Clickhouse 分布式表&本地表 &ClickHouse实现时序数据管理和挖掘
一、CK 分布式表和本地表
(1)CK是一个纯列式存储的数据库,一个列就是硬盘上的一个或多个文件(多个分区有多个文件),关于列式存储这里就不展开了,总之列存对于分析来讲好处更大,因为每个列单独存储,所以每一列数据可以压缩,不仅节省了硬盘,还可以降低磁盘IO。
(2)CK是多核并行处理的,为了充分利用CPU资源,多线程和多核必不可少,同时向量化执行也会大幅提高速度。
(3)提供SQL查询接口,CK的客户端连接方式分为HTTP和TCP,TCP更加底层和高效,HTTP更容易使用和扩展,一般来说HTTP足矣,社区已经有很多各种语言的连接客户端。
(4)CK不支持事务,大数据场景下对事务的要求没这么高。
(5)不建议按行更新和删除,CK的删除操作也会转化为增加操作,粒度太低严重影响效率。
生产环境中通常是使用集群部署,CK的集群与Hadoop等集群稍微有些不一样。如图所示,CK集群共包含以下几个关键概念:

(1)CK实例。可以一台主机上起多个CK实例,端口不同即可,也可以一台主机一个CK实例。
(2)分片。数据的水平划分,例如随机划分时,图5中每个分片各有大约一半数据。
(3)副本。数据的冗余备份,同时也可作为查询节点。多个副本同时提供数据查询服务,能够加快数据的查询效率,提高并发度。图5中CK实例1和示例3存储了相同数据。
(4)多主集群模式。CK的每个实例都可以叫做副本,每个实体都可以提供查询,不区分主从,只是在写入数据时会在每个分片里临时选一个主副本,来提供数据同步服务,具体见下文中的写入过程。
ck的表分为两种:
分布式表
一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表. 分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给用户.
本地表:
实际存储数据的表
1、Replication & Sharding

2、一般 不写分布式表的原因
- 分布式表接收到数据后会将数据拆分成多个parts, 并转发数据到其它服务器, 会引起服务器间网络流量增加、服务器merge的工作量增加, 导致写入速度变慢, 并且增加了Too many parts的可能性.
- 数据的一致性问题, 先在分布式表所在的机器进行落盘, 然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验, 而且在分布式表所在机器时如果机器出现down机, 会存在数据丢失风险.
- 数据写入默认是异步的,短时间内可能造成不一致.
- 对zookeeper的压力比较大(待验证). 没经过正式测试, 只是看到了有人提出.
3、Replicated Table & ReplicatedMergeTree Engines
ClickHouse的副本机制之所以叫“复制表”,是因为它工作在表级别,而不是集群级别(如HDFS)。也就是说,用户在创建表时可以通过指定引擎选择该表是否高可用,每张表的分片与副本都是互相独立的。
目前支持复制表的引擎是ReplicatedMergeTree引擎族,它与平时最常用的MergeTree引擎族是正交的,如下图所示。

不同于HDFS的副本机制(基于集群实现), Clickhouse的副本机制是基于表实现的. 用户在创建每张表的时候, 可以决定该表是否高可用.
Local_table
CREATE TABLE IF NOT EXISTS {local_table} ({columns})
ENGINE = ReplicatedMergeTree('/clickhouse/tables/#_tenant_id_#/#__appname__#/#_at_date_#/{shard}/hits', '{replica}')
partition by toString(_at_date_) sample by intHash64(toInt64(toDateTime(_at_timestamp_)))
order by (_at_date_, _at_timestamp_, intHash64(toInt64(toDateTime(_at_timestamp_))))
ReplicatedMergeTree
CREATE TABLE IF NOT EXISTS test.events_local ON CLUSTER '{cluster}' (
ts_date Date,
ts_date_time DateTime,
user_id Int64,
event_type String,
site_id Int64,
groupon_id Int64,
category_id Int64,
merchandise_id Int64,
search_text String
-- A lot more columns...
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test/events_local','{replica}')
PARTITION BY ts_date
ORDER BY (ts_date_time,site_id,event_type)
SETTINGS index_granularity = 8192;
其中,ON CLUSTER语法表示分布式DDL,即执行一次就可在集群所有实例上创建同样的本地表。集群标识符{cluster}、分片标识符{shard}和副本标识符{replica}来自之前提到过的复制表宏配置,即config.xml中<macros>一节的内容,配合ON CLUSTER语法一同使用,可以避免建表时在每个实例上反复修改这些值。
ReplicatedMergeTree引擎族接收两个参数:
- ZK中该表相关数据的存储路径,ClickHouse官方建议规范化,如上面的格式
/clickhouse/tables/{shard}/[database_name]/[table_name]。 - 副本名称,一般用
{replica}即可。
支持复制表的引擎都是ReplicatedMergeTree引擎族, 具体可以查看官网:
作者:张永清 来源于博客园https://www.cnblogs.com/laoqing/p/15954171.html
ReplicatedMergeTree引擎族接收两个参数:
- ZK中该表相关数据的存储路径, ClickHouse官方建议规范化, 例如:
/clickhouse/tables/{shard}/[database_name]/[table_name]. - 副本名称, 一般用
{replica}即可.
ReplicatedMergeTree引擎族非常依赖于zookeeper, 它在zookeeper中存储了大量的数据:
表结构信息、元数据、操作日志、副本状态、数据块校验值、数据part merge过程中的选主信息...
同时, zookeeper又在复制表急之下扮演了三种角色:
元数据存储、日志框架、分布式协调服务
可以说当使用了ReplicatedMergeTree时, zookeeper压力特别重, 一定要保证zookeeper集群的高可用和资源.
3.1. 数据同步的流程
internal_replication配置项为true)。即先写入一个副本,再通过config.xml中配置的interserver HTTP port端口(默认是9009)将数据复制到其他实例上去,同时更新ZK集群上记录的信息。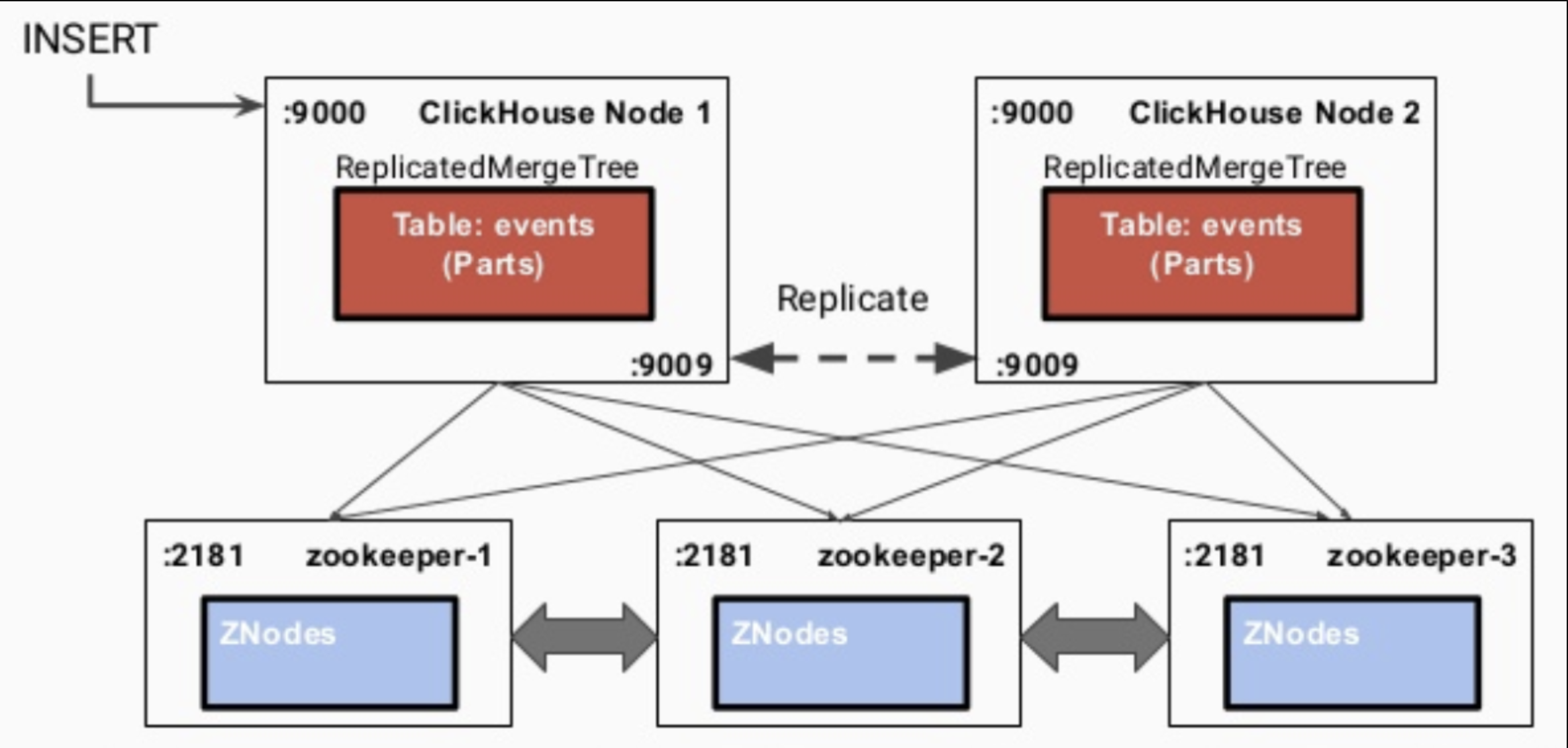
- 写入到一个节点
- 通过
interserver HTTP port端口同步到其他实例上 - 更新zookeeper集群记录的信息
3.2. 重度依赖Zookeeper导致的问题
ck的replicatedMergeTree引擎方案有太多的信息存储在zk上, 当数据量增大, ck节点数增多, 会导致服务非常不稳定, 目前我们的ck集群规模还小, 这个问题还不严重, 但依旧会出现很多和zk有关的问题(详见遇到的问题).
实际上 ClickHouse 把 ZK 当成了三种服务的结合, 而不仅把它当作一个 Coordinate service(协调服务), 可能这也是大家使用 ZK 的常用用法。ClickHouse 还会把它当作 Log Service(日志服务),很多行为日志等数字的信息也会存在 ZK 上;还会作为表的 catalog service(元数据存储),像表的一些 schema 信息也会在 ZK 上做校验,这就会导致 ZK 上接入的数量与数据总量会成线性关系。
作者:张永清 来源于博客园https://www.cnblogs.com/laoqing/p/15954171.html
目前针对这个问题, clickhouse社区提出了一个mini checksum方案, 但是这并没有彻底解决 znode 与数据量成线性关系的问题. 目前看到比较好的方案是字节的:
我们就基于 MergeTree 存储引擎开发了一套自己的高可用方案。我们的想法很简单,就是把更多 ZK 上的信息卸载下来,ZK 只作为 coordinate Service。只让它做三件简单的事情:行为日志的 Sequence Number 分配、Block ID 的分配和数据的元信息,这样就能保证数据和行为在全局内是唯一的。
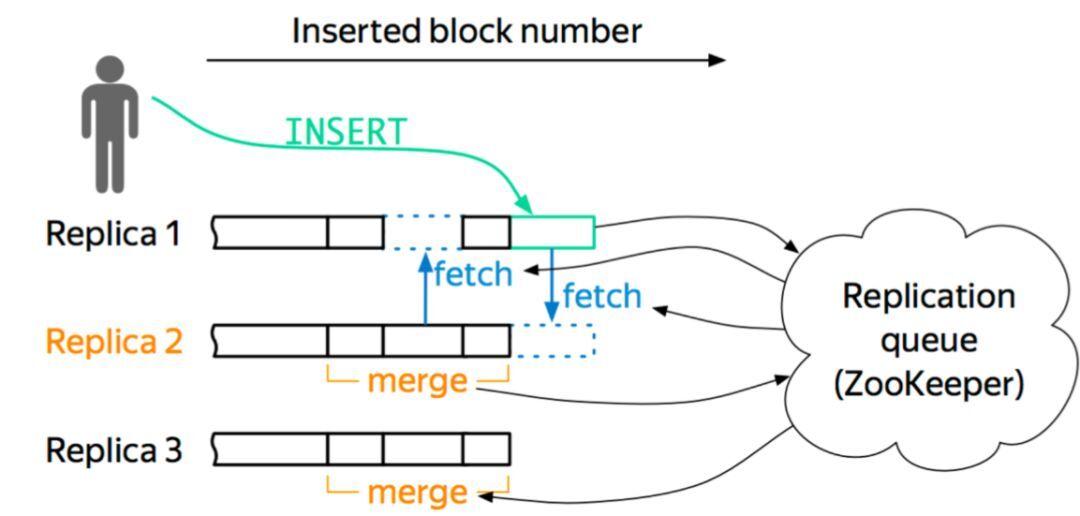
关于节点,它维护自身的数据信息和行为日志信息,Log 和数据的信息在一个 shard 内部的副本之间,通过 Gossip 协议进行交互。我们保留了原生的 multi-master 写入特性,这样多个副本都是可以写的,好处就是能够简化数据导入。图 6 是一个简单的框架图。
以这个图为例,如果往 Replica 1 上写,它会从 ZK 上获得一个 ID,就是 Log ID,然后把这些行为和 Log Push 到集群内部 shard 内部活着的副本上去,然后当其他副本收到这些信息之后,它会主动去 Pull 数据,实现数据的最终一致性。我们现在所有集群加起来 znode 数不超过三百万,服务的高可用基本上得到了保障,压力也不会随着数据增加而增加。
4、Distributed Table & Distributed Engine
ClickHouse分布式表的本质并不是一张表,而是一些本地物理表(分片)的分布式视图,本身并不存储数据。
支持分布式表的引擎是Distributed,建表DDL语句示例如下,_all只是分布式表名比较通用的后缀而已。
CREATE TABLE IF NOT EXISTS test.events_all ON CLUSTER sht_ck_cluster_1
AS test.events_local
ENGINE = Distributed(sht_ck_cluster_1,test,events_local,rand());
Distributed引擎需要以下几个参数:
- 集群标识符
注意不是复制表宏中的标识符,而是<remote_servers>中指定的那个。 - 本地表所在的数据库名称
- 本地表名称
- (可选的)分片键(sharding key)
该键与config.xml中配置的分片权重(weight)一同决定写入分布式表时的路由,即数据最终落到哪个物理表上。它可以是表中一列的原始数据(如site_id),也可以是函数调用的结果,如上面的SQL语句采用了随机值rand()。注意该键要尽量保证数据均匀分布,另外一个常用的操作是采用区分度较高的列的哈希值,如intHash64(user_id)。
在分布式表上执行查询的流程简图如下所示。发出查询后,各个实例之间会交换自己持有的分片的表数据,最终汇总到同一个实例上返回给用户。

而在写入时,我们有两种选择:一是写分布式表,二是写underlying的本地表。孰优孰劣呢?
直接写分布式表的优点自然是可以让ClickHouse控制数据到分片的路由,缺点就多一些:
- 数据是先写到一个分布式表的实例中并缓存起来,再逐渐分发到各个分片上去,实际是双写了数据(写入放大),浪费资源;
- 数据写入默认是异步的,短时间内可能造成不一致;
- 目标表中会产生较多的小parts,使merge(即compaction)过程压力增大。
相对而言,直接写本地表是同步操作,更快,parts的大小也比较合适,但是就要求应用层额外实现sharding和路由逻辑,如轮询或者随机等。
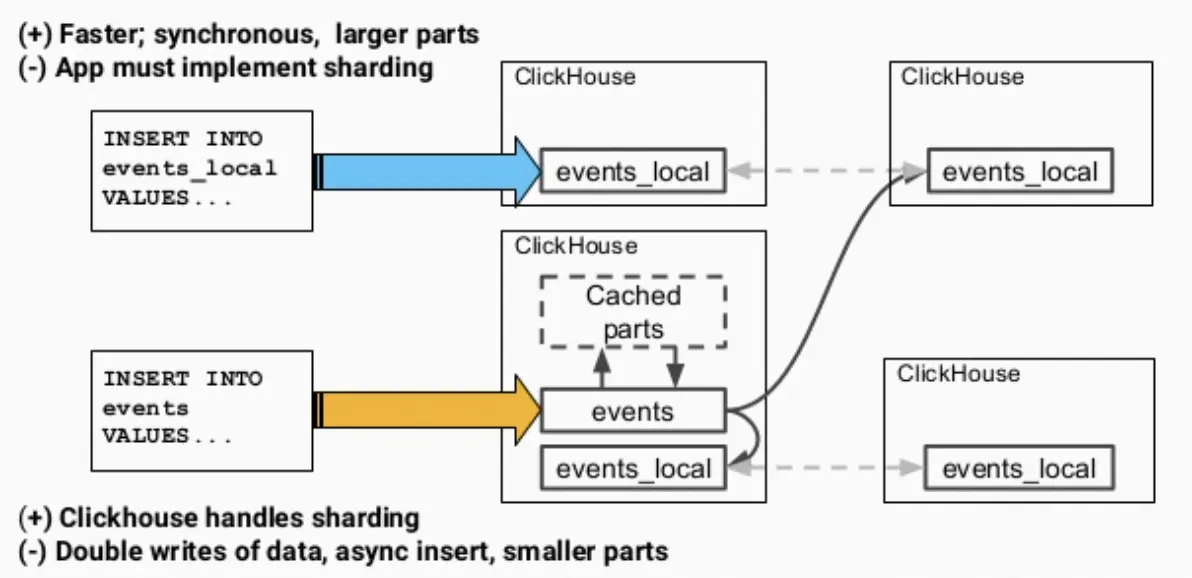
在生产环境中总是推荐写本地表、读分布式表,采用了随机路由,部分代码如下
private Request buildRequest(ClickhouseRequestBlank requestBlank) {
String resultCSV = String.join(" , ", requestBlank.getValues());
String query = String.format("INSERT INTO %s VALUES %s", requestBlank.getTargetTable(), resultCSV);
String host = sinkSettings.getClickhouseClusterSettings().getRandomHostUrl();
BoundRequestBuilder builder = asyncHttpClient
.preparePost(host)
.setHeader(HttpHeaders.Names.CONTENT_TYPE, "text/plain; charset=utf-8")
.setBody(query);
if (sinkSettings.getClickhouseClusterSettings().isAuthorizationRequired()) {
builder.setHeader(HttpHeaders.Names.AUTHORIZATION, "Basic " + sinkSettings.getClickhouseClusterSettings().getCredentials());
}
return builder.build();
}
public String getRandomHostUrl() {
currentHostId = ThreadLocalRandom.current().nextInt(hostsWithPorts.size());
return hostsWithPorts.get(currentHostId);
}
完整代码参考:https://github.com/ivi-ru/flink-clickhouse-sink
作者:张永清 来源于博客园https://www.cnblogs.com/laoqing/p/15954171.html
二、ClickHouse实现时序数据管理和挖掘
ClickHouse在时序数据库上的能力体现:
(1)时间:时间是必不可少的,按照时间分区能够大幅降低数据扫描范围;
(2)过滤:对条件的过滤一般基于某些列,对于列式存储来说优势明显;
(3)降采样:对于时序来说非常重要的功能,可以通过聚合实现,CK自带时间各个粒度的时间转换函数以及强大的聚合能力,可以满足要求;
(4)分析挖掘:可以开发扩展的函数来支持。
另外CK作为一个大数据系统,也满足以下基础要求:
(1)高吞吐写入;
(2)海量数据存储:冷热备份,TTL;
(3)高效实时的查询;
(4)高可用;
(5)可扩展性:可以实现自定义开发;
(6)易于使用:提供了JDBC和HTTP接口;
(7)易于维护:数据迁移方便,恢复容易,后续可能会将依赖的ZK去掉,内置分布式功能。
时序查询场景会有很多聚合查询,对于特定场景,如果使用的非常频繁且数据量非常大,我们可以采用物化视图进行预聚合,然后查询物化视图
未完待续,敬请期待.....
参考#
Clickhouse 分布式表&本地表 &ClickHouse实现时序数据管理和挖掘的更多相关文章
- Clickhouse 分布式表&本地表
CK 分布式表和本地表 ck的表分为两种: 分布式表 一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表. 分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给 ...
- clickhouse分布式集群
一.环境准备: 主机 系统 应用 ip ckh-01 centos 8 jdk,zookeeper,clickhouse 192.168.205.190 ckh-02 centos 8 jdk,zoo ...
- Clickhouse副本表以及分布式表简单实践
集群配置: 192.168.0.106 node3 192.168.0.101 node2 192.168.0.103 node1 zookeeper配置忽略,自行实践! node1配置: <? ...
- ClickHouse 分布式高可用集群搭建(转载)
一.ClickHouse安装方式: 源码编译安装 Docker安装 RPM包安装 为了方便使用,一般采用RPM包方式安装,其他两种方式这里不做说明. 二.下载安装包 官方没有提供rpm包,但是Alti ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
创建和分布表 要创建分布式表,您需要首先定义表 schema. 为此,您可以使用 CREATE TABLE 语句定义一个表,就像使用常规 PostgreSQL 表一样. CREATE TABLE ht ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
如前几节所述,Citus 是一个扩展,它扩展了最新的 PostgreSQL 以进行分布式执行.这意味着您可以在 Citus 协调器上使用标准 PostgreSQL SELECT 查询进行查询. Cit ...
- 分布式 PostgreSQL 集群(Citus),分布式表中的分布列选择最佳实践
确定应用程序类型 在 Citus 集群上运行高效查询要求数据在机器之间正确分布.这因应用程序类型及其查询模式而异. 大致上有两种应用程序在 Citus 上运行良好.数据建模的第一步是确定哪些应用程序类 ...
- 在 Kubernetes 上快速测试 Citus 分布式 PostgreSQL 集群(分布式表,共置,引用表,列存储)
准备工作 这里假设,你已经在 k8s 上部署好了基于 Citus 扩展的分布式 PostgreSQL 集群. 查看 Citus 集群(kubectl get po -n citus),1 个 Coor ...
- ClickHouse高可用集群的配置
上一篇文章写过centos 7下clickhouse rpm包安装和基本的目录结构,这里主要介绍clickhouse高可用集群的部署方案,因为对于默认的分布式表的配置,每个分片只有一份,这样如果挂掉一 ...
随机推荐
- Java的八大基本数据类型
Java的八大基本数据类型 前言 Bit是计算机存储数据的基本单元,bit叫做位,也被称作比特位. Byte意为字节,1Byte=1字节,一字节可以存储八个二进制位的数字, 即为1Byte=8bit. ...
- jsp文本框输入限制问题
1.jsp文本窗口实现控制输入格式 <input onkeyup = "value=value.replace(/[\W]/g,'')" onbeforepaste=&quo ...
- 一文读懂mysql权限系统
前言: MySQL权限系统的主要功能是证实连接到一台给定主机的用户,并且赋予该用户在数据库上的SELECT.INSERT.UPDATE和DELETE权限.附加的功能包括有匿名的用户并对于MySQL特定 ...
- gin中设置和获取cookie
package main import ( "fmt" "github.com/gin-gonic/gin" ) func main() { router := ...
- 由浅入深,66条JavaScript面试知识点
前言 我只想面个CV工程师,面试官偏偏让我挑战造火箭工程师,加上今年这个情况更是前后两男,但再难苟且的生活还要继续,饭碗还是要继续找的.在最近的面试中我一直在总结,每次面试回来也都会复盘,下面是我这几 ...
- hive DML 操作
数据导入 向表中装载数据(Load) 1.语法 load data [local] inpath '数据的 path' [overwrite] into table student [partitio ...
- 【建议收藏】Redis超详细入门教程大杂烩
写在前边 Redis入门的整合篇.本篇也算是把2021年redis留下来的坑填上去,重新整合了一翻,点击这里,回顾我的2020与2021~一名大二后台练习生 NoSQL NoSQL(NoSQL = N ...
- 「JOISC 2014 Day1」巴士走读
「JOISC 2014 Day1」巴士走读 将询问离线下来. 从终点出发到起点. 由于在每个点(除了终点)的时间被过来的边固定,因此如果一个点不被新的边更新,是不会发生变化的. 因此可以按照时间顺序, ...
- AGC008 部分简要题解
F 不妨前考虑 \(70 \%\) 的部分分,\(s\) 全部为 \(1\). 首先可以发现这个问题之所以困难是因为同一个联通子树可能可以被多个中心节点导出. 因此,我们考虑对于一个合法的联通子树,在 ...
- 实现表单input文本框不可编辑的三种方法
感谢原文作者:青灯夜游 原文链接:https://www.php.cn/div-tutorial-413133.html 目录 问题 实现方式 1.οnfοcus=this.blur() 2.read ...