week5 作业
week5 作业
1.描述GPT是什么,应该怎么使用?
描述GPT之前要简单了解MBR分区,MBR(Main Boot Record)叫做主引导记录,其位于磁盘的最前端,由一段代码组成,共占用512个字节。是计算机开机时读取的首个磁盘扇区,由三部分组成:
- 主引导程序即主引导记录(MBR)(占446个字节),启动代码
- 分区表(DPT,Disk Partition Table)由四个分区表构成,每个占用16字节,共占用64字节
- 结束标志 55aa
由此可见,利用MBR分区最多只能有4个分区,每个分区的最大容量为2T,因此出现了GPT分区。
GPT:GUID(Globals Unique Identifiers) partition table ,全局唯一标识分区表,实体硬盘的分区表的结构布局的标准,区别于MBR。支持128个分区,使用64位,支持8Z( 512Byte/block )64Z ( 4096Byte/block)。
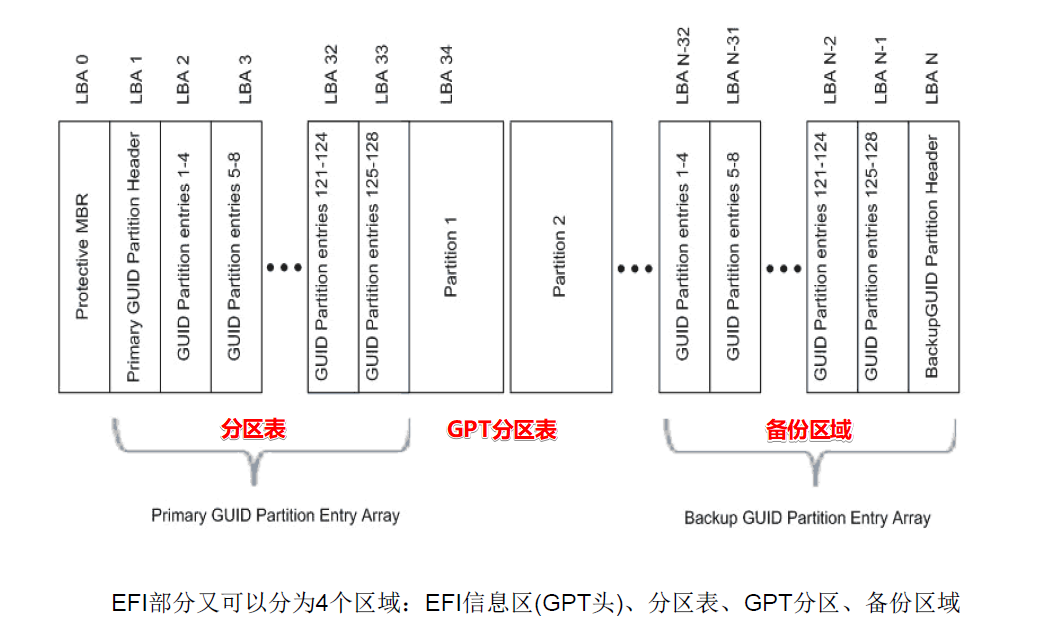
由四部分组成:保护MBR区、EFI信息区(GPT头)、分区表、GPT分区区域、备份区域;
- 保护MBR分区(LBA0) :MBR分区过度GPT分区,防止无法识别MBR分区。实际上,EFI根本用不上这个分区表。
- GPT头:起始于磁盘的LBA1,通常也只占用这个单一扇区。其作用是定义分区表的位置和大小。GPT头还包含头和分区表的校验和,这样就可以及时发现错误。
- 分区表:分区表区域包含分区表项。这个区域由GPT头定义,一般占用磁盘LBA2~LBA33扇区。分区表中的每个分区项由起始地址、结束地址、类型值、名字、属性标志、GUID值组成。分区表建立后,128位的GUID对系统来说是唯一的。
- GPT分区区域:最大的区域,由分配给分区的扇区组成。这个区域的起始和结束地址由GPT分区表定义。
- 备份区域:备份区域位于磁盘的尾部,包含GPT头和分区表的备份。它占用GPT结束扇区和EFI结束扇区之间的33个扇区。其中最后一个扇区用来备份1号扇区的EFI信息,其余的32个扇区用来备份LBA2~LBA33扇区的分区表。
GPT只是一种分区方式,使用gdisk工具进行分区,分区后的使用还是要格式化,挂载。
注意:要想使用GPT分区表必须是UEFI BIOS环境,UEFI和GPT相辅相成的,二者缺一不可
UEFI:全称“统一的可扩展固件接口”(Unified Extensible Firmware Interface), 是一种详细描述类型接口的标准。这种接口用于操作系统自动从预启动的操作环境,加载到一种操作系统上。
2.创建一个10G的分区,并格式化为ext4文件系统。要求:
(1)block大小为2048k,预留空间为20%,卷标为MYDATA;
(2)挂载至/mydata目录,要求挂载时禁止程序自动运行,且不更新文件的访问时间戳;
(3)可开机自动挂载。
首先,fdisk 一个10G的分区。
mke2fs -t ext4 -b 2048 -m 20 -L MYDATA /dev/sdb1 # 格式化分区
mount -o noexec,noatime /dev/sdb1 /mydata
vim /etc/fstab # 修改配置文件
UUID=103878ff-76c0-4f88-ac51-5fbc9828b39d /mydata ext4 defaults,noexec,noatime 0 0 # fstab配置文件中添加此条
3.创建1个大小为10G的swap分区,并启用
有两种设备可以作为swap分区:
①磁盘设备,一般单独一个新磁盘的第一个分区作为swap分区,因为靠外侧的磁道性能更好;
fdisk 一个10G的分区
注意:将分区类型改为82 -swap类型
②loop设备,
dd if=/dev/zero of=/data/swaptest bs=100M count=100 创建大小为10G名字为swaptest的文件
后面的操作相同如下:
mkswap /dev/sdb1
vim /etc/fstab # 修改配置文件,加入刚刚格式化的swap分区
swapon -a 启用swap分区
也可以不写入配置文件,直接
swapon /dev/sdb1 # 这样下次开机时该swap分区自动取消。
4.编写脚本计算/etc/passwd文件中第10个和第20个的用户ID之和。
#!/bin/bash
ID1=`getent passwd | head -n10 | tail -n1 | cut -d: -f3`
ID2=`getent passwd | head -n20 | tail -n1 | cut -d: -f3`
sumID=$[$ID1+$ID2]
echo $sumID
5.将当前计算机名保存至hostName中,主机名如果为空,或者为localhost.localdomain则设置为www.magedu.com
#!/bin/bash
hostName=`hostname`
[ -z "$hostName" -o "$hostName" == "localhost.localdomain" -o "hostName" == "localhost" ] && hostname www.magedu.com
6.编写脚本,通过一个命令行参数传入一个用户,判断id号是奇数还是偶数。
#!/bin/bash
[ $# -ne 1 ] && echo "please input only one args " && exit
id $1 &>/dev/null || echo "$1 is not exist,creating the user $1 now,please wait a minute "
sleep 2
useradd $1 && echo "user $1 is cteated "
uid=`grep "\<$1\>" /etc/passwd | cut -d: -f3`
yushu=$[ $uid%2 ]
[ $yushu -eq 0 ] && echo "此用户的id号为偶数" || echo “此用户的id号为奇数”
输出结果测试:
[root@CentOS7 data]#bash yushuUID.sh sst
useradd: user 'sst' already exists
“此用户的id号为奇数”
[root@CentOS7 data]#bash yushuUID.sh sst3
sst3 is not exist,creating the user sst3 now,please wait a minute
user sst3 is cteated
此用户的id号为偶数
7.lvm基本应用以及扩展缩减实现。
LVM基本运用参考此博文LVM
week5 作业的更多相关文章
- 《Linux内核分析》 week5作业-system call中断处理过程
一.使用gdb跟踪分析一个系统调用内核函数 1.在test.c文件中添加time函数与采用c语言内嵌汇编的time函数.具体实现请看下图. 2.然后在main函数中添加MenuConfig函数,进行注 ...
- Daily Scrum (2015/10/26)
今晚由于我们组成员就团队Week5作业的个人贡献分开会协商,所以把今天的编码工作往后延迟了.考虑到有些成员代码还没理解够,正好TFS的代码阅读分配的工作时间还没进行完,所以在会议之后我们让成员回寝自由 ...
- 个人博客作业week5
请阅读下述关于敏捷开发方法文章,并在个人博客上写一篇读后感. Martin Fowler: http://martinfowler.com/agile.html 截止时间:10月20日前.
- 团队作业Week5之团队贡献分的分配
一.团队贡献分的分配规则 首先,我们团队共有5个人,平均每个人50分,所以我们团队的总分为5*50=250,我们先把50分分成以下几份: 序号 贡献类型 权重 分数 1 代码贡献 40% 20 * 5 ...
- 个人阅读作业Week5
一.总结体会 团队项目已经进行了很多周,我们团队从刚开始的基础薄弱到现在的大家都可以运用Android来编写程序,共同完成一个app的开发使用. 刚开始做团队项目之时,我们团队就开了一个会,确定了以后 ...
- 团队作业Week5
每个团队开一个讨论会,协商讨论团队贡献分的分配方式.每个团队的团队贡献分为50分/人.每个人分数不能相同,请详细说明分数的分配规则. 可参考这个博客. 截止时间:2014-10-27
- 团队博客作业Week5 --- 团队贡献分--分配规则
团队会议 时间:公元2015年10月26日22时3分20秒 地点:宿舍楼716房间 与会人员:陈谋,李剑锋,卢惠民,刘夕霆,仉伯龙,潘成鼎. 会议内容:今天的组会主要讨论的是项目团队贡献分的计算方式, ...
- Spark小课堂Week5 Scala初探
Spark小课堂Week5 Scala初探 Scala是java威力加强版. 对Java的改进 这里会结合StreamingContext.scala这个代码说明下对Java的改进方面. 方便测试方式 ...
- 《Using Python to Access Web Data》 Week5 Web Services and XML 课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week5 Web Services and XML 13.1 Data on the ...
随机推荐
- MYSQL join 优化 --JOIN优化实践之快速匹配
MySQL的JOIN(四):JOIN优化实践之快速匹配 优化原则:小表驱动大表,被驱动表建立索引有效,驱动表建立索引基本无效果.A left join B :A是驱动表,B是被驱动表:A right ...
- Linux下用OTL操作MySql(包含自己封装的类库及演示样例代码下载)
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/ClamReason/article/details/23971805 首先重点推荐介绍otl介绍及使 ...
- windows下php配置环境变量
这样重启终端后,通过php -v可查看新使用的php版本信息. 注:在path配置在上方的先生效
- 客户端相关知识学习(二)之h5与原生app交互的原理
前言 现在移动端 web 应用,很多时候都需要与原生 app 进行交互.沟通(运行在 webview中),比如微信的 jssdk,通过 window.wx 对象调用一些原生 app 的功能.所以,这次 ...
- 16 Scrapy之分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 重学JavaScript之匿名函数
1. 什么是匿名函数? 匿名函数就是没有名字的函数,有时候也称为< 拉姆达函数>.匿名函数是一种强大的令人难以置信的工具.如下: function a(a1, a2, a3) { // 函 ...
- springboot访问出错,mapperScan导包错误java.lang.NoSuchMethodException: tk.mybatis.mapper.provider.base.BaseSelectProvider.<init>() at java.lang.Class.getConstructor0(Class.java:3082) ~[na:1.8.0_172] at java.
2019-08-06 12:42:03.153 ERROR 10080 --- [nio-8080-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Se ...
- Delphi 参数的传递
- linux下创建软链--laravel软链
ln -s /www/wwwroot/project_name/storage/app/public/ /www/wwwroot/project_name/public/storage
- 自动化运维——MySQL备份脚本(二)
使用if语句编写MySQL备份脚本 代码: #!/bin/bash #auro backup mysql db #by steve yu #define backup path BAK_DIR=/da ...