left join 后用 on 还是 where,区别大了!
前天写SQL时本想通过 A left B join on and 后面的条件来使查出的两条记录变成一条,奈何发现还是有两条。
后来发现 join on and 不会过滤结果记录条数,只会根据and后的条件是否显示 B表的记录,A表的记录一定会显示。
不管and 后面的是A.id=1还是B.id=1,都显示出A表中所有的记录,并关联显示B中对应A表中id为1的记录或者B表中id为1的记录。
运行sql :
select * from student s left join class c on s.classId=c.id order by s.id
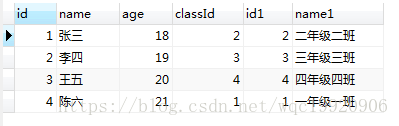
运行sql :
select * from student s left join class c on s.classId=c.id and s.name="张三" order by s.id
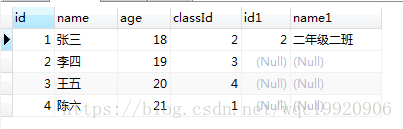
运行sql :
select * from student s left join class c on s.classId=c.id and c.name="三年级三班" order by s.id
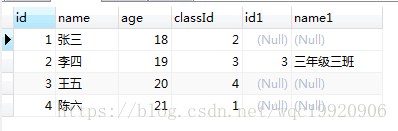
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
假设有两张表:
表1:tab2
| id | size |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
表2:tab2
| Size | Name |
|---|---|
| 10 | AAA |
| 20 | BBB |
| 20 | CCC |
两条SQL:
select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’
select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’)
第一条SQL的过程:
1、中间表on条件:
tab1.size = tab2.size
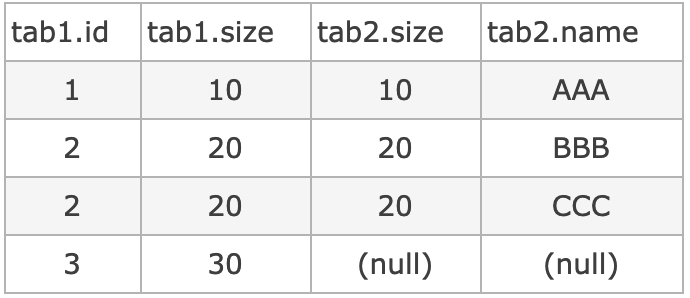
2、再对中间表过滤where 条件:
tab2.name=’AAA’

第二条SQL的过程:
1、中间表on条件:
tab1.size = tab2.size and tab2.name=’AAA’
(条件不为真也会返回左表中的记录)

其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。
而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
原文链接:https://blog.csdn.net/wqc19920906/article/details/79785424
版权声明:本文为CSDN博主「jcpp9527」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
近期热文推荐:
1.600+ 道 Java面试题及答案整理(2021最新版)
2.终于靠开源项目弄到 IntelliJ IDEA 激活码了,真香!
3.阿里 Mock 工具正式开源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式发布,全新颠覆性版本!
觉得不错,别忘了随手点赞+转发哦!
left join 后用 on 还是 where,区别大了!的更多相关文章
- mysql中join后on、where的区别
SELECT * FROM A; SELECT * FROM B; 以上是两张表的机构 SELECT * FROM A LEFT JOIN B ON A.id=b.a_id ; ; ; 两个语句查询出 ...
- LEFT JOIN、Right、Full后ON和WHERE的区别
今天在工作的时候碰到了一个问题,A表B表left join后在on后面关于A表的条件过滤语句没起到我想要的过滤作用,还是对左连接等理解的不够呀. SELECT * FROM student; SELE ...
- left join on +多条件与where区别
left join on +多条件与where区别 重点 先匹配,再筛选where条件. 本文将通过几个例子说明两者的差别. 1. 单个条件 select * from product a left ...
- left join 后的条件 位置不同,查询的结果不同
表t_a id name 1 a1 2 a2 表t_b a1_id name num 2 b2 1 3 b3 100 left join 后加查询条件 select a.* from t_a a le ...
- 【数据库】left join(左关联)、right join(右关联)、inner join(自关联)的区别
left join(左关联).right join(右关联).inner join(自关联)的区别 用一张图说明三者的区别: 总结: left join(左联接) 返回包括左表中的所有记录和右表中关联 ...
- left join on 后and 和 where 的区别
SELECT * FROM student a LEFT JOIN sc b ON a.Sid = b.Sid AND a.Sname="赵雷" 结果:(left join 左连接 ...
- 数组的常用方法concat,join,slice和splice的区别,map,foreach,reduce
1.concat()和join() concat()是连对两个或两个数组的方法,直接可以将数组以参数的形式放入 join()是将数组中的所有元素放入一个字符串中,通俗点讲就是可以将数组转换成字符串 2 ...
- SQL JOIN 中 on 与 where 的区别
left join : 左连接,返回左表中所有的记录以及右表中连接字段相等的记录. right join : 右连接,返回右表中所有的记录以及左表中连接字段相等的记录. inner join : 内连 ...
- left join中where与on的区别
举例进行说明,我们现在有两个表,即商品表(products)与sales_detail(销售记录表).我们主要是通过这两个表来对MySQL关联left join 条件on与where 条件的不同之处进 ...
随机推荐
- Redis不是一直号称单线程效率也很高吗,为什么又采用多线程了?
Redis是目前广为人知的一个内存数据库,在各个场景中都有着非常丰富的应用,前段时间Redis推出了6.0的版本,在新版本中采用了多线程模型. 因为我们公司使用的内存数据库是自研的,按理说我对Redi ...
- [源码分析] 消息队列 Kombu 之 mailbox
[源码分析] 消息队列 Kombu 之 mailbox 0x00 摘要 本系列我们介绍消息队列 Kombu.Kombu 的定位是一个兼容 AMQP 协议的消息队列抽象.通过本文,大家可以了解 Komb ...
- OpenCV图像处理中“投影技术”的使用
本文区分"问题引出"."概念抽象"."算法实现"三个部分由表及里具体讲解OpenCV图像处理中"投影技术" ...
- 使用 Github Actions artifact 在 workflow job 之间共享数据
(AgileConfig)[https://github.com/kklldog/AgileConfig] 在使用 react 编写UI后,变成了一个彻彻底底的前后端分离的项目,上一次解决了把reac ...
- Chapter 2 简单DC-DC变换器稳态分析小结
Chapter 2 简单DC-DC变换器稳态分析小结 1 本章重点 1.1 小纹波近似 所谓小纹波近似就是DC-DC变换器的稳态分析中,假定开关频率次的纹波相对于直流分量而言非常小,可以将其忽略进行各 ...
- Sqlmap的基础用法(禁止用于非法用途,测试请自己搭建靶机)
禁止用于非法用途,测试与学习请自己搭建靶机 sqlmap -r http.txt #http.txt是我们抓取的http的请求包 sqlmap -r http.txt -p username #指 ...
- MySQL提升笔记(4)InnoDB存储结构
这一节本来计划开始索引的学习,但是在InnoDB存储引擎的索引里,存在一些数据存储结构的概念,这一节先了解一下InnodDB的逻辑存储结构,为索引的学习打好基础. 从InnoDB存储引擎的存储结构看, ...
- JMeter发送get请求并分析返回结果
在实际工作的过程中,我们通常需要模拟接口,来进行接口测试,我们可以通过JMeter.postman等多种工具来进行接口测试,但是工具的如何使用对于我们来说并不是最重要的部分,最重要的是设计接口测试用例 ...
- Day11_57_自定义泛型
自定义泛型 package com.shige.Generic; //自定义泛型 public class CustomizeGeneric { public static void main(Str ...
- 被动信息搜集 - Python安全攻防
概述: 被冻信息搜集主要通过搜索引擎或者社交等方式对目标资产信息进行提取,通常包括IP查询,Whois查询,子域名搜集等.进行被动信息搜集时不与目标产生交互,可以在不接触到目标系统的情况下挖掘目标信息 ...