springboot+atomikos+druid 数据库连接失效分析
一、起因
最近查看系统的后台日志,经常发现这样的报错信息:The last package successfully received from the server was 40802382 milliseconds ago,截图如下所示。

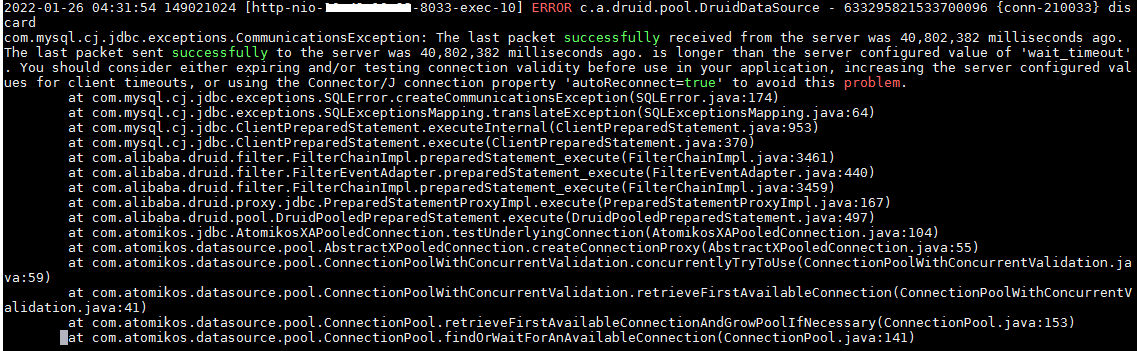
由于我们的系统都是在白天使用,夜里基本上没有用户使用,再加上以上的报错信息都是出现在早晨,结合错误日志初步分析,应该是数据库连接超时自动断开了。百度一番后,得知Mysql的默认连接时间是8小时,超过8小时没有操作后就会自动断开连接,但是已经使用了druid数据库连接池,按理说已经对数据库连接做了保护和检查,不应该出现这样的问题。要想彻底弄明白这个问题,就只能去研究druid数据库连接池框架了。
二、Druid数据库连接池
项目的数据库连接池基本配置信息如下所示
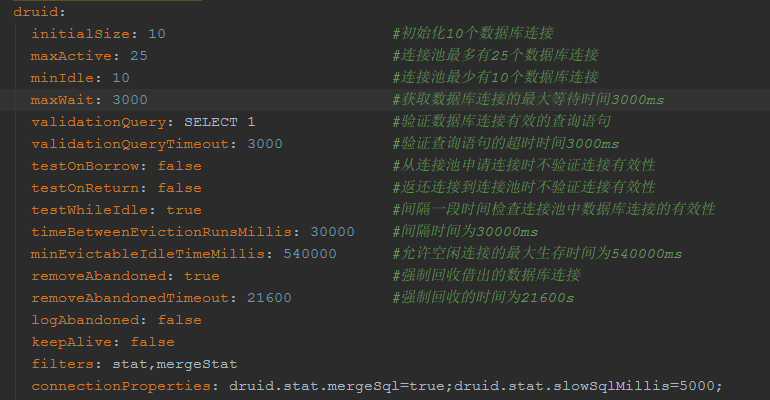
通过以上的配置分析得知,一个数据库连接从连接池中借出后经过21600s即6小时后会被强制回收,不会超过Mysql的默认8小时,而且也不存在这么长时间的事务,所以不太可能是因为数据库连接借出超时导致上面的错误,那么就是从数据库连接池中申请的连接已经超时了?似乎也不太可能,因为有检查机制,即每隔30s就会检查一次连接池中的连接是否超时,并且连接池中允许存在的空闲连接最大时间为540s。这就奇怪了,到底是什么原因导致上面的错误呢?这时注意到上述错误堆栈中的com.atomikos.datasource.pool.ConnectionPool.findOrWaitForAnAvailableConnection。是否问题的原因在于使用了Atomikos呢,带着这样的疑惑去阅读了Druid和Atomikos相关的源码。
由于Atomikos连接池是基于Druid连接池之上的,所以Atomikos新建和销毁数据库连接都是从Druid连接池中借出和归还数据库连接,而不是直接与数据库交互,那么我们就来看看Druid是如何维持数据库连接的。
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
//初始化检查配置和后台线程
init();
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}
从Druid连接池中获取数据库连接,先调用init()方法进行初始化工作,然后调用getConnectionDirect()获取连接。
decrementPoolingCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
public DruidPooledConnection(DruidConnectionHolder holder){
super(holder.getConnection());
this.conn = holder.getConnection();
this.holder = holder;
this.lock = holder.lock;
dupCloseLogEnable = holder.getDataSource().isDupCloseLogEnable();
ownerThread = Thread.currentThread();
connectedTimeMillis = System.currentTimeMillis();
}
上述是获取连接池中连接的关键代码,即获取connections数组中的最后一个元素,获取到Holder后还需要将其封装为DruidPooledConnection,这时该连接的connectedTimeMillis会被赋值为当前时间,这个时间在后续的分析中会非常重要。
因为配置了testWhileIdle为true,所以需要进行下面的有效性检查,获取该连接的上次活跃时间,得到空闲时间,如果超过30s则做有效性检查。
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000);
if (timeMillis >= removeAbandonedTimeoutMillis) {
iter.remove();
pooledConnection.setTraceEnable(false);
abandonedList.add(pooledConnection);
}
同时,由于配置了removeAbandoned为true,所以需要检查活跃连接是否超时,如果超时就断开物理连接。下面看一下连接池的回收方法recycle的关键代码
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - holder.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
discardConnection(holder);
return;
}
}
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
result = putLast(holder, currentTimeMillis);
recycleCount++;
} finally {
lock.unlock();
}
在对数据库连接进行回收时,如果连接时间超过了数据库的物理连接时间(默认8小时)则需要断开物理连接,否则就调用putLast方法将该连接回收到连接池。
boolean putLast(DruidConnectionHolder e, long lastActiveTimeMillis) {
if (poolingCount >= maxActive || e.discard) {
return false;
}
e.lastActiveTimeMillis = lastActiveTimeMillis;
connections[poolingCount] = e;
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = lastActiveTimeMillis;
}
notEmpty.signal();
notEmptySignalCount++;
return true;
}
注意上述标红的地方,回收的这个连接的lastActiveTimeMillis被刷新为当前时间,这个时间也是非常重要的,在后续分析中会用到。
三、Atomikos框架
项目关于Atomikos的配置信息,如下所示
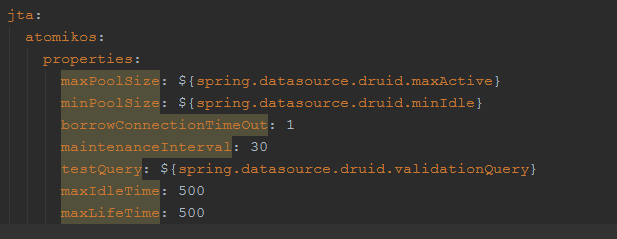
从上面的配置可以看出,atomikos连接池的最大连接数是25个,最小连接数是10个,连接最大的存活时间是500s,下面来看一下atomikos的源码。
private void init() throws ConnectionPoolException
{
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": initializing..." );
//如果连接池最小连接数没有达到就新增数据库连接
addConnectionsIfMinPoolSizeNotReached();
//开启维持连接池平衡的线程
launchMaintenanceTimer();
}
以上是Atomikos初始化的部分,先补充数据库连接池达到最小连接数,然后开启后台线程维持连接池的平衡。
private void launchMaintenanceTimer() {
int maintenanceInterval = properties.getMaintenanceInterval();
if ( maintenanceInterval <= 0 ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": using default maintenance interval..." );
maintenanceInterval = DEFAULT_MAINTENANCE_INTERVAL;
}
maintenanceTimer = new PooledAlarmTimer ( maintenanceInterval * 1000 );
maintenanceTimer.addAlarmTimerListener(new AlarmTimerListener() {
public void alarm(AlarmTimer timer) {
reapPool();
//如果达到了最大的存活时间就移除该连接
removeConnectionsThatExceededMaxLifetime();
//如果没有满足最小连接数就新增连接
addConnectionsIfMinPoolSizeNotReached();
//移除超过最小连接数以外的连接
removeIdleConnectionsIfMinPoolSizeExceeded();
}
});
TaskManager.SINGLETON.executeTask ( maintenanceTimer );
}
在配置中,maintenanceInterval的值为30,即每个30秒执行一次上述的四个方法,主要看一下removeConnectionsThatExceededMaxLifetime()这个方法。
private synchronized void removeConnectionsThatExceededMaxLifetime()
{
long maxLifetime = properties.getMaxLifetime();
if ( connections == null || maxLifetime <= 0 ) return; if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": closing connections that exceeded maxLifetime" ); Iterator<XPooledConnection> it = connections.iterator();
while ( it.hasNext() ) {
XPooledConnection xpc = it.next();
long creationTime = xpc.getCreationTime();
long now = System.currentTimeMillis();
if ( xpc.isAvailable() && ( (now - creationTime) >= (maxLifetime * 1000L) ) ) {
if ( LOGGER.isTraceEnabled() ) LOGGER.logTrace ( this + ": connection in use for more than " + maxLifetime + "s, destroying it: " + xpc );
//如果超过最大的存活时间就销毁该连接
destroyPooledConnection(xpc);
it.remove();
}
}
logCurrentPoolSize();
}
上述方法遍历数据库连接池中的所有连接,如果存活时间超过maxLifetime即500s就销毁该连接,这时由于连接池中的连接数就小于minPoolSize,所以会立即补充新的连接到连接池中。那么,系统在夜间没有用户使用时,Atomikos连接池的运行状态为:维持最小的连接数10个数据库连接,当这10个连接超过500s时就会销毁,再重新创建10个新的数据库连接,不断重复这样的操作。
四、分析与总结
下面我们开始分析产生错误日志的原因,当没有用户使用系统时,Druid连接池应该有10个空闲的连接,Atomikos连接池也有10个空闲的连接,这时Atomikos的10个连接达到了最大的生存时间500s,就需要销毁这些连接,对于Druid来说就是回收连接,调用recycle方法。由于这10个连接应该是500s之前从Druid连接池借出的,所以它们的connectTimeMillis也是500s之前的时间,即物理连接时间肯定小于8小时,可以成功回收到Druid连接池中,同时lastActiveTimeMillis也更新为当前时间,放在connections数组的末尾。
与此同时,Atomikos还需要重新生成10个新的连接,即从Druid连接池获取10个连接,调用getConnection方法,这时会进行有效性的检查,又因为lastActiveTimeMillis基本上为当前时间,所以idleMillis肯定比30s小,不需要进行select 1的连接数据库操作,这样即使该连接已经失效了还是会借出给Atomikos。每隔500s不断循环上述操作,并且期间没有用户的操作,一旦超过8个小时的Mysql连接时间,Atomikos在使用数据库连接时就会产生上述日志中的错误了。
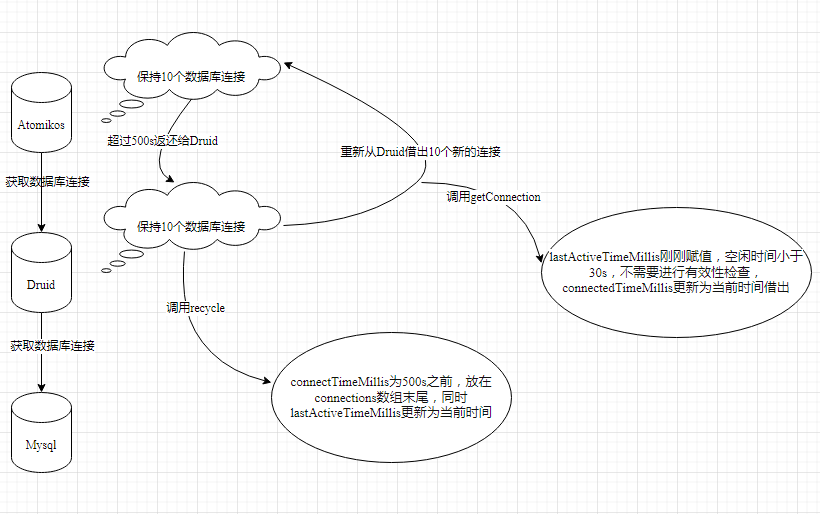
综上所述,导致报错的原因其实是使用了两层数据库连接池,这样Druid连接池借出的数据库连接并没有被实际使用,这才导致这些数据库连接成功躲避了Druid本身的检查机制。
springboot+atomikos+druid 数据库连接失效分析的更多相关文章
- Springboot + Atomikos + Druid + Mysql 实现JTA分布式事务
DataSource 配置 package com.cheng.dynamic.config; import java.util.Properties; import javax.sql.DataSo ...
- springboot整合druid数据库连接池并开启监控
简介 Druid是一个关系型数据库连接池,它是阿里巴巴的一个开源项目.Druid支持所有JDBC兼容的数据库,包括Oracle.MySQL.Derby.PostgreSQL.SQL Server.H2 ...
- SpringBoot集成druid数据库连接池的简单使用
简介 Druid是阿里巴巴旗下Java语言中最好的数据库连接池.Druid能够提供强大的监控和扩展功能. 官网: https://github.com/alibaba/druid/wiki/常见问题 ...
- springboot+mybatis+druid数据库连接池
参考博客https://blog.csdn.net/liuxiao723846/article/details/80456025 1.先在pom.xml中引入druid依赖包 <!-- 连接池 ...
- springboot自动配置国际化失效分析
最近在整理springBoot国际化时,发现国际化没有生效,通过报错提示在 MessageTag -> doEndTag处打断点 最后发现messageSource并不是ResourceBund ...
- SpringBoot 配置Druid数据库连接池
创建数据库连接池配置类 package com.boot.config; import com.alibaba.druid.pool.DruidDataSource; import com.aliba ...
- springboot+mybatis+druid+atomikos框架搭建及测试
前言 因为最近公司项目升级,需要将外网数据库的信息导入到内网数据库内.于是找了一些springboot多数据源的文章来看,同时也亲自动手实践.可是过程中也踩了不少的坑,主要原因是我看的文章大部分都是s ...
- Druid数据库连接池源码分析
上一篇文章重点介绍了一下Java的Future模式,最后意淫了一个数据库连接池的场景.本想通过Future模式来防止,当多个线程同时获取数据库连接时各自都生成一个,造成资源浪费.但是忽略了一个根本的功 ...
- atomikos + druid 连接超时失效
atomikos + druid 连接超时失效,需要多次连接才能成功. 首次连接会报异常: 2018-01-08 16:58:12 DEBUG [com.jpcar.model.dao.jpcar.A ...
随机推荐
- 食物链(poj1182)
食物链 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 57387 Accepted: 16781 Description ...
- 15 - Vue3 UI Framework - 完工部署
项目官网也基本完成了,接下来我们再讲一下如何将项目官网部署到 GitHub Pages 上 返回阅读列表点击 这里 项目配置 常见的模式有三种,即 History 模式 Hash 模式 Memory ...
- .net core中的Options重新加载机制
Options是.net core提出的一种辅助配置机制,即选项. 目前,我们可以使用的Options有五种(源码): IOptionsFactory<>:Options的创建工厂(Sin ...
- PL/SQL连接时,报无法解析指定的字符串
前言: 工作原因,需要安装PL/SQL连接数据,oracle和PL/SQL都装好了,环境变量也配好了,启动PL/SQL进行连接数据库,结果报"无法解析指定的字符串",连接失败了. ...
- hive 之 常用基本操作
show databases; -- 查看所有数据库 use 数据库; -- 进入某个数据库 select current_database(); -- 查看当前使用的数据库 show tables; ...
- Zuul的应用
一.介绍 注:Zuul中默认就已经集成了Ribbon负载均衡和Hystix熔断机制.但是所有的超时策略都是走的默认值,比如熔断超时时间只有1S,很容易就触发了. 二.依赖 <dependency ...
- git 那些事儿 —— 基于 Learn Git Branching
前言 推荐一个 git 图形化教学网站:Learn Git Branching,这个网站有一个沙盒可以直接在上面模拟 git 的各种操作,操作效果使用图形的方式展示,非常直观.本文可以看作是它的文字版 ...
- sql创建表格时出现乱码
1.新建数据库时,第一次只填写了数据库名称保存数据库,如下图: 2.创建一个Student表格,代码如下,其中有数据有中文,创建完后查看表格数据,发现中文为乱码 create table Studen ...
- Redis介绍一
一.五中数据类型 String: 字符串 Hash: 散列 List: 列表 Set: 集合 Sorted Set: 有序集合 Redis 发布订阅 Redis 发布订阅 (pub/sub) 是一种消 ...
- 【C primer plus】初始化链表函数的错误
C primer plus第六版 的一处错误 第五百页17.3.4 实现接口的程序清单17.5中的初始化链表函数有误 #源代码 void InitializeList(List * plist) { ...