kmeans与kmeans++的python实现
一.kmeans聚类:
基本方法流程
1.首先随机初始化k个中心点
2.将每个实例分配到与其最近的中心点,开成k个类
3.更新中心点,计算每个类的平均中心点
4.直到中心点不再变化或变化不大或达到迭代次数
优缺点:该方法简单,执行速度较快。但其对于离群点处理不是很好,这是可以去除离群点。kmeans聚类的主要缺点是随机的k个初始中心点的选择不够严谨,因为是随机,所以会导致聚类结果准确度不稳定。
二.kmeans++聚类:
kmeans++方法是针对kmeans的主要缺点进行改进,通过在初始中心点的选择上改进不足。
中心点的选择:
1.首先随机选择一个中心点
2.计算每个点到与其最近的中心点的距离为dist,以正比于dist的概率,随机选择一个点作为中心点加入中心点集中,重复直到选定k个中心点
对于正比于dist的概率随机选择一个数据点作为新的中心点的理解有一个英文资料解释如下:

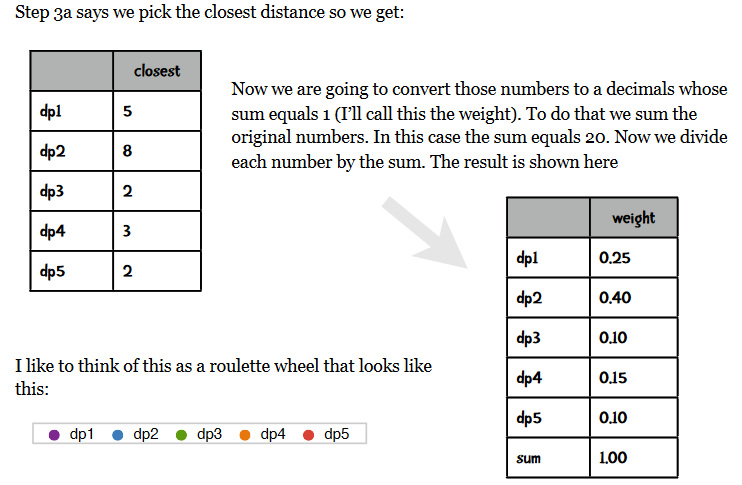

3.计算同kmeans方法
三.评估方法
误差平方和可以评估每次初始中心点选择聚类的优劣,公式如下:
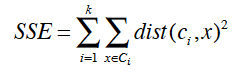
计算每个点到它自己的类的中心点的距离的平方和,外层是不同类间的和。根据每次初始点的选择聚类结果计算SSE,SSE值越小结果越好。
四.代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
import math
import codecs
import random #k-means和k-means++聚类,第一列是label标签,其它列是数值型数据
class KMeans: #一列的中位数
def getColMedian(self,colList):
tmp = list(colList)
tmp.sort()
alen = len(tmp)
if alen % 2 == 1:
return tmp[alen // 2]
else:
return (tmp[alen // 2] + tmp[(alen // 2) - 1]) / 2 #对数值型数据进行归一化,使用绝对标准分[绝对标准差->asd=sum(x-u)/len(x),x的标准分->(x-u)/绝对标准差,u是中位数]
def colNormalize(self,colList):
median = self.getColMedian(colList)
asd = sum([abs(x - median) for x in colList]) / len(colList)
result = [(x - median) / asd for x in colList]
return result '''
1.读数据
2.按列读取
3.归一化数值型数据
4.随机选择k个初始化中心点
5.对数据离中心点距离进行分配
'''
def __init__(self,filePath,k):
self.data={}#原始数据
self.k=k#聚类个数
self.iterationNumber=0#迭代次数
#用于跟踪在一次迭代改变的点
self.pointsChanged=0
#误差平方和
self.SSE=0
line_1=True
with codecs.open(filePath,'r','utf-8') as f:
for line in f:
# 第一行为描述信息
if line_1:
line_1=False
header=line.split(',')
self.cols=len(header)
self.data=[[] for i in range(self.cols)]
else:
instances=line.split(',')
column_0=True
for ins in range(self.cols):
if column_0:
self.data[ins].append(instances[ins])# 0列数据
column_0=False
else:
self.data[ins].append(float(instances[ins]))# 数值列
self.dataSize=len(self.data[1])#多少实例
self.memberOf=[-1 for x in range(self.dataSize)] #归一化数值列
for i in range(1,self.cols):
self.data[i]=self.colNormalize(self.data[i]) #随机从数据中选择k个初始化中心点
random.seed()
#1.下面是kmeans随机选择k个中心点
#self.centroids=[[self.data[i][r] for i in range(1,self.cols)]
# for r in random.sample(range(self.dataSize),self.k)]
#2.下面是kmeans++选择K个中心点
self.selectInitialCenter() self.assignPointsToCluster() #离中心点距离分配点,返回这个点属于某个类别的类型
def assignPointToCluster(self,i):
min=10000
clusterNum=-1
for centroid in range(self.k):
dist=self.distance(i,centroid)
if dist<min:
min=dist
clusterNum=centroid
#跟踪改变的点
if clusterNum!=self.memberOf[i]:
self.pointsChanged+=1
#误差平方和
self.SSE+=min**2
return clusterNum #将每个点分配到一个中心点,memberOf=[0,1,0,0,...],0和1是两个类别,每个实例属于的类别
def assignPointsToCluster(self):
self.pointsChanged=0
self.SSE=0
self.memberOf=[self.assignPointToCluster(i) for i in range(self.dataSize)] # 欧氏距离,d(x,y)=math.sqrt(sum((x-y)*(x-y)))
def distance(self,i,j):
sumSquares=0
for k in range(1,self.cols):
sumSquares+=(self.data[k][i]-self.centroids[j][k-1])**2
return math.sqrt(sumSquares) #利用类中的数据点更新中心点,利用每个类中的所有点的均值
def updateCenter(self):
members=[self.memberOf.count(i) for i in range(len(self.centroids))]#得到每个类别中的实例个数
self.centroids=[
[sum([self.data[k][i] for i in range(self.dataSize)
if self.memberOf[i]==centroid])/members[centroid]
for k in range(1,self.cols)]
for centroid in range(len(self.centroids))] '''迭代更新中心点(使用每个类中的点的平均坐标),
然后重新分配所有点到新的中心点,直到类中成员改变的点小于1%(只有不到1%的点从一个类移到另一类中)
'''
def cluster(self):
done=False
while not done:
self.iterationNumber+=1#迭代次数
self.updateCenter()
self.assignPointsToCluster()
#少于1%的改变点,结束
if float(self.pointsChanged)/len(self.memberOf)<0.01:
done=True
print("误差平方和(SSE): %f" % self.SSE) #打印结果
def printResults(self):
for centroid in range(len(self.centroids)):
print('\n\nCategory %i\n=========' % centroid)
for name in [self.data[0][i] for i in range(self.dataSize)
if self.memberOf[i]==centroid]:
print(name) #kmeans++方法与kmeans方法的区别就是初始化中心点的不同
def selectInitialCenter(self):
centroids=[]
total=0
#首先随机选一个中心点
firstCenter=random.choice(range(self.dataSize))
centroids.append(firstCenter)
#选择其它中心点,对于每个点找出离它最近的那个中心点的距离
for i in range(0,self.k-1):
weights=[self.distancePointToClosestCenter(x,centroids)
for x in range(self.dataSize)]
total=sum(weights)
#归一化0到1之间
weights=[x/total for x in weights] num=random.random()
total=0
x=-1
while total<num:
x+=1
total+=weights[x]
centroids.append(x)
self.centroids=[[self.data[i][r] for i in range(1,self.cols)] for r in centroids] def distancePointToClosestCenter(self,x,center):
result=self.eDistance(x,center[0])
for centroid in center[1:]:
distance=self.eDistance(x,centroid)
if distance<result:
result=distance
return result #计算点i到中心点j的距离
def eDistance(self,i,j):
sumSquares=0
for k in range(1,self.cols):
sumSquares+=(self.data[k][i]-self.data[k][j])**2
return math.sqrt(sumSquares) if __name__=='__main__':
kmeans=KMeans('filePath',3)
kmeans.cluster()
kmeans.printResults()
参考:1.machine.learning.an.algorithmic.perspective.2nd.edition.
2.a programmer's guide to data mining
kmeans与kmeans++的python实现的更多相关文章
- K-Means clusternig example with Python and Scikit-learn(推荐)
https://www.pythonprogramming.net/flat-clustering-machine-learning-python-scikit-learn/ Unsupervised ...
- 4. K-Means和K-Means++实现
1. K-Means原理解析 2. K-Means的优化 3. sklearn的K-Means的使用 4. K-Means和K-Means++实现 1. 前言 前面3篇K-Means的博文从原理.优化 ...
- K-Means ++ 和 kmeans 区别
Kmeans算法的缺陷 聚类中心的个数K 需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适Kmeans需要人为地确定初始聚类中心 ...
- Spark2.0机器学习系列之9: 聚类(k-means,Bisecting k-means,Streaming k-means)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- K-means聚类算法及python代码实现
K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的) 1.概述 K-means算法是集简单和经典于一身的基于距离的聚类算法 采用距离作为相似性的评价指标,即认为两个对象的距离越近,其 ...
- kmeans算法思想及其python实现
第十章 利用k-均值聚类算法对未标注的数据进行分组 一.导语 聚类算法可以看做是一种无监督的分类方法,之所以这么说的原因是它和分类方法的结果相同,区别它的类别没有预先的定义.簇识别是聚类算法中经常使用 ...
- K-means clustering (K-means聚类)
问题: K-所有值聚类是无监督学习算法 设数据集.当中,. 如果这个数据能够分为类. 把这个问题模型化: , 当中代表第类的聚点(中心点.均值). 该模型能够用EM算法进行训练: 初始化,. E步:固 ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- Python—kmeans算法学习笔记
一. 什么是聚类 聚类简单的说就是要把一个文档集合根据文档的相似性把文档分成若干类,但是究竟分成多少类,这个要取决于文档集合里文档自身的性质.下面这个图就是一个简单的例子,我们可以把不同的文档聚合 ...
随机推荐
- CentOS7通过YUM安装NGINX稳定版本
创建 nginx.repo 文件 $ cd /etc/repos.d/ $ vim nginx.repo #写入以下内容 [nginx-stable] name=nginx stable repo b ...
- 多进程-Pool进程池
from multiprocessing import Pool import os,time def Foo(i): time.sleep(2) print("in process&quo ...
- 开发MT4连接失败最easy忽视的一个错误
m_factory.WinsockStartup();
- 104、验证Swarm数据持久性 (Swarm11)
参考https://www.cnblogs.com/CloudMan6/p/8016994.html 上一节我们成功将 nfs 的volume挂载到 Service上,本节验证 Failover时 ...
- 这十个MySQL经典错误
今天就给大家列举 MySQL 数据库中,最经典的十大错误案例,并附有处理问题的解决思路和方法,希望能给刚入行,或数据库爱好者一些帮助,今后再遇到任何报错,我们都可以很淡定地去处理.学习任何一门技术的同 ...
- echarts-迁徙图地点图标颜色修改
引用:https://gallery.echartsjs.com/editor.html?c=xLSy9AUmlA var uploadedDataURL = "/asset/get/s/d ...
- MySQL 中 EXISTS 的用法
在MySQL中 EXISTS 和 IN 的用法有什么关系和区别呢? 假定数据库中有两个表 分别为 表 a 和表 b create table a ( a_id int, a_name varchar( ...
- python 出现OSError: [Errno 8] Exec format error的原因
访问 .py文件的网页的时候会出现 Exec format error的问题, 一般情况下是由于基于Unix(Linux,Mac OS)系统下的问题,办法如下 1 .chmod +x filenam ...
- Delphi Timer组件
- matplotlib:python数据处理三剑客之一
1.基本使用 import numpy as np import matplotlib.pyplot as plt import pandas as pd # 生成一系列x x = np.linspa ...