Hive——安装以及概述
一、hive的安装
注意:安装hive的前提要安装好MySQL和Hadoop
Hadoop安装:https://www.cnblogs.com/lmandcc/p/15306163.html
MySQL的安装:https://www.cnblogs.com/lmandcc/p/15224657.html
安装hive首先需要启动Hadoop
1、解压hive的安装包
tar -zxvf apache-hive-1.2.1-bin.tar.gz
修改下目录名称
mv apache-hive-1.2.1-bin hive-1.2.1
2、备份配置文件
cd /usr/local/soft/hive-1.2.1/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
3、修改配置文件
vim hive.env.sh
新加三行配置(路径不同就更具实际情况来):
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HIVE_HOME=/usr/local/soft/hive-1.2.1
4、修改配置文件
vim hive-site.xml
修改对应的配置参数(注意:是修改不是添加)
1 <property>
2 <name>javax.jdo.option.ConnectionURL</name>
3 <value>jdbc:mysql://master:3306/hive?characterEncoding=UTF-8&createDatabaseIfNotExist=true&useSSL=false</value>
4 </property>
5 <property>
6 <name>javax.jdo.option.ConnectionDriverName</name>
7 <value>com.mysql.jdbc.Driver</value>
8 </property>
9 <property>
10 <name>javax.jdo.option.ConnectionUserName</name>
11 <value>root</value>
12 </property>
13 <property>
14 <name>javax.jdo.option.ConnectionPassword</name>
15 <value>123456</value>
16 </property>
17 <property>
18 <name>hive.querylog.location</name>
19 <value>/usr/local/soft/hive-1.2.1/tmp</value>
20 </property>
21 <property>
22 <name>hive.exec.local.scratchdir</name>
23 <value>/usr/local/soft/hive-1.2.1/tmp</value>
24 </property>
25 <property>
26 <name>hive.downloaded.resources.dir</name>
27 <value>/usr/local/soft/hive-1.2.1/tmp</value>
28 </property>
5、复制mysql连接工具包到hive/lib
cd /usr/local/soft/hive-1.2.1
cp /usr/local/moudle/mysql-connector-java-5.1.49.jar /usr/local/soft/hive-1.2.1/lib/
6、删除hadoop中自带的jline-2.12.jar位置在/usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/jline-2.12.jar
rm -rf /usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/jline-2.12.jar
7、把hive自带的jline-2.12.jar复制到hadoop中 hive中所在位置 /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar
cp /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar /usr/local/soft/hadoop-2.7.6/share/hadoop/yarn/lib/
8、启动
hive
二、hive的概述
1、hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
2、Hive本质:将HQL转化成MapReduce程序
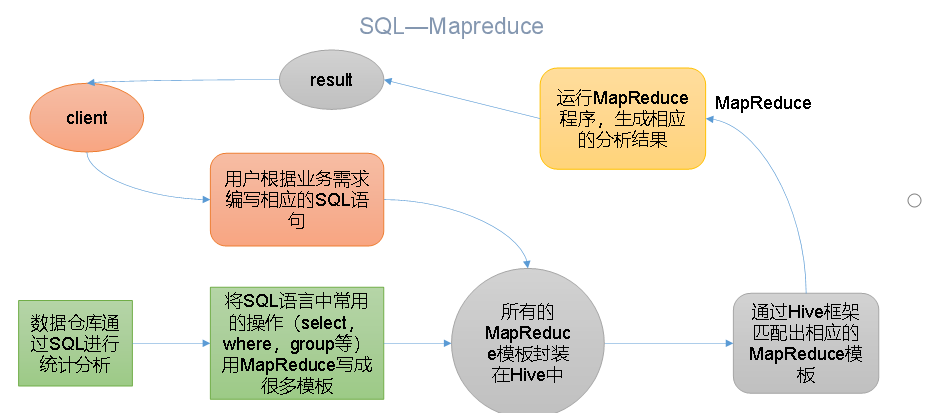
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
3、hive的优点
(1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写MapReduce,减少开发人员的学习成本。
(3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
(4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
(5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
4、hive的缺点
1)Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2)Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
5、Hive架构原理

1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4)驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
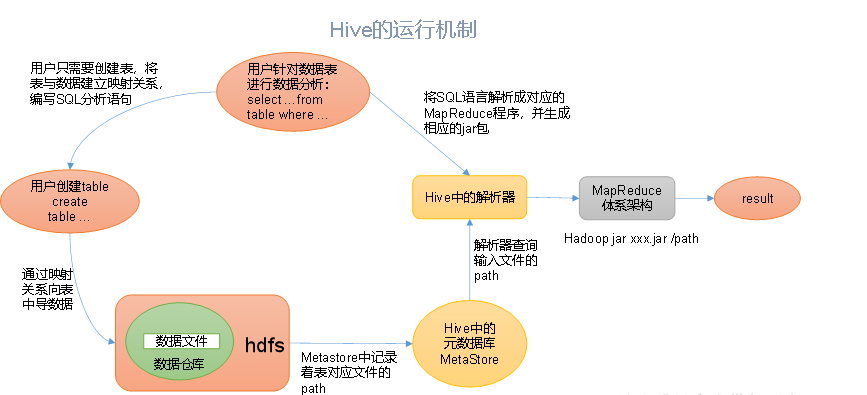
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive——安装以及概述的更多相关文章
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hive安装、配置和使用
Hive概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. Hive本质是:将HQL转化成MapReduce程序. Hive处理的数据存储 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- hive安装--设置mysql为远端metastore
作业任务:安装Hive,有条件的同学可考虑用mysql作为元数据库安装(有一定难度,可以获得老师极度赞赏),安装完成后做简单SQL操作测试.将安装过程和最后测试成功的界面抓图提交 . 已有的当前虚拟机 ...
- Hive安装与部署集成mysql
前提条件: 1.一台配置好hadoop环境的虚拟机.hadoop环境搭建教程:稍后补充 2.存在hadoop账户.不存在的可以新建hadoop账户安装配置hadoop. 安装教程: 一.Mysql安装 ...
- 【转】 hive安装配置及遇到的问题解决
原文来自: http://blog.csdn.net/songchunhong/article/details/51423823 1.下载Hive安装包apache-hive-1.2.1-bin.ta ...
- Hadoop之hive安装过程以及运行常见问题
Hive简介 1.数据仓库工具 2.支持一种与Sql类似的语言HiveQL 3.可以看成是从Sql到MapReduce的映射器 4.提供shall.Jdbc/odbc.Thrift.Web等接口 Hi ...
- Hive安装与配置详解
既然是详解,那么我们就不能只知道怎么安装hive了,下面从hive的基本说起,如果你了解了,那么请直接移步安装与配置 hive是什么 hive安装和配置 hive的测试 hive 这里简单说明一下,好 ...
- hive安装详解
1.安装MYSQL simon@simon-Lenovo-G400:~$ sudo apt-get install mysql-server simon@simon-Lenovo-G400:~$ su ...
随机推荐
- 为什么网络损伤仪WANsim中没有流量通过
在使用网络损伤仪 WANsim 的过程中,有时候发现网损仪中没有流量通过.有些小伙伴可能会想:自己所有配置都是正确的 ,为什么会没有流量通过呢? 有可能,是你忽略了一些东西. 下面,我总结了一些导致网 ...
- 剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
剑指 Offer 68 - I. 二叉搜索树的最近公共祖先 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先. 百度百科中最近公共祖先的定义为:"对于有根树 T 的两个结点 p.q ...
- 多线程之旅(9)_如何安全的取消正在执行的线程——附C#源码
参考网址: https://blog.csdn.net/yangwohenmai1/article/details/90404497 当线程能流畅安全的自动运行后,我们就要考虑一些更风骚的操作,就是如 ...
- java Math.random()生成从n到m的随机整数
Java中Math类的random()方法可以生成[0,1)之间的随机浮点数.而double类型数据强制转换成int类型,整数部分赋值给int类型变量,小数点之后的小数部分将会丢失. 如果要生成[0, ...
- git 的指定参考教程
https://www.runoob.com/git/git-create-repository.html
- SoutceTree用户名或者密码输入错误解决方案
soutceTree在拉取代码时候需要输入账户名或者密码,如果一时输入错了,可以这样修改: 1.找到这个目录:C:\Users\Administrator\AppData\Local\Atlassia ...
- (四)HXDZ-30102-ACC检测心率血氧数据并通过串口助手显示
主要参考模块说明书 写在前面的话 硬件原理我是真的搞不明白,所以心率血氧传感器数据检测就是模块卖家自带的代码... 我使用HXDZ-30102-ACC传感器也是偶然在网上检索到的,集成心率血氧和三轴加 ...
- 如果服务器数据更新了,CDN的数据是怎么及时更新的
A:cdn一般用来存静态资源.拿网站来说,当用户访问网站时静态资源从cdn加载.cdn向后段源服务器请求资源并缓存,这个请求过程是周期性的,自动的,称为回源. 当你更新了一个文件,现在正巧还没到cdn ...
- 证明n个正数的算术平均数不小于它们的几何平均数
- 10分钟学会Visual Studio将自己创建的类库打包到NuGet进行引用(net,net core,C#)
前言 NuGet就是一个包(package)管理平台,确切的说是 .net平台的包管理工具,它提供了一系列客户端用于生成,上传和使用包(package),以及一个用于存储所有包的中心库. 对于一个现代 ...