Python 爬虫实战(1):分析豆瓣中最新电影的影评
目标总览
主要做了三件事:
- 抓取网页数据
- 清理数据
- 用词云进行展示
- 使用的python版本是3.6
一、抓取网页数据
第一步要对网页进行访问,python中使用的是urllib库。代码如下:
from urllib import request
resp = request.urlopen('https://movie.douban.com/nowplaying/hangzhou/')
html_data = resp.read().decode('utf-8')
其中https://movie.douban.com/nowplaying/hangzhou/是豆瓣最新上映的电影页面,可以在浏览器中输入该网址进行查看。
html_data是字符串类型的变量,里面存放了网页的html代码。
输入print(html_data)可以查看,如下图所示:
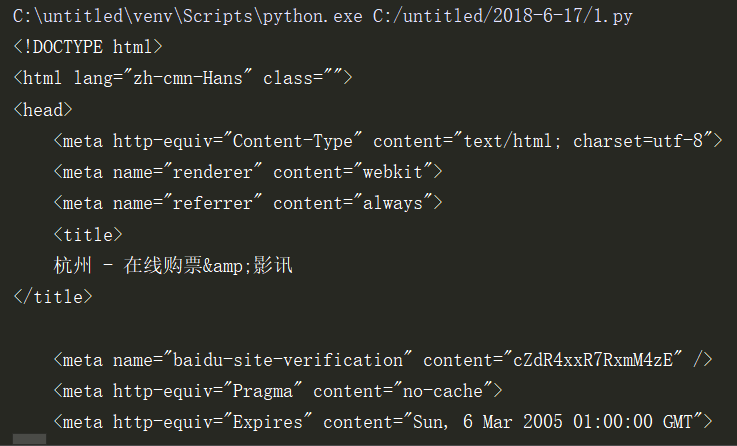
第二步,需要对得到的html代码进行解析,得到里面提取我们需要的数据。
在python中使用BeautifulSoup4库进行html代码的解析(如果没有安装此库,请先自行安装)。
BeautifulSoup使用的格式如下:
BeautifulSoup(html,"html.parser")
第一个参数为需要提取数据的html,第二个参数是指定解析器,然后使用find_all()读取html标签中的内容。
但是html中有这么多的标签,该读取哪些标签呢?其实,最简单的办法是我们可以打开我们爬取网页的html代码,然后查看我们需要的数据在哪个html标签里面,再进行读取就可以了。如下图所示:
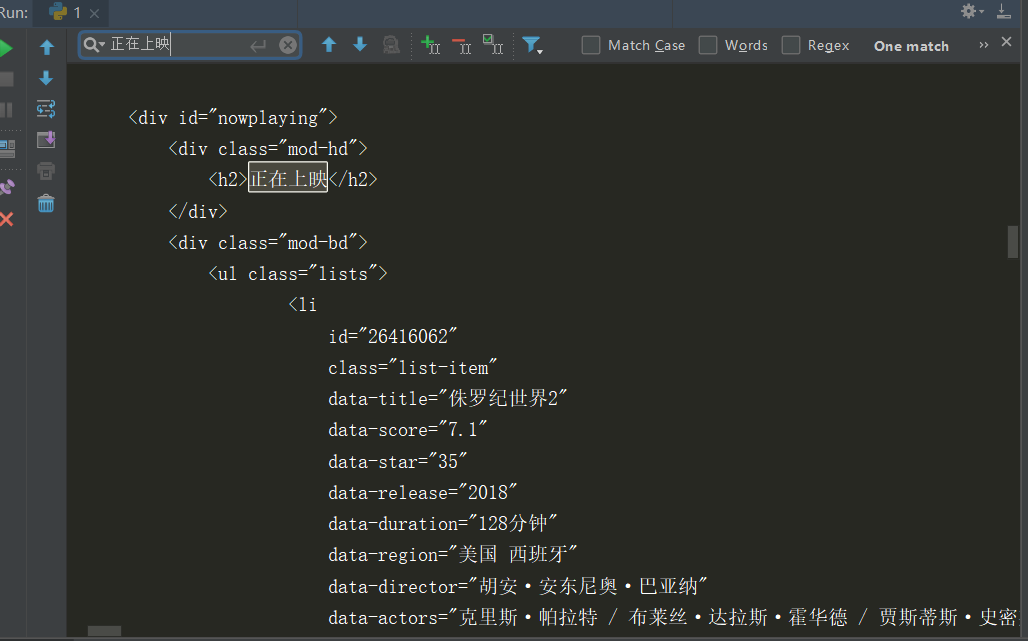
从上图中可以看出在div id=“nowplaying”标签开始是我们想要的数据,里面有电影的名称、评分、主演等信息。所以相应的代码编写如下:
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
其中nowplaying_movie_list是一个列表,可以用print(nowplaying_movie_list[0])查看里面的内容,如下图所示:
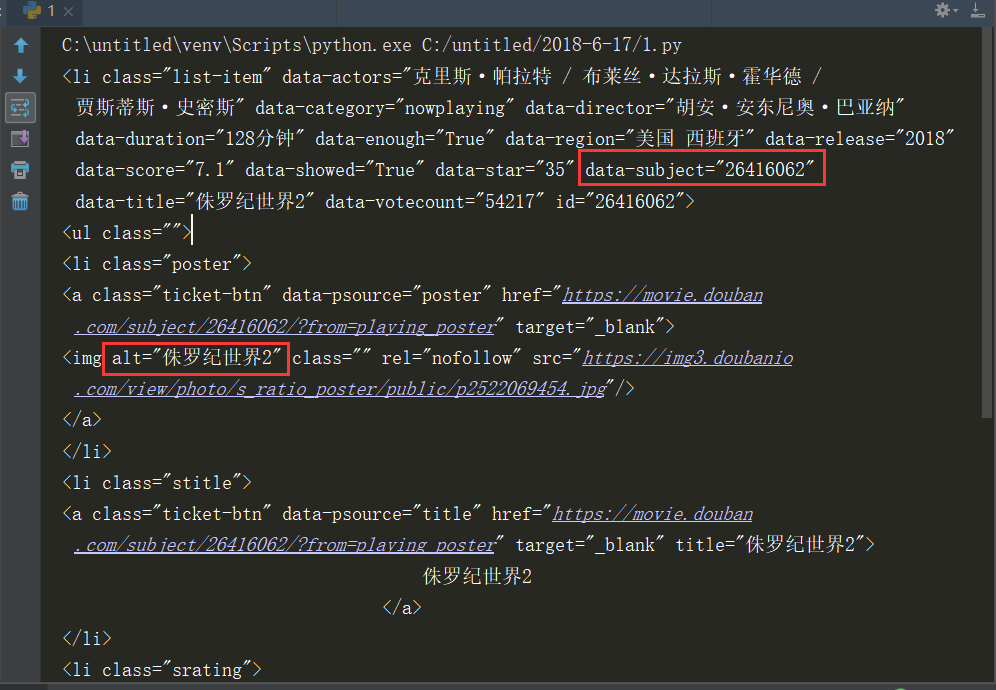
在上图中可以看大data-subject属性里放了电影的id号码,而在img标签的alt属性里面放了电影的名字,因此我们就通过这两个属性来得到电影的id和名称。(注:打开电影短评的网页时需要用到电影的id,所以需要对它进行解析),编写代码如下:
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
其中列表nowplaying_list中就存放了最新电影的id和名称,可以使用print(nowplaying_list)进行查看,如下图所示:
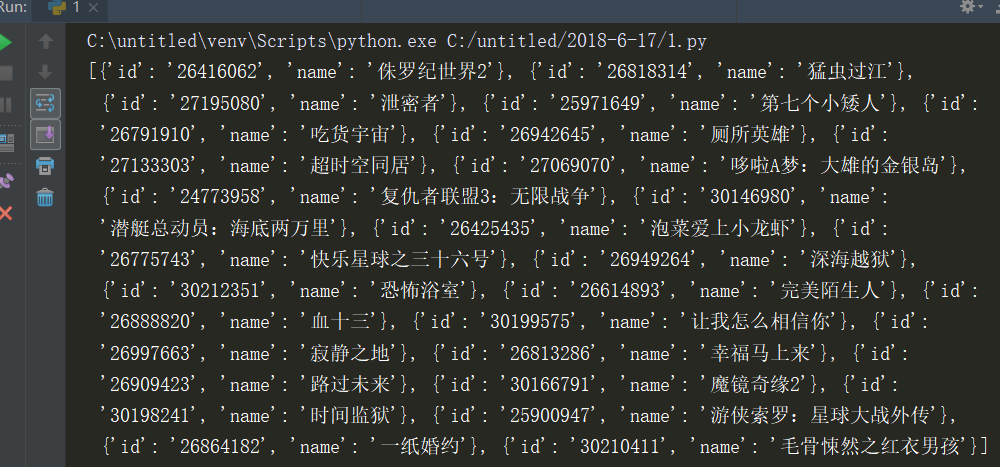
可以看到和豆瓣网址上面是匹配的。这样就得到了最新电影的信息了。接下来就要进行对最新电影短评进行分析了。例如《侏罗纪公园2》的短评网址为:https://movie.douban.com/subject/26416062/?from=playing_poster其中26416062就是电影的id。
接下来对该网址进行解析了。打开上图中的短评页面的html代码,我们发现关于评论的数据是在div标签的comment属性下面,如下图所示:

因此对此标签进行解析,代码如下:
requrl = 'https://movie.douban.com/subject/' + nowplaying_list[0]['id'] + '?from=playing_poster'
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_list = soup.find_all('div',class_='comment')
此时在comment_div_list列表中存放的就是div标签和comment属性下面的html代码了。在闪图张还可以发现在p标签下面存放了网友对电影的评论,因此对comment_div_list代码中的html代码继续进行解析,代码如下:
eachCommentList = []
for item in comment_div_list:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
使用print(eachCommentList)查看eachCommentList列表中的内容,可以看到里面存着我们想要的影评。如下图所示:
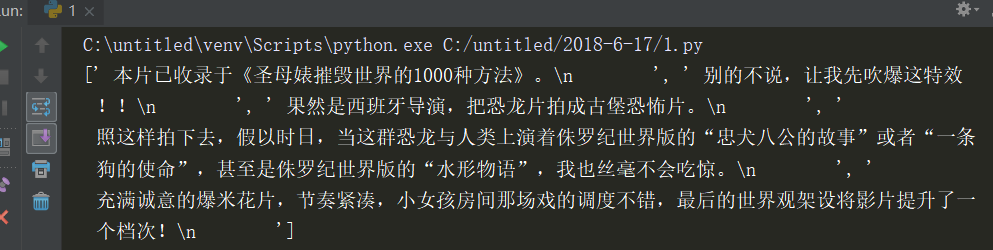
至此我们已经爬取了豆瓣最近播放电影的评论数据,接下来就要对数据进行清洗和词云显示了。
二、数据清洗
为了方便数据进行清洗,我们将列表中的数据放在一个字符串数组中,代码如下:
comments = ''
for k in range(len(eachCommentList)):
comments = comments + (str(eachCommentList[k])).strip()
使用print(comments)进行查看,如下图所示:
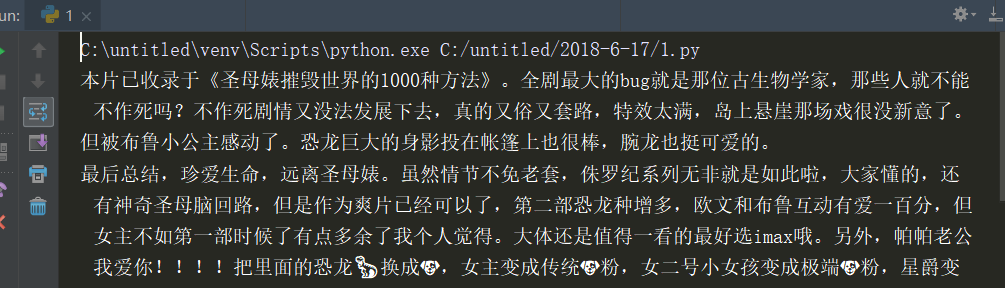
可以看到所有的评论已经变成一个字符串了,但是我们发现评论中还有不少的标点符号等。这些符号对我们进行词频统计时根本没有用,因此要将它们清除。所用的方法是正则表达式。python中正则表达式是通过re模块来实现的。代码如下:
import re
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern, comments)
cleaned_comments = ''.join(filterdata)
继续使用print(cleaned_comments)语句进行查看,如下图所示:

我们可以看到此时评论数据中已经没有那些标点符号了,数据变得“干净”了很多。
因此要进行词频统计,所以先要进行中文分词操作。在这里我使用的是结巴分词。如果没有安装结巴分词,可以在控制台使用pip install jieba进行安装。(注:可以使用pip list查看是否安装了这些库)。代码如下所示:
import jieba # 分词包
import pandas as pd segment = jieba.lcut(cleaned_comments)
words_df = pd.DataFrame({'segment': segment})
因为结巴分词要用到pandas,所以我们这里加载了pandas包。可以使用words_df.head()查看分词之后的结果,如下图所示:
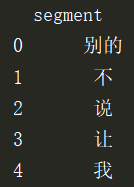
从上图可以看到我们的数据中有“别的”、“不”、“让”、“我”等虚词(停用词),而这些词在任何场景中都是高频时,并且没有实际的含义,所以我们要他们进行清除。
我把停用词放在一个stopwords.txt文件中,将我们的数据与停用词进行比对即可(注:只要在百度中输入stopwords.txt,就可以下载到该文件)。去停用词代码如下代码如下:
stopwords = pd.read_csv('stopwords.txt', index_col=False, quoting=3, sep='\t', names=['stopword'], encoding='gbk') # quoting=3全部引用
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
继续使用words_df.head()语句来查看结果,如下图所示,停用词已经被出去了。

接下来就要进行词频统计了,代码如下:
import numpy # numpy计算包
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
用words_stat.head()进行查看,结果如下:
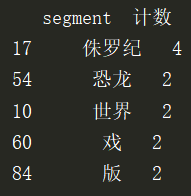
由于我们前面只是爬取了第一页的评论,所以数据有点少,在最后给出的完整代码中,我爬取了10页的评论,所数据还是有参考价值。
三、用词云进行显示
未完待续!!!
Python 爬虫实战(1):分析豆瓣中最新电影的影评的更多相关文章
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战七之计算大学本学期绩点
大家好,本次为大家带来的项目是计算大学本学期绩点.首先说明的是,博主来自山东大学,有属于个人的学生成绩管理系统,需要学号密码才可以登录,不过可能广大读者没有这个学号密码,不能实际进行操作,所以最主要的 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
随机推荐
- 小程序框架MpVue踩坑日记(二)
数据嵌套超过三层或者等于三层的时候 父组件传值给子组件后,如果子组件内的值需要改变 通过this.emit()传值后,父组件的值虽然会改变,但是视图并不会重新渲染 原因就是数据嵌套太多,没有触发ren ...
- VMware 接入 Openstack — 使用 Openstack 创建 vCenter 虚拟机
目录 目录 软件环境 前言 Openstack 接口驱动 使用 KVM 在 Compute Node 上创建虚拟机的流程 使用 VCDirver 在 vCenter 上创建虚拟机的流程 配置 vCen ...
- 05 使用bbed跳过归档恢复数据文件
5 使用BBED跳过归档 在归档模式下,缺失了一部分的归档日志文件,对数据文件进行恢复 1 开启归档 --shutdown immediate --startup mount --alter data ...
- python实现建立soap通信(调用及测试webservice接口)
实现代码如下: #调用及测试webservice接口 import requests class SoapConnect: def get_soap(self,url,data): r = reque ...
- mac 添加mysql的环境变量和删除mysql
添加环境变量 1.创建 .bash_profile,已创建过忽略这步 (1)启动终端 (2)进入当前用户的home目录(默认就是): cd ~ 或 cd /Users/YourMacU ...
- IQueryable在LINQ中
IQueryable接口定义如下: // 摘要: // 提供对未指定数据类型的特定数据源的查询进行计算的功能. public interface IQueryable : IEnumerable { ...
- SpringBoot使用webservice
Pom.xml <parent> <groupId>org.springframework.boot</groupId> <artifactId>spr ...
- JAVA总结--Spring框架全解
一.Spring简介 Spring 是个java企业级应用的开源开发框架.Spring主要用来开发Java应用,但是有些扩展是针对构建J2EE平台的web应用.Spring 框架目标是简化Java企业 ...
- BZOJ1185[HNOI2007] 最小矩形覆盖(旋转卡壳)
BZOJ1185[HNOI2007] 最小矩形覆盖 题面 给定一些点的坐标,要求求能够覆盖所有点的最小面积的矩形,输出所求矩形的面积和四个顶点的坐标 分析 首先可以先求凸包,因为覆盖了凸包上的顶点,凸 ...
- IOC详解
Ioc--控制反转详解(转载 http://www.cnblogs.com/qinqinmeiren/archive/2011/04/02/2151697.html) 本文转载与百度知道,简单例子让 ...