(X[:,0],X[:,1],c=y)
plt.title("The Real result of the Kmeans") array=np.array([[0.60834549,-0.63667341],[-0.40887178,-0.85253229]])
lashen=np.dot(X,array)
y_pred=KMeans(n_clusters=3,random_state=170).fit_predict(lashen) plt.subplot(223)#表示四个方格当中的第一格
plt.scatter(lashen[:,0],lashen[:,1],c=y_pred)#表示数据的第0个和第1个维度,同时数据的colour与predict的结果有关
plt.title("The Real result of the tranfored data")
我们在使用scatter函数进行绘图的时候会根据我们数据结的形状来编写相应的代码,这里我们所拿到的X数据集的行数是我们所指定的1600行,因为我们一共拿到了1600个数据,每一个数据仅有两个特征,也就是在XY轴当中的坐标,因此X是一个二维的ndarray对象(X是numpy当中的ndarray对象),我们可以打印出来看看这个数据的构成,如下图所示:

同时我们也可以看到y也是ndarray对象,由于我们在采集数据的时候仅仅接受了3个簇,make_blobs默认接受的是三个簇(或称cluster)的缘故,因此最后y的值只有0,1,2这三种可能。我们通过matplotlib绘图,绘制出我们分类的结果图,也就是上述代码的运行结果如下:
【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)的更多相关文章
- kmeans均值聚类算法实现
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- k-means均值聚类算法(转)
4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时候上述条件得不到满足,尤其是在 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- 聚类算法总结以及python代码实现
一.聚类(无监督)的目标 使同一类对象的相似度尽可能地大:不同类对象之间的相似度尽可能地小. 二.层次聚类 层次聚类算法实际上分为两类:自上而下或自下而上.自下而上的算法在一开始就将每个数据点视为一个 ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
随机推荐
- C#LeetCode刷题之#167-两数之和 II - 输入有序数组(Two Sum II - Input array is sorted)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3903 访问. 给定一个已按照升序排列 的有序数组,找到两个数使得 ...
- 从系统报表页面导出20w条数据到本地只用了4秒,我是如何做到的
背景 最近有个学弟找到我,跟我描述了以下场景: 他们公司内部管理系统上有很多报表,报表数据都有分页显示,浏览的时候速度还可以.但是每个报表在导出时间窗口稍微大一点的数据时,就异常缓慢,有时候多人一起导 ...
- 最后之作-Last Order(bushi
最近化学学有机选修,讲羧酸的时候我想到一个问题:不考虑空间异构.能否稳定存在等问题,某高级饱和脂肪酸有多少种同分异构体?做为一名退役的OIer,我将它抽象为了另一个问题:含\(n\)个\(C\)的饱和 ...
- MySQL查看没有主键的表
select table_schema, table_name from information_schema.tables where table_name not in (select disti ...
- DVWA-1.9之fileupload
low级 对文件类型没有任何约束,可直接上传"一句话木马"hack.php,连接冰蝎. 一句话木马 : medium级 源代码 if( ( $uploaded_type == &q ...
- 【算法•日更•第十期】树型动态规划&区间动态规划:加分二叉树题解
废话不多说,直接上题: 1580:加分二叉树 时间限制: 1000 ms 内存限制: 524288 KB提交数: 121 通过数: 91 [题目描述] 原题来自:NOIP 20 ...
- SpringSecurity权限管理系统实战—五、整合SpringSecurity(下)
系列目录 前言 上篇文章SpringSecurity整合了一半,这次把另一半整完,所以本篇的序号接着上一篇. 七.自定义用户信息 前面我们登录都是用的指定的用户名和密码或者是springsecurit ...
- ipvsadm服务报错/bin/bash: /etc/sysconfig/ipvsadm: No such file or directory
问题: 在执行重启ipvsadm服务时报错: 提示没有找到/etc/sysconfig/ipvsadm 解决: [root@lvs1 ~]# ipvsadm --save > /etc/sysc ...
- MariaDB二进制安装
下载二进制的MariaDB https://downloads.mariadb.org/mariadb/10.2.16/ 安装过程 下载&解压 下载到/tools安装到/application ...
- rlpyt(Deep Reinforcement Learning in PyTorch)
rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch Github:https://github.com/ast ...