MySQL让人又爱又恨的多表查询

1. 前言
在SQL开发当中,多表联查是绝对绕不开的一种技能。同样的查询结果不同的写法其运行效率也是千差万别。
在实际开发当中,我见过(好像还写过~)不少又长又臭的查询SQL,数据量一上来查个十几分钟那是家常便饭。
因此,深入理解SQL的多表查询机制,少写一些慢查询,应该可以少挨点骂。
2. 等值连接和非等值连接
2.1 等值连接
等值连接是在多表查询中最基础,也最简单的一种,其值为所有满足条件的笛卡尔积。
在from后面,哪个表写在前面结果中哪个表的值就先出现,如下:
select *
from student,
family
where student.family_id = family.id;

阿里在最新发布的Java开发手册中强制要求,只要涉及多个表,必须在列名前加表的别名(或表名)进行限定

2.2 非等值连接
非等值连接是通过a表中的值在b表中的某一个范围来进行的,能够很好的满足预设定好的分段统计需求。
非等值连接有两种写法,使用between...and...或大于号小于号
-- 第一种写法:使用between...and...
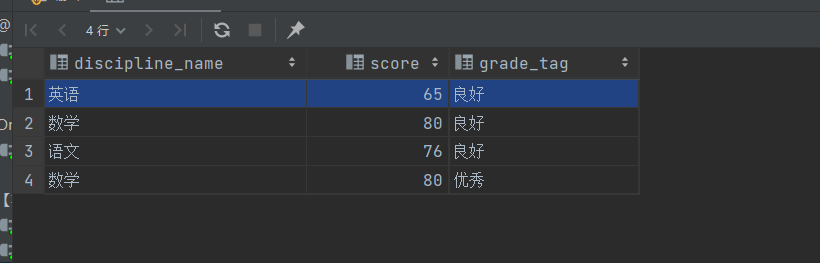
select a.discipline_name, a.score, b.grade_tag
from achievement a,
achievement_grade b
where a.score between b.lowest_score and b.highest_score;
-- 第二种写法,使用>=或<=
select a.discipline_name, a.score, b.grade_tag
from achievement a,
achievement_grade b
where a.score >= b.lowest_score
and a.score <= b.highest_score;
3. 自连接和非自连接
3.1 自连接
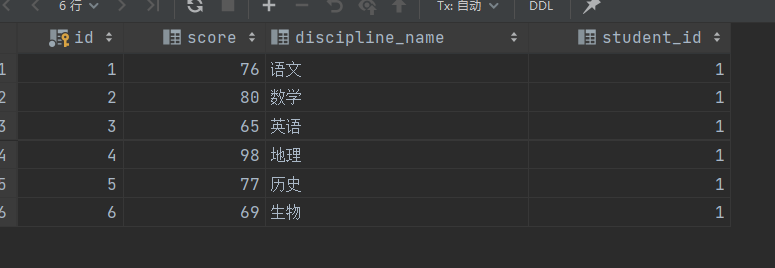
自连接,顾名思义就是同一张表自己跟自己连接,为了区分需要给表取不同的别名。如一张成绩表,需要查询所有分数比“语文”高的数据:
若不使用自连接,需要先通过查询语文的分数,然后再查询大于这个分数的数据。
具体可以按如下步骤进行查询:
-- 先查询语文的分数
select score from achievement where discipline_name = '语文';
-- 再查询分数比语文分数更高的数据
select * from achievement where score > 76;
而使用自连接,则可以在一条sq语句里完成查询:
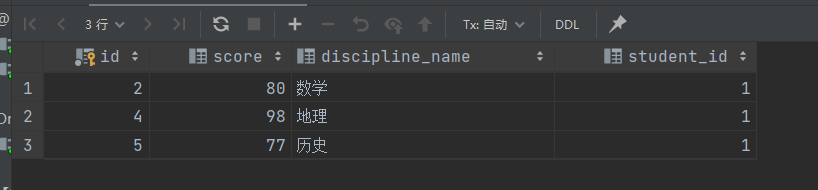
select a.*
from achievement a,
achievement b
where b.discipline_name = '语文'
and a.score > b.score;
3.2 非自连接
除自连接外,其他的都叫非自连接~~~
4. 内连接和外连接
内连接和外连接的区分本质上是另一种分类方法,如内连接就是等值连接。
内连接:合并具有同一列的两个或两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的
行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
- 左外连接:连接条件中左边的表也称为主表 ,右边的表称为从表 。
- 右外连接:连接条件中右边的表也称为主表 ,左边的表称为从表 。
- 全外连接
4.1 测试数据
测试用学生表student和家庭表family数据如下:
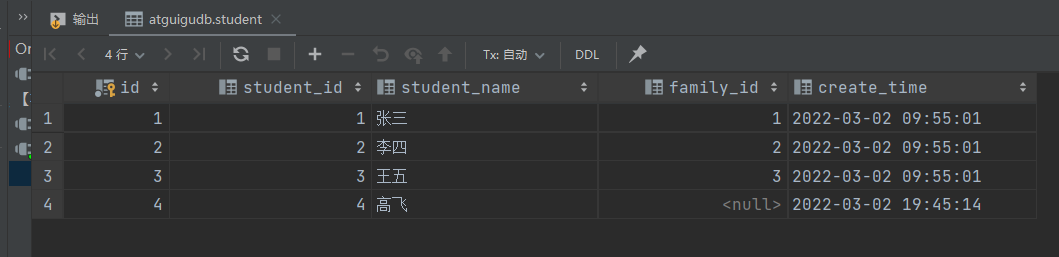
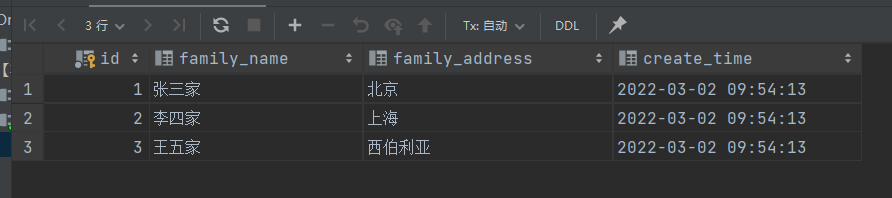
4.2 左外连接
-- 查出student中的所有数据,不满足的显示为null
-- 这里student在前面
select a.*
from student a
left join family b on a.family_id = b.id
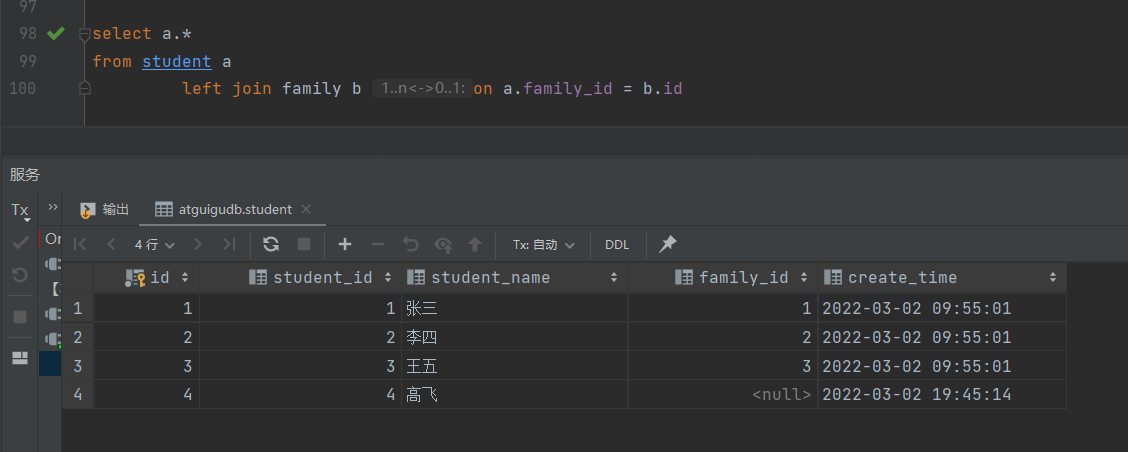
4.3 右外连接
-- 查出student中的所有数据,不满足的显示为null
-- 这里student在后面
select a.*
from family b
right join student a on b.id = a.family_id;
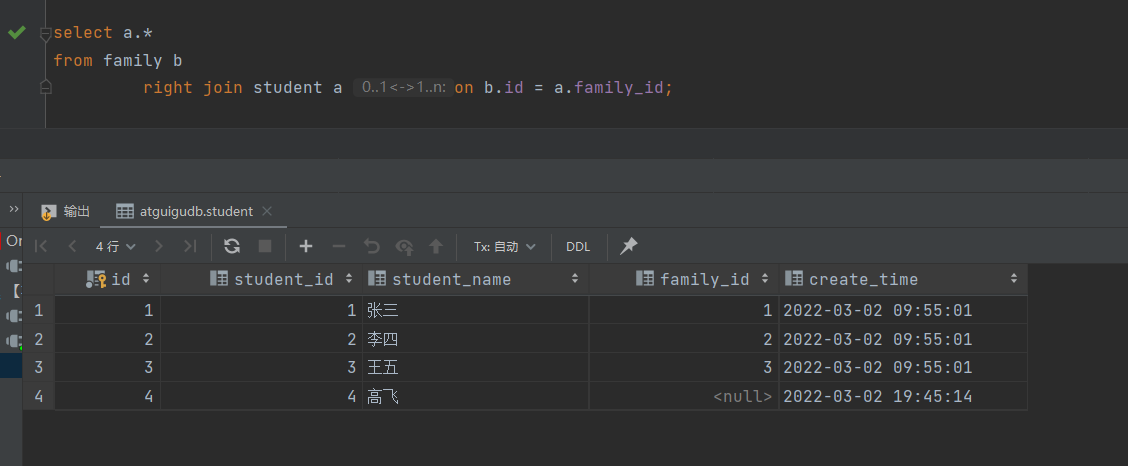
4.4 全外连接
很遗憾,MySQL不支持全外连接。
附录:测试数据SQL脚本
-- auto-generated definition
create table student
(
id int auto_increment
primary key,
student_id int null comment '学号',
student_name varchar(40) null comment '姓名',
family_id int null comment '家庭ID',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间'
)
comment '学生表';
create table family
(
id int auto_increment
primary key,
family_name varchar(40) null comment '家庭名称',
family_address varchar(40) null comment '家庭地址',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间'
)
comment '家庭表';
create table achievement
(
id int auto_increment
primary key,
score int null comment '分数',
discipline_name varchar(40) null comment '学科名称',
student_id int null comment '学号'
)
comment '成绩表';
create table achievement_grade
(
id int auto_increment
primary key,
grade_tag varchar(10) null comment '档次',
lowest_score int null comment '最低分',
highest_score int null comment '最高分',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间'
)
comment '分数档次表';
INSERT INTO achievement_grade (id, grade_tag, lowest_score, highest_score, create_time) VALUES (1, '不及格', 0, 60, '2022-03-02 11:44:01');
INSERT INTO achievement_grade (id, grade_tag, lowest_score, highest_score, create_time) VALUES (2, '良好', 60, 80, '2022-03-02 11:44:01');
INSERT INTO achievement_grade (id, grade_tag, lowest_score, highest_score, create_time) VALUES (3, '优秀', 80, 100, '2022-03-02 11:44:01');
INSERT INTO student (id, student_id, student_name, family_id, create_time) VALUES (1, 1, '张三', 1, '2022-03-02 09:55:01');
INSERT INTO student (id, student_id, student_name, family_id, create_time) VALUES (2, 2, '李四', 2, '2022-03-02 09:55:01');
INSERT INTO student (id, student_id, student_name, family_id, create_time) VALUES (3, 3, '王五', 3, '2022-03-02 09:55:01');
INSERT INTO student (id, student_id, student_name, family_id, create_time) VALUES (4, 4, '高飞', null, '2022-03-02 19:45:14');
INSERT INTO family (id, family_name, family_address, create_time) VALUES (1, '张三家', '北京', '2022-03-02 09:54:13');
INSERT INTO family (id, family_name, family_address, create_time) VALUES (2, '李四家', '上海', '2022-03-02 09:54:13');
INSERT INTO family (id, family_name, family_address, create_time) VALUES (3, '王五家', '西伯利亚', '2022-03-02 09:54:13');
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (1, 76, '语文', 1);
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (2, 80, '数学', 1);
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (3, 65, '英语', 1);
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (4, 98, '地理', 1);
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (5, 77, '历史', 1);
INSERT INTO achievement (id, score, discipline_name, student_id) VALUES (6, 69, '生物', 1);
微信搜索:『深海云帆』关注我的众号
或者加我微信:hqzmss,拉你入技术交流群
MySQL让人又爱又恨的多表查询的更多相关文章
- 谈谈Nancy中让人又爱又恨的Diagnostics【上篇】
前言 在Nancy中有个十分不错的功能-Diagnostics,可以说这个功能让人又爱又恨. 或许我们都做过下面这样的一些尝试: 记录某一个功能用到的相关技术信息 记录下网站的访问记录 全局配置某些框 ...
- mysql第四篇:数据操作之多表查询
mysql第四篇:数据操作之多表查询 一.多表联合查询 #创建部门 CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment ...
- Lambda-让人又爱又恨的“->"
写在前边 聊到Java8新特性,我们第一反应想到的肯定是Lambda表达式和函数式接口的出现.要说ta到底有没有在一定程度上"优化"了代码的简洁性呢?抑或是ta在一定程度上给程序员 ...
- MySQL:记录的增删改查、单表查询、约束条件、多表查询、连表、子查询、pymysql模块、MySQL内置功能
数据操作 插入数据(记录): 用insert: 补充:插入查询结果: insert into 表名(字段1,字段2,...字段n) select (字段1,字段2,...字段n) where ...; ...
- mysql第四篇:数据操作之单表查询
单表查询 一.简单查询 -- 创建表 DROP TABLE IF EXISTS `person`; CREATE TABLE `person` ( `id` ) NOT NULL AUTO_INCRE ...
- 让人又爱又恨的Lombok,到底该不该用
1 简介 Lombok,印尼的一个岛屿,龙目岛.但在Java的世界里,它是一个方便的类库,能提供很多便利,因此得到许多人的青睐.但也有不少反对声音.这是为什么呢? 之前去龙目岛拍的日落. 2 Lomb ...
- 让人又爱又恨的char(字符型)
今天来总结一下char型,平常写算法的时候对这个东西感觉都有一点绕着走,说到底还是对这部分的知识不熟悉所以有点怕他,不过以后不要怕,今天来总结一下 首先,说到字符型数据类型,char型,恩它是一种数据 ...
- 让人又爱又恨的this
this是个神奇的东西, 既可以帮助我们把模拟的类实例化. 又可以在事件绑定里准确指向触发元素. 还可以帮助我们在对象方法中操作对象的其他属性或方法. 甚至可以在使用apply.call.bing.f ...
- MySql 在cmd下的学习笔记 —— 有关多表查询的操作(内连接,外连接,交叉连接)
mysql> create table test5( -> id int, ) -> )engine myisam charset utf8; Query OK, rows affe ...
随机推荐
- AXAJ基础知识学习
AXAJ基础知识学习 博客首页 Ajax简介 ajxa全称是Asynchronous Javascript And XML ,就是异步的JS 和XML 通过Ajax可以再浏览器中向服务器发送异步请求, ...
- nacos集群开箱搭建
记录/朱季谦 nacos是一款易于构建云原生应用的动态服务发现.配置管理和服务管理平台,简单而言,它可以实现类似zookeeper做注册中心的功能,也就是可以在springcloud领域替代Eurek ...
- SpringCloud之使用Zookeeper作为注册中心
SpringCloud之使用Zookeeper作为注册中心 linux安装zookeeper 安装zookeeper 关闭linux防火墙 启动zookeeper 1 创建项目导入依赖和配置文件 &l ...
- 网络分层和TCP三次握手
它们就是 OSI 的七层模型,和 TCP/IP 的四层 / 五层模型.这两种模型的最大区别,就是前者在传输层和应用层之间,还有会话层和表示层,而后者没有. TCP三次握手: 位码即tcp标志位,有6种 ...
- python字符串系列--2
#!/usr/bin/python #coding=utf-8 first_name='tiger' last_name='gao' full_name= f"{first_name} {l ...
- python06day
Now代码1005行 回顾 字典的初识 查询速度快,{'name':'tangdaren'},存储大量关联型数据 键:int.str(bool tuple不常用)不可变的数据类型 值:任意数据类型 3 ...
- 阿里巴巴发布最佳实践 | 阿里巴巴DevOps实践指南
编者按:本文源自阿里云云效团队出品的<阿里巴巴DevOps实践指南>,扫描上方二维码或前往:https://developer.aliyun.com/topic/devops,下载完整版电 ...
- 你我都会遇到的需求:如何导出MySQL中的数据~ 简单!实用!
目录 你我都有的需求 方式一:tee 方式二:mysql_use_result 推荐阅读 一.给研发同学看的面试指南 二.MySQL-视频 三.进阶MySQL中间件-视频 四.白日梦的云原生-笔记 五 ...
- 最大公因数与最小公倍数-gcd&lcm
一.一些性质 \(gcd(a,b)=gcd(b,a)\) \(gcd(-a,b)=gcd(a,b)\) \(gcd(a,a)=|a|, gcd(a,0)=|a|\) \(gcd(a,1)=1\) \( ...
- JFrame 的层次结构 及 背景设置说明
感谢原文:https://blog.csdn.net/qq_32006373/article/details/49659129 一.JFrame 的层次结构 我们通过两个图来说明一下 JFrame 的 ...