pandas(5):数学统计——描述性统计
Pandas 可以对 Series 与 DataFrame 进行快速的描述性统计,方便快速了解数据的集中趋势和分布差异。源Excel文件descriptive_statistics.xlsx:

一、描述性统计汇总df.describe()
df.describe(percentiles=None, include=None, exclude=None)
参数说明:
- percentiles,百分位数,默认为[.25, .5, .75],即上下四分位数和中位数,其中,中位数一定输出;
- include,控制描述性统计输出包含的内容。
数值型和离散型特征数据(定序数据和定类数据)
默认值:None,即只输出数值型数据列的统计信息(count、mean、std、min、百分位数、max)。
'all':输入的所有列的统计信息。
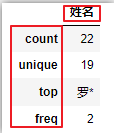
'O':只输出 object(字符、定类数据)的统计信息:count、unique(分类分组数量)、top(出现次数最多的类别)、freq(top出现的频数) - exclude,和参数include是相反的,表示不输出哪些内容。
df.describe() # 默认:数值型数据,上下四分位和中位数
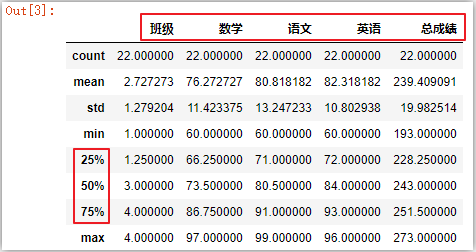
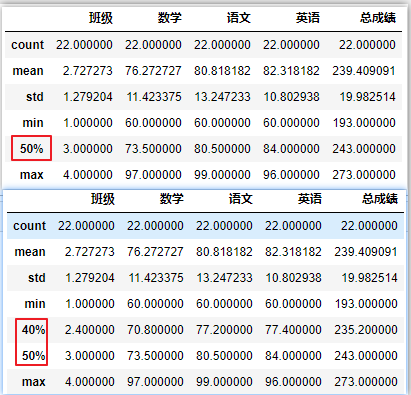
df.describe([]) # 只输出中位数
df.describe([.4]) # 中位数和40%分位数
# 指定类型:只输出字符型离散数据统计特征
df.describe(include='O')
# df.describe(include=[np.object])
# 排除类型
df.describe(exclude=[np.number])
二、其他数学统计方法
DataFrame 计算后一般为一个 Series或df,Series 计算后为一个定值。
df.mean() # 返回所有列的均值
df.mean(1) # 返回所有行的均值,下同
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.abs() # 绝对值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差, 贝塞尔校正的样本标准偏差
df.var() # 无偏方差
df.sem() # 平均值的标准误差
df.mode() # 众数
df.prod() # 连乘
df.mad() # 平均绝对偏差
df.cumprod() # 累积连乘,累乘
df.cumsum(axis=0) # 累积连加,累加
df.nunique() # 去重数量,不同值的量
df.idxmax() # 每列最大的值的索引名
df.idxmin() # 最小
df.cummax() # 累积最大值
df.cummin() # 累积最小值
df.skew() # 样本偏度 (第三阶)
df.kurt() # 样本峰度 (第四阶)
df.quantile() # 样本分位数 (不同 % 的值)
特殊说明:
- 很多方法支持行列指定,默认为列axis=0;
- 是否排除缺失值,默认排除skipna=False;
- 假若索引为多层索引,支持索引层次选择,level参数控制;
- 是否排除bool值,numeric_only,默认为False,不排除;
- 如果有空值总共算几,min_count,默认为0,一个不算。
pandas(5):数学统计——描述性统计的更多相关文章
- Pandas描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数,但其中一些,如sumsum(),产生一个相同大小的对象. 一般来说,这些方法采 ...
- Pandas | 06 描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数. 一般来说,这些方法采用轴参数,就像ndarray.{sum,std,...} ...
- Pandas 之 描述性统计案例
认识 jupyter地址: https://nbviewer.jupyter.org/github/chenjieyouge/jupyter_share/blob/master/share/panda ...
- 基于R语言的数据分析和挖掘方法总结——描述性统计
1.1 方法简介 描述性统计包含多种基本描述统计量,让用户对于数据结构可以有一个初步的认识.在此所提供之统计量包含: 基本信息:样本数.总和 集中趋势:均值.中位数.众数 离散趋势:方差(标准差).变 ...
- Python实现描述性统计
该篇笔记由木东居士提供学习小组.资料 描述性统计的概念很好理解,在日常工作中我们也经常会遇到需要使用描述性统计来表述的问题.以下,我们将使用Python实现一系列的描述性统计内容. 有关python环 ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- 使用Python进行描述性统计
目录 1 描述性统计是什么?2 使用NumPy和SciPy进行数值分析 2.1 基本概念 2.2 中心位置(均值.中位数.众数) 2.3 发散程度(极差,方差.标准差.变异系数) 2.4 偏差程度(z ...
- \(\S1\) 描述性统计
在认识客观世界的过程中,统计学的思想和方法经常起着不可替代的作用.在许多工程及自然科学的专业领域中,包括可靠性分析.质量控制.生物信息.脑科学.心理分析.经济分析.金融风险管理.社会科学推断.行为科学 ...
- 程序员的数学 三册数学,概率统计、线性代数pdf
程序员的数学1 2012.pdf 2012版 程序员的数学2 概率统计 ,平冈和幸,(日)堀玄著 ,P4006 2015.pdf 2015版 程序员的数学3-线性代数 2016.pdf 2016版 如 ...
随机推荐
- JDK环境解析,安装和目的
目录 1. JDK环境解析 1.1 JVM 1.2 JRE 1.3 JDK 2. JDK安装 2.1 为什么使用JDK8 2.1.1 更新 2.1.2 稳定 2.1.3 需求 2.2 安装JDK 2. ...
- HQYJ嵌入式学习笔记——C语言复习day2
1.计算机的数值表示 数值类型和非数值类型 二进制 0,1 (0b1001) 八进制 0~7 (0146) 十进制 0~9 十六进制 0~f (0x3f) 八进制转二进制-->一位八进制数换 ...
- Yarn框架的一般过程
基本过程图: Clinet向ResouceManager发送Job请求 ResouceManager接受到请求后在自身开启一个Container 来运行的ApplicationManager组件,Ap ...
- CentOS7安装Mysql并配置远程访问
(su root登录到root账户) 下载repo源 wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 安装rpm ...
- Using Sqoop to import from db2 to hadoop
参考 : https://stackoverflow.com/questions/23933481/db2-data-import-into-hadoop sqoop import - ...
- Docker-compose编排微服务顺序启动
一.概述 docker-compose可以方便组合多个 docker 容器服务, 但是, 当容器服务之间存在依赖关系时, docker-compose 并不能保证服务的启动顺序.docker-comp ...
- 后端程序员之路 35、Index搜索引擎实现分析4-最终的正排索引与倒排索引
# index_box 提供搜索功能的实现- 持有std::vector<ITEM> _buffer; 存储所有文章信息- 持有ForwardIndex _forward_index; ...
- JUC-ThreadLocalRandom
目录 Radndom类的局限性 ThreadLocalRandom 这个类是在JDK7中新增的随机数生成器,它弥补了Random类在多线程下的缺陷. Radndom类的局限性 在JDK7之前包括现在j ...
- three.js cannon.js物理引擎之约束(二)
今天郭先生继续讲cannon.js的物理约束,之前的一篇文章曾简单的提及过PointToPointConstraint约束,那么今天详细的说一说cannon.js的约束和使用方法.在线案例请点击博客原 ...
- postman接口测试之设置全局变量和设置环境变量和全局变量
一.概念 1.环境变量 就是接口的域名或IP地址. 2.全局变量 就是一个作用域为整个postman的变量. 二.使用场景 1.环境变量 在测试的过程中,经常会频繁切换环境,本地环境验证.发布到测试环 ...