文本图Tranformer在文本分类中的应用
原创作者 | 苏菲
论文来源:
https://aclanthology.org/2020.emnlp-main.668/
论文题目:
Text Graph Transformer for Document Classification (文本图Tranformer在文本分类中的应用)
论文作者:
Haopeng Zhang Jiawei Zhang
01 引言
文本分类是自然语言处理中的基本任务之一,而图神经网络(GNN)技术可以描述词语、文本以及语料库,最近研究者将GNN应用到抓取语料库中单词全局共现关系中。但此前的图神经网络引用存在不能扩展到大型语料库、且忽略文本图异质性的缺陷。
在此背景下,本文作者引入了一个基于异质性图神经网络的新Transformer方法(文本图Transformer,或者TG-Transformer)。
深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)已经被用于文本特征的学习中,取代了一些传统的特征生成(如n元语法特征、词袋特征)。
最近,一些学者又把图神经网络(GNN)用于文本分类的研究中,但论文作者指出了其中的一些缺陷,并提出使用文本图Transformer,一个异质性的图神经网络用于文本分类问题。而且这是一种可扩展的基于图的方法。
02 方法论
作者首先用图表示一个已知语料库的异质性文本图,然后引入文本图的采样方法(Sampling)从文本图中生成小批量子图。这些小批量子图可以送入TG-Transformer中,用于学习文本分类的有效节点特征,总体框架如图1所示。
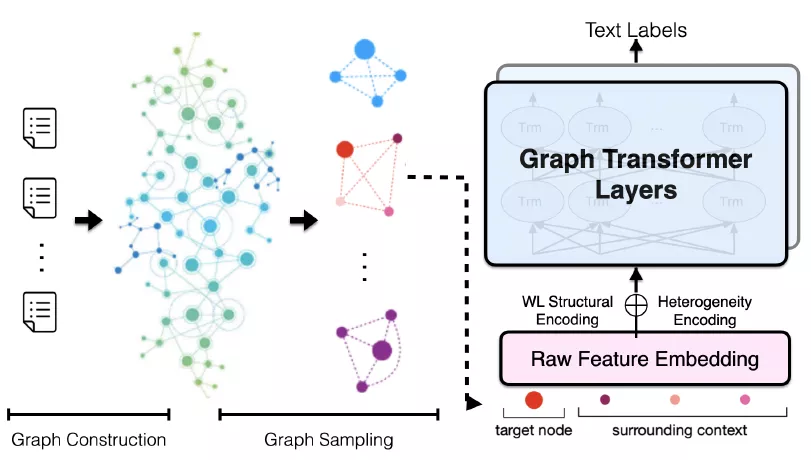
图1 TG-Tranformer的总体框架
(1)建立文本图(Text Graph)
为了获得语料库中词语的全局共现,论文作者建立了一个异质性文本图G(异质图比同质图更贴近于现实世界),G =(U; V; E;F)。 所谓异质性就是图中不只包含一种类型的节点或边(nodes or edges)。
在G中建立了两种类型的节点,一种是文本节点(U),代表语料库中的所有文档;另一种是词语节点(V),代表语料库词汇表中的所有词语。一种是词语节点(U),代表语料库词汇表中的所有词语;另一种是文档节点(V),代表语料库中的所有文档。
文本图中也包含了两种类型的边:一种是词语-文档边,用大写E来表示;另一种是词语-词语边,用大写字母F来表示。词语-文档边的权重由TF-IDF方法来计算得到。而词语-词语边的权重通过计算点间互信息(point-wise mutual information)得到,该互信息基于在语料库中滑动窗口的局部词语共现来获得。点间互信息的计算公式如下:
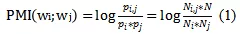
其中,
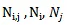
分别是语料库中滑窗的数目,
即只含词语

只含词语
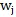
既包含词语
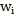
又包含词语
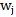
N是在语料库中滑窗的总数目。
(2)文本图的采样
为了减少计算成本和内存成本,论文作者提出了一种文本图的采样方法,而不是用整个文本图去学习。TG-Transformer的训练输入是小批量的采样子图,这种采样方法是作为无监督学习的一个预处理步骤,以控制模型的学习时间成本,并可以扩展到大规模语料库中。
首先,基于PpageRrank算法,计算了图的亲密矩阵S(intimacy matrix),公式如下:
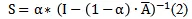
其中,
因子
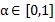
之间,通常设为0.15。
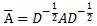
是标准化的对称邻接矩阵,
是标准化的对称邻接矩阵,A是文本图的邻接矩阵,D是相应的对角矩阵。
因此,
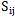
测度了节点i和节点j间的亲密分数。
对于文档词语节点
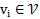
采样大小为k的子图
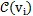
即通过选择前k个最亲密的邻接文档节点
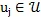
对于词语文档节点
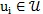
首先计算两种类型的关联边(incident edge)的比。
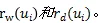
计算公式如下:
其中,
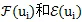
和分别是关联的
词语-词语边集合、词语-文本边集合,
且亲密分数大于阈值
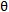
采样大小为k个大小的情景图
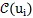
即选择前
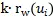
个亲密邻居词语节点
即选择前k个亲密邻居词语节点
和前
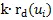
个亲密邻居文档节点。
(3)文本图Transformer模型
基于采样的小批量子图,TG-Transformer(文本图Transformer模型)可以递归更新文本图的节点的特征并用于分类问题。
该模型的输入是经过两种结构编码的批量子图中节点的原始特征词向量。这两种结构编码分别是异质性编码和WL结构编码:
1)异质性编码:异质性编码能刻画文本图中的文档和词语两种类型。类似于2018年Devlin等人论文中的分割编码,分别用0和1对文档节点和词语节点进行编码。
2) WL结构编码:论文作者采用了图理论中著名的WL结构编码(WEISFEILER-Lehman) 去刻画文本图的结构。WL算法能根据图中的结构角色标注节点,
可以用
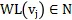
来表示, 编码公式如下:
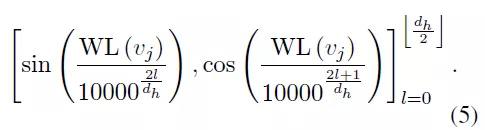
公式(5)中的两个编码具有相同的维度,
即
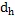
作为原始特征的嵌入,论文作者把它们加起来作为输入子图的初始节点特征,
用

表示。
在图Transformer层,可以加总批量子图的信息,以学习目标节点的特征。每一个图Transformer层包含三个可训练的矩阵,分别是查询权重、关键词权重和值权重
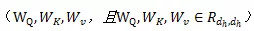
查询Q、关键词K和值V通过其乘以相应的输入获得(Q可以理解为信息检索中的查询,然后根据Query(查询)和Key(返回的关键特征)的相似度得到匹配的内容(Value)):
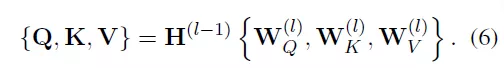
因此,TG-Transformer层可以通过公式(7)得到:
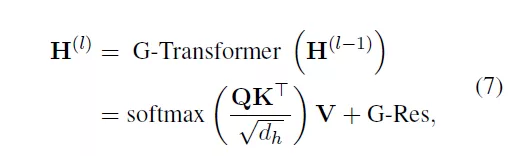
其中,G-Res指残差网络中的图残差[2],解决GNN的过度平滑问题。
最后一层的输出
将被平均为
目标节点z的最终特征,并最后进入softmax分类中。
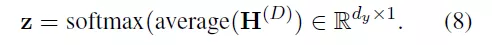
基于对所有节点在训练样本中的子图采样如,论文作者定义了交叉熵损失函数:
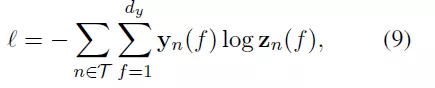
03 实验
论文作者为了评估模型的有效性,实验建立在5个数据库基础上,分别是:R52和R8路透社新闻文本分类数据库、用于医学文献分类的Ohsumed数据库、2个大规模的点评数据库IMDB和Yelp 2014。基线模型是CNN、LSTM和fastTest,使用了词语/n-元嵌入平均。
论文作者设置节点的特征维度为300,初始特征使用Glove词向量,训练了两层的图Transformer,隐藏层大小为32和4个注意力头机制。
小批量SGD算法使用了Adam 优化器,dropout为0.5,初始学习率为0.001,decay的权重为5。
decay的权重为
从训练集中随机选择10%作为验证集,若验证集的损失在10个连续epoch中没有下降,就停止训练。
实验结果如下:
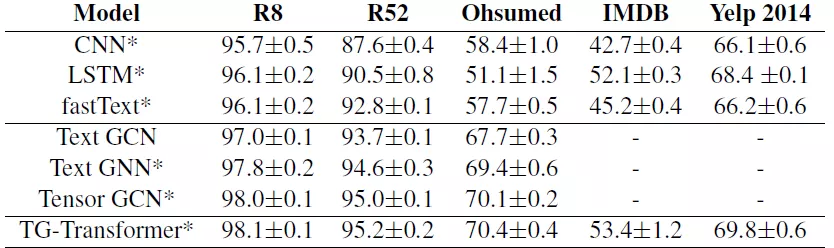
从实验结果可以看到,基于图神经网络模型的结果(无论是TextGCN、TextGNN、TensorGCN还是这篇论文作者用到的TG-Transformer),在不同的数据集中都好于传统的CNN、LSTM和fastText模型方法。
论文作者为了进一步验证其方法的有效性,进行了如下消融实验:
(1)去除2个结构编码且仅仅使用原始特征嵌入作为输入,性能的下降说明结构编码捕捉到了一些有用的异质性图结构信息;
(2)去除预训练词语嵌入且用随机向量初始化所有节点,性能下降更大,说明预训练词语嵌入和初始化节点特征在论文模型中的重要性;
(3)训练了一个新模型去更新和学习批量子图的节点类型,分类精度只是略微下降,这说明了文本图模型中的异质性信息的重要性。
04 结论
总之,这篇论文通过从文本图中获取结构和异质性,学习得到有效的节点特征,并通过小批量的文本图采样方法大大地降低了在处理大规模语料库时的计算和存储成本。
论文的实验表明TG-Transformer方法要好于目前的文本分类SOTA方法。
作者在论文中介绍了文本图的建立、文本图的采样,如何通过异质性编码、WL结构编码和图Transformer层来得到文本的类别,并在IMDB、Yelp等语料库进行了实验,获得了比传统图模型(如Text-GCN)更好的文本分类实验结果。
该论文的成果可用于未来的图神经网络模型预训练方面的研究。
引用文献来源
[1] https://arxiv.org/abs/1810.04805v2
[2] https://arxiv.org/abs/1909.05729
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
文本图Tranformer在文本分类中的应用的更多相关文章
- GCN和GCN在文本分类中应用
1.GCN的概念 传统CNN卷积可以处理图片等欧式结构的数据,却很难处理社交网络.信息网络等非欧式结构的数据.一般图片是由c个通道h行w列的矩阵组成的,结构非常规整.而社交网络.信息网络 ...
- 小样本学习(few-shot learning)在文本分类中的应用
1,概述 目前有效的文本分类方法都是建立在具有大量的标签数据下的有监督学习,例如常见的textcnn,textrnn等,但是在很多场景下的文本分类是无法提供这么多训练数据的,比如对话场景下的意图识别, ...
- 用于文本分类的RNN-Attention网络
用于文本分类的RNN-Attention网络 https://blog.csdn.net/thriving_fcl/article/details/73381217 Attention机制在NLP上最 ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- Bert文本分类实践(三):处理样本不均衡和提升模型鲁棒性trick
目录 写在前面 缓解样本不均衡 模型层面解决样本不均衡 Focal Loss pytorch代码实现 数据层面解决样本不均衡 提升模型鲁棒性 对抗训练 对抗训练pytorch代码实现 知识蒸馏 防止模 ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- CNN 文本分类
谈到文本分类,就不得不谈谈CNN(Convolutional Neural Networks).这个经典的结构在文本分类中取得了不俗的结果,而运用在这里的卷积可以分为1d .2d甚至是3d的. 下面 ...
随机推荐
- See you~(hdu1892)
See you~ Time Limit: 5000/3000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Total Su ...
- 1319 - Monkey Tradition
1319 - Monkey Tradition PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB ...
- 如何把 MySQL 备份验证性能提升 10 倍
JuiceFS 非常适合用来做 MySQL 物理备份,具体使用参考我们的官方文档.最近有个客户在测试时反馈,备份验证的数据准备(xtrabackup --prepare)过程非常慢.我们借助 Juic ...
- 【Netty技术专题】「原理分析系列」Netty强大特性之ByteBuf零拷贝技术原理分析
零拷贝Zero-Copy 我们先来看下它的定义: "Zero-copy" describes computer operations in which the CPU does n ...
- Java Web大作业——编程导航系统
title: Java Web大作业--编程导航系统 categories: - - 计算机科学 - Java abbrlink: 40bc48a1 date: 2021-12-29 00:37:35 ...
- JavaScript交互式网页设计 • 【第6章 初识jQuery】
全部章节 >>>> 本章目录 6.1 jQuery概述 6.1.1 初识 jQuery 6.1.2 jQuery 基本功能 6.1.3 搭建 jQuery 开发环境 6.1 ...
- Ranger开源贡献统计
统计一下自己在Ranger开源社区贡献的Issue数量, 开源社区的Issue主要分为New Feature,Bug,Improvement, 这三种都是和代码相关的,会直接修改开源项目的代码库, 还 ...
- 简单的制作ssl证书,并在nginx和IIS中使用
2020年最后一篇博文收官,提前祝各位园友新年快乐 现在的后端开发,动不动就是需要https,或者说是需要ssl证书,既然没有正版的证书,那么我们只能自己制作ssl的证书了. 说明:证书的制作采用的是 ...
- CentOS7添加开机启动服务或脚本
方法一(rc.local) 改方式配置自动启动最为简单,只需要修改rc.local文件 由于在centos7中/etc/rc.d/rc.local的权限被降低了,所以需要赋予其可执行权 chmod + ...
- vue中另一种路由写法
一个项目中一级菜单是固定的,二级及其以下的菜单是动态的,直接根据文件夹结构写路由 import Vue from 'vue' import Router from 'vue-router' impor ...