TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?
大家好,我是小林。
TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?
这是个好问题,应该有不少人都会搞混,因为这两个东西看上去太像了,很容易误以为是同一个东西。
事实上,这两个完全是两样不同东西,实现的层面也不同:
- HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接;
- TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制;
接下来,分别说说它们。
HTTP 的 Keep-Alive
HTTP 协议采用的是「请求-应答」的模式,也就是客户端发起了请求,服务端才会返回响应,一来一回这样子。
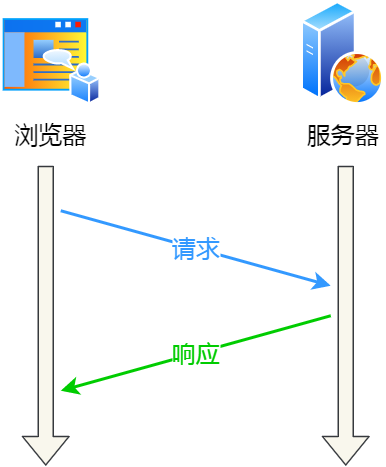 请求-应答
请求-应答
由于 HTTP 是基于 TCP 传输协议实现的,客户端与服务端要进行 HTTP 通信前,需要先建立 TCP 连接,然后客户端发送 HTTP 请求,服务端收到后就返回响应,至此「请求-应答」的模式就完成了,随后就会释放 TCP 连接。
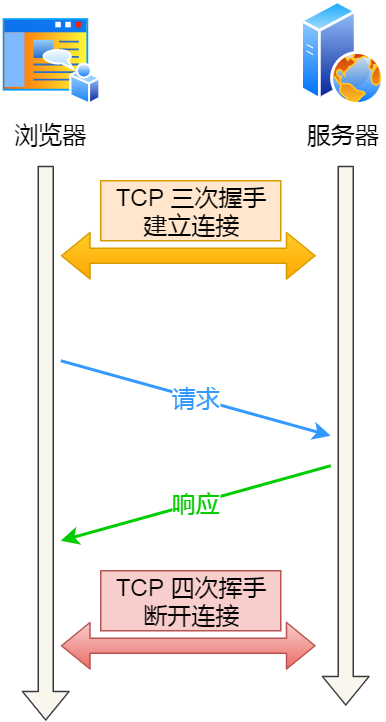 一个 HTTP 请求
一个 HTTP 请求
如果每次请求都要经历这样的过程:建立 TCP -> 请求资源 -> 响应资源 -> 释放连接,那么此方式就是 HTTP 短连接,如下图:
 HTTP 短连接
HTTP 短连接
这样实在太累人了,一次连接只能请求一次资源。
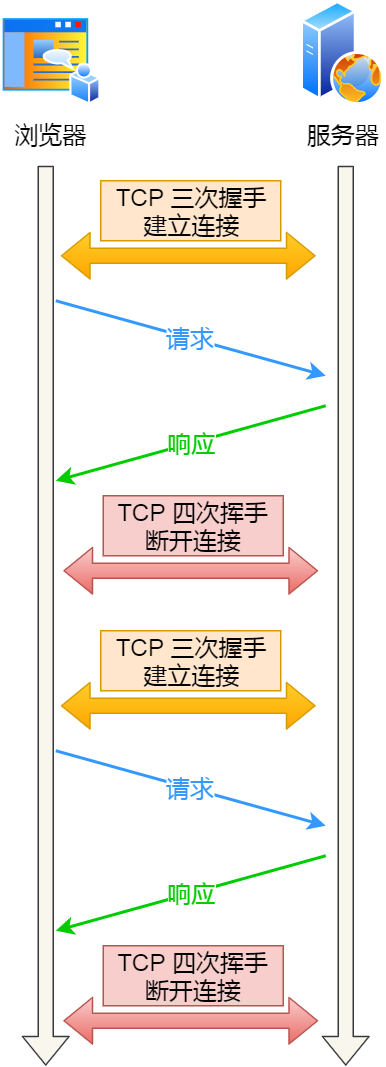
能不能在第一个 HTTP 请求完后,先不断开 TCP 连接,让后续的 HTTP 请求继续使用此连接?
当然可以,HTTP 的 Keep-Alive 就是实现了这个功能,可以使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,避免了连接建立和释放的开销,这个方法称为 HTTP 长连接。
 HTTP 长连接
HTTP 长连接
HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
怎么才能使用 HTTP 的 Keep-Alive 功能?
在 HTTP 1.0 中默认是关闭的,如果浏览器要开启 Keep-Alive,它必须在请求的包头中添加:
Connection: Keep-Alive
然后当服务器收到请求,作出回应的时候,它也添加一个头在响应中:
Connection: Keep-Alive
这样做,连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个连接。这一直继续到客户端或服务器端提出断开连接。
从 HTTP 1.1 开始, 就默认是开启了 Keep-Alive,如果要关闭 Keep-Alive,需要在 HTTP 请求的包头里添加:
Connection:close
现在大多数浏览器都默认是使用 HTTP/1.1,所以 Keep-Alive 都是默认打开的。一旦客户端和服务端达成协议,那么长连接就建立好了。
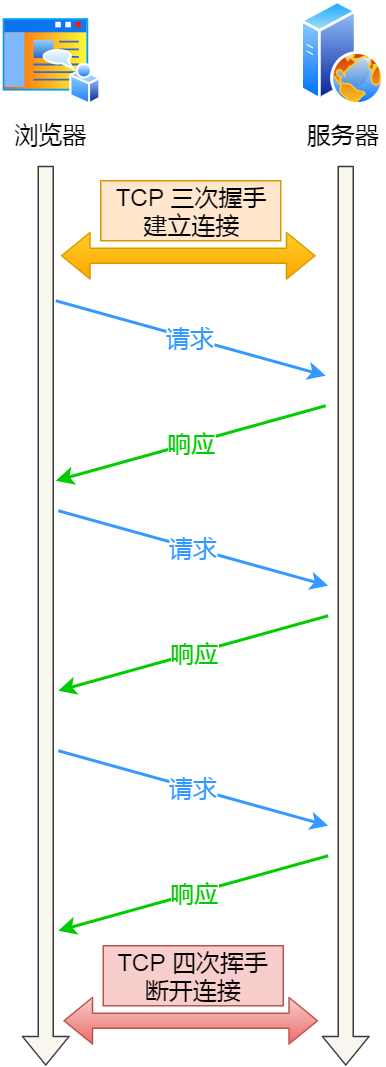
HTTP 长连接不仅仅减少了 TCP 连接资源的开销,而且这给 HTTP 流水线技术提供了可实现的基础。
所谓的 HTTP 流水线,是客户端可以先一次性发送多个请求,而在发送过程中不需先等待服务器的回应,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。HTTP 流水线机制则允许客户端同时发出 A 请求和 B 请求。
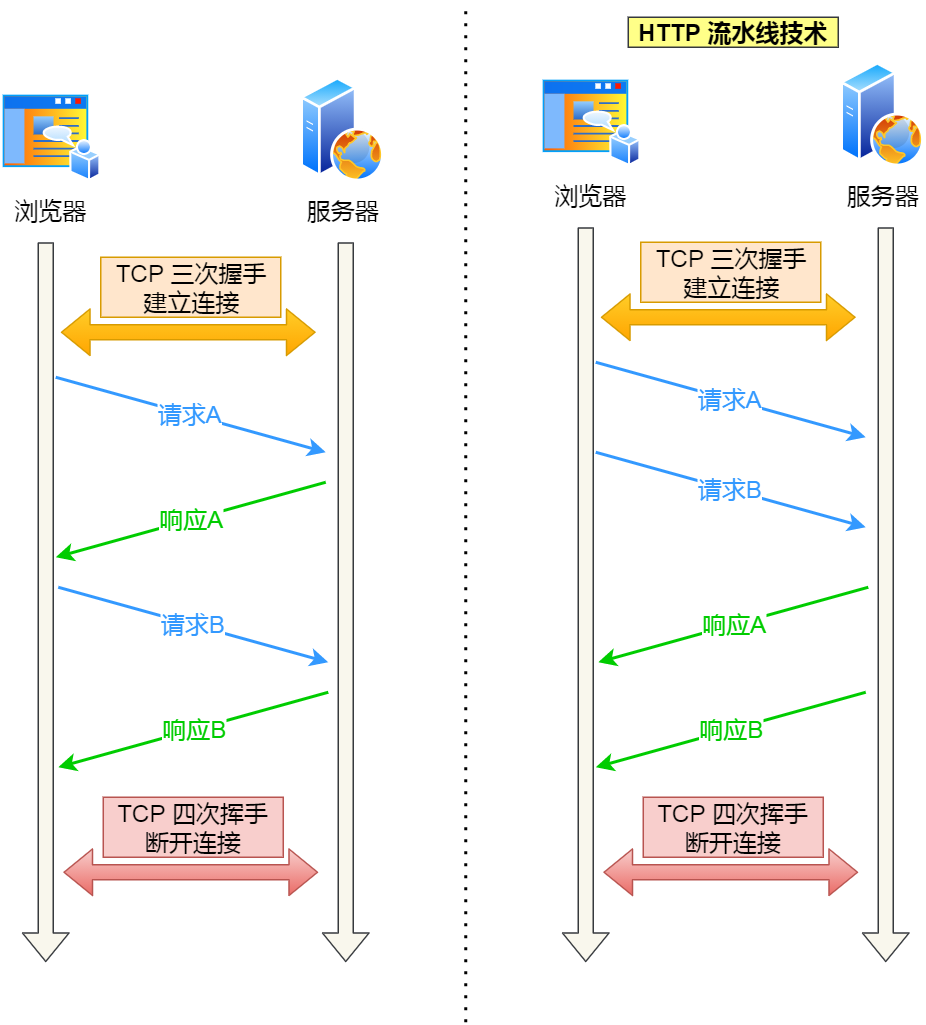 右边为 HTTP 流水线机制
右边为 HTTP 流水线机制
但是服务器还是按照顺序响应,先回应 A 请求,完成后再回应 B 请求。
而且要等服务器响应完客户端第一批发送的请求后,客户端才能发出下一批的请求,也就说如果服务器响应的过程发生了阻塞,那么客户端就无法发出下一批的请求,此时就造成了「队头阻塞」的问题。
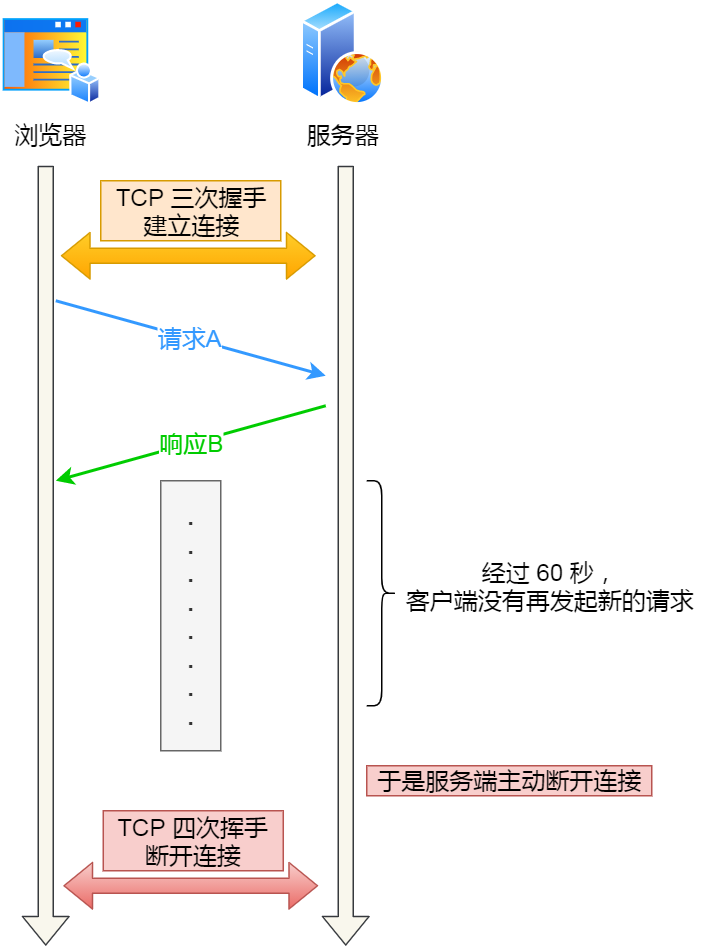
可能有的同学会问,如果使用了 HTTP 长连接,如果客户端完成一个 HTTP 请求后,就不再发起新的请求,此时这个 TCP 连接一直占用着不是挺浪费资源的吗?
对没错,所以为了避免资源浪费的情况,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。
比如设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
 HTTP 长连接超时
HTTP 长连接超时
TCP 的 Keepalive
TCP 的 Keepalive 这东西其实就是 TCP 的保活机制,它的工作原理我之前的文章写过,这里就直接贴下以前的内容。
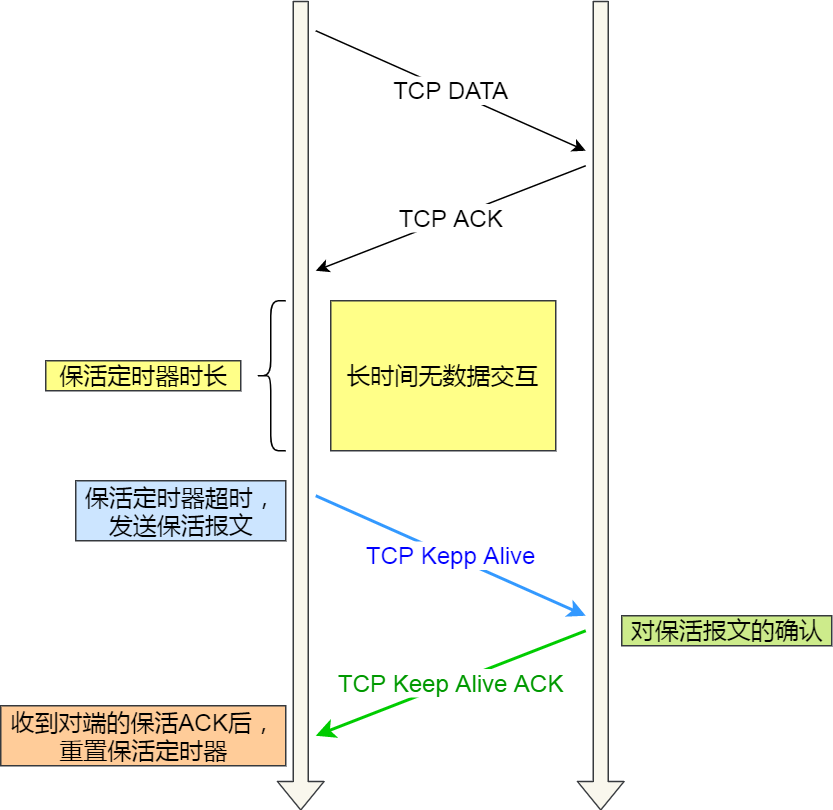
如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,那么内核里的 TCP 协议栈就会发送探测报文。
- 如果对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活,这个工作是在内核完成的。
 TCP 保活机制
TCP 保活机制
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没
大家好,我是小林。
TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?
这是个好问题,应该有不少人都会搞混,因为这两个东西看上去太像了,很容易误以为是同一个东西。
事实上,这两个完全是两样不同东西,实现的层面也不同:
- HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接;
- TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制;
接下来,分别说说它们。
HTTP 的 Keep-Alive
HTTP 协议采用的是「请求-应答」的模式,也就是客户端发起了请求,服务端才会返回响应,一来一回这样子。
请求-应答
由于 HTTP 是基于 TCP 传输协议实现的,客户端与服务端要进行 HTTP 通信前,需要先建立 TCP 连接,然后客户端发送 HTTP 请求,服务端收到后就返回响应,至此「请求-应答」的模式就完成了,随后就会释放 TCP 连接。
一个 HTTP 请求
如果每次请求都要经历这样的过程:建立 TCP -> 请求资源 -> 响应资源 -> 释放连接,那么此方式就是 HTTP 短连接,如下图:
HTTP 短连接
这样实在太累人了,一次连接只能请求一次资源。
能不能在第一个 HTTP 请求完后,先不断开 TCP 连接,让后续的 HTTP 请求继续使用此连接?
当然可以,HTTP 的 Keep-Alive 就是实现了这个功能,可以使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,避免了连接建立和释放的开销,这个方法称为 HTTP 长连接。
HTTP 长连接
HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
怎么才能使用 HTTP 的 Keep-Alive 功能?
在 HTTP 1.0 中默认是关闭的,如果浏览器要开启 Keep-Alive,它必须在请求的包头中添加:
Connection: Keep-Alive
然后当服务器收到请求,作出回应的时候,它也添加一个头在响应中:
Connection: Keep-Alive
这样做,连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个连接。这一直继续到客户端或服务器端提出断开连接。
从 HTTP 1.1 开始, 就默认是开启了 Keep-Alive,如果要关闭 Keep-Alive,需要在 HTTP 请求的包头里添加:
Connection:close
现在大多数浏览器都默认是使用 HTTP/1.1,所以 Keep-Alive 都是默认打开的。一旦客户端和服务端达成协议,那么长连接就建立好了。
HTTP 长连接不仅仅减少了 TCP 连接资源的开销,而且这给 HTTP 流水线技术提供了可实现的基础。
所谓的 HTTP 流水线,是客户端可以先一次性发送多个请求,而在发送过程中不需先等待服务器的回应,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。HTTP 流水线机制则允许客户端同时发出 A 请求和 B 请求。
右边为 HTTP 流水线机制
但是服务器还是按照顺序响应,先回应 A 请求,完成后再回应 B 请求。
而且要等服务器响应完客户端第一批发送的请求后,客户端才能发出下一批的请求,也就说如果服务器响应的过程发生了阻塞,那么客户端就无法发出下一批的请求,此时就造成了「队头阻塞」的问题。
可能有的同学会问,如果使用了 HTTP 长连接,如果客户端完成一个 HTTP 请求后,就不再发起新的请求,此时这个 TCP 连接一直占用着不是挺浪费资源的吗?
对没错,所以为了避免资源浪费的情况,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。
比如设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
HTTP 长连接超时
TCP 的 Keepalive
TCP 的 Keepalive 这东西其实就是 TCP 的保活机制,它的工作原理我之前的文章写过,这里就直接贴下以前的内容。
如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,那么内核里的 TCP 协议栈就会发送探测报文。
- 如果对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活,这个工作是在内核完成的。
TCP 保活机制
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
总结
HTTP 的 Keep-Alive 也叫 HTTP 长连接,该功能是由「应用程序」实现的,可以使得用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,减少了 HTTP 短连接带来的多次 TCP 连接建立和释放的开销。
TCP 的 Keepalive 也叫 TCP 保活机制,该功能是由「内核」实现的,当客户端和服务端长达一定时间没有进行数据交互时,内核为了确保该连接是否还有效,就会发送探测报文,来检测对方是否还在线,然后来决定是否要关闭该连接。
答应我,下次别再混淆啦!
我是小林,今天的你,比昨天更博学了吗?
我们下次见啦。
有设置,那么就无法使用 TCP 保活机制。
总结
HTTP 的 Keep-Alive 也叫 HTTP 长连接,该功能是由「应用程序」实现的,可以使得用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,减少了 HTTP 短连接带来的多次 TCP 连接建立和释放的开销。
TCP 的 Keepalive 也叫 TCP 保活机制,该功能是由「内核」实现的,当客户端和服务端长达一定时间没有进行数据交互时,内核为了确保该连接是否还有效,就会发送探测报文,来检测对方是否还在线,然后来决定是否要关闭该连接。
答应我,下次别再混淆啦!
我是小林,今天的你,比昨天更博学了吗?
我们下次见啦。
TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?的更多相关文章
- TCP的keepalive和应用层的heart
从长链接说起 TCP是长链接的,也就是说连接建立后,及时数年没有通信连接仍然存在.这样做的好处是:免去了DNS解析的时间,连接建立等时间,大大加快了请求的速度,同时也有利于接受服务器的实时消息.但前提 ...
- 理解TCP之Keepalive
理解HTTP之keep-alive 在前面一篇文章中讲了TCP的keepalive,这篇文章再讲讲HTTP层面keep-alive.两种keepalive在拼写上面就是不一样的,只是发音一样,于是乎大 ...
- 浅谈Http长连接和Keep-Alive以及Tcp的Keepalive
原文:https://blog.csdn.net/weixin_37672169/article/details/80283935 Keep-Alive模式: 我们知道Http协议采用“请求-应答”模 ...
- 在向服务器发送请求时发生传输级错误。 (provider: TCP 提供程序, error: 0 - 远程主机强迫关闭了一个现有的连接。)
用VS2005+SQLSERVER2008开发C/S的程序,程序上线运行一段时间之后发现在某些功能偶尔出现如下的错误: 在向服务器发送请求时发生传输级错误. (provider: TCP 提供程序, ...
- System.Data.SqlClient.SqlException: 在向服务器发送请求时发生传输级错误。 (provider: TCP 提供程序, error: 0 - 远程主机强迫关闭了一个现有的连接。) .
今天使用sql server 2008 R2管理器,进行SQL查询时,频率非常高的报错: System.Data.SqlClient.SqlException: 在向服务器发送请求时发生传输级错误. ...
- 【转】http的keep-alive和tcp的keepalive区别
http://blog.csdn.net/oceanperfect/article/details/51064574 1.HTTP Keep-Alive在http早期,每个http请求都要求打开一个t ...
- http的keep-alive和tcp的keepalive区别
原文地址:http://blog.csdn.net/oceanperfect/article/details/51064574 1.HTTP Keep-Alive在http早期,每个http请求都要求 ...
- 在Linux环境下使用TCP的keepalive机制
Linux内置支持keepalive机制,为了使用它,你须要使能TCP/IP网络,为了可以配置内核在执行时的參数.你还须要procfs和sysctl的支持. 这个过程涉及到keepalive使用的三个 ...
- 关于tcp的keepalive
先记录几个要点 只能用在面向连接的tcp中,对应对端的非正常关闭有效(对端服务器重启这种,也是正常关闭,FIN RST包都算) 只要是写入到缓冲区就认为OK,所以UDP不适合,所以如果有正常的网络交互 ...
随机推荐
- [Linux-网络性能测试] -- netperf测试
[Linux-网络性能测试] -- netperf测试 2017.01.17 14:15:54字数 1599阅读 4400 简述 Netperf是一种网络性能的测量工具(由惠普公司开发的,测试网络栈. ...
- Docker——Registry 通过Shell管理私有仓库镜像
使用方法: 复制代码保存为 image_registry.sh sh image_registry.sh -h #查看帮助 HUB=10.0.29.104:5000 改为自己的地址 #!/bin ...
- Docker Swarm(五)Config 配置管理
前言 在动态的.大规模的分布式集群上,管理和分发配置文件也是很重要的工作.传统的配置文件分发方式(如配置文件放入镜像中,设置环境变量,volume 动态挂载等)都降低了镜像的通用性. Docker 1 ...
- AD命令获取计算机、用户相关信息
1. 获取AD用户相关信息(用户名.创建日期.最后修改密码日期.最后登录日期) Get AD users, Name/Created Date/Last change passwd Date/Last ...
- 011.Kubernetes使用共享存储持久化数据
本次实验是以前面的实验为基础,使用的是模拟使用kubernetes集群部署一个企业版的wordpress为实例进行研究学习,主要的过程如下: 1.mysql deployment部署, wordpre ...
- 11.7 iostat: I/O信息统计
iostat是I/O statistics(输入/输出统计)的缩写,其主要功能是对系统的磁盘I/O操作进行监视.它的输出主要是显示磁盘读写操作的统计信息,同时也会给出CPU的使用情况.同vmstat命 ...
- 10.20 host:域名查询工具
host命令 是用于查询DNS的工具,它可以将指定主机名称转换为IP地址. host命令的参数选项及说明 -a 显示详细的DNS信息-t 指定查询的域名信息类型,可以是"A".&q ...
- 看完这篇还不懂 MySQL 主从复制,可以回家躺平了~
大家好,我是小羽. 我们在平时工作中,使用最多的数据库就是 MySQL 了,随着业务的增加,如果单单靠一台服务器的话,负载过重,就容易造成宕机. 这样我们保存在 MySQL 数据库的数据就会丢失,那么 ...
- Redis学习笔记七:主从集群
单机,单节点,单实例的Redis会有什么问题呢? 容易导致单点故障,那么如何解决呢? 可以通过主备方式 同时可以实现读写分离 这里的每个节点是全量的,镜像的. 单节点的容量有限而且单点的压力比较大,如 ...
- mariadb10安装
Red Hat Enterprise Linux/CentOS 7.0 发行版已将默认的数据库从 MySQL 切换到 MariaDB 添加安装源或是从官网下载安装包https://downloads. ...