AI-IBM-cognitive class --Liner Regression
Liner Regression
import matplotlib.pyplot as plt
import pandas as pd
import pylab as pl
import numpy as np
%matplotlib inline
%motib inline
%matplotlib作用
- 是在使用jupyter notebook 或者 jupyter qtconsole的时候,才会经常用到%matplotlib,
- 而%matplotlib具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。
在spyder或者pycharm实际运行代码的时候,可以注释掉这一句
下载数据包
!wget -O FuelConsumption.csv https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/FuelConsumptionCo2.csv
df = pd.read_csv("./FuelConsumptionCo2.csv") # use pandas to read csv file.
# take a look at the dataset, show top 10 lines.
df.head(10)
out:

# summarize the data
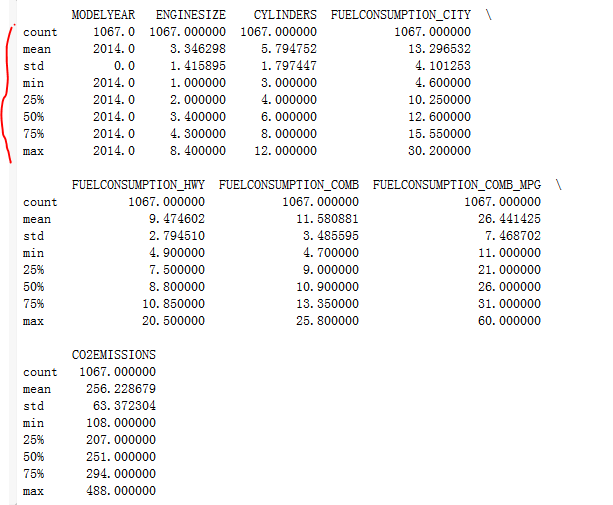
print(df.describe())
使用describe函数进行表格的预处理,求出最大最小值,已经分比例的数据。
out:
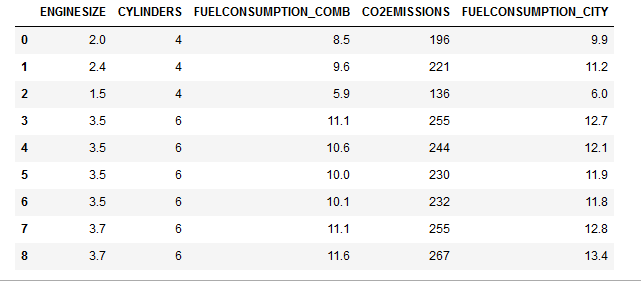
进行表格的重新组合, 提取出我们关心的数据类型。
out:
cdf = df[['ENGINESIZE','CYLINDERS','FUELCONSUMPTION_COMB','CO2EMISSIONS','FUELCONSUMPTION_CITY']]
cdf.head(9)
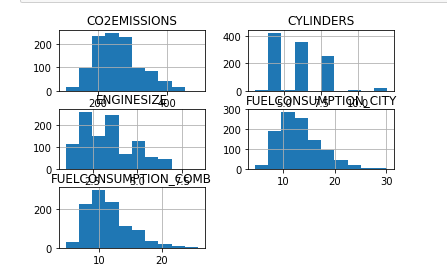
每一列数据可生成hist(直方图)
viz = cdf[['CYLINDERS','ENGINESIZE','CO2EMISSIONS','FUELCONSUMPTION_COMB','FUELCONSUMPTION_CITY']]
viz.hist()
plt.show()
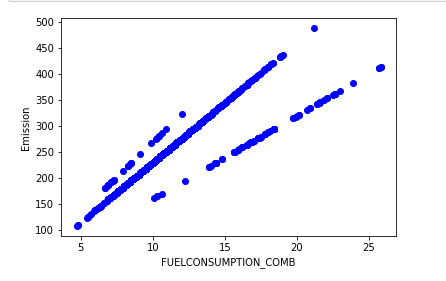
使用scatter生成散列图, 定义散列图的参数, 颜色
具体使用可参考连接:https://blog.csdn.net/qiu931110/article/details/68130199
plt.scatter(cdf.FUELCONSUMPTION_COMB, cdf.CO2EMISSIONS, color='blue')
plt.xlabel("FUELCONSUMPTION_COMB")
plt.ylabel("Emission")
plt.show()
选择表中len长度小于8的数据, 创建训练集合测试集,并生成散列图
Creating train and test dataset
Train/Test Split involves splitting the dataset into training and testing sets respectively, which are mutually exclusive. After which, you train with the training set and test with the testing set. This will provide a more accurate evaluation on out-of-sample accuracy because the testing dataset is not part of the dataset that have been used to train the data. It is more realistic for real world problems.
This means that we know the outcome of each data point in this dataset, making it great to test with! And since this data has not been used to train the model, the model has no knowledge of the outcome of these data points. So, in essence, it is truly an out-of-sample testing.
msk = np.random.rand(len(df)) < 0.8
train = cdf[msk]
test = cdf[~msk]
print(train)
print(test)
plt.scatter(train.ENGINESIZE, train.CO2EMISSIONS, color='blue')
plt.xlabel("Engine size")
plt.ylabel("Emission")
plt.show()

Modeling: Using sklearn package to model data.
from sklearn import linear_model
regr = linear_model.LinearRegression()
train_x = np.asanyarray(train[['ENGINESIZE']])
train_y = np.asanyarray(train[['CO2EMISSIONS']])
regr.fit (train_x, train_y)
# The coefficients
print ('Coefficients: ', regr.coef_)
print ('Intercept: ',regr.intercept_)
out:
Coefficients: [[39.64984954]]
Intercept: [124.08949291] As mentioned before, Coefficient and Intercept in the simple linear regression, are the parameters of the fit line. Given that it is a simple linear regression,
with only 2 parameters, and knowing that the parameters are the intercept and slope of the line, sklearn can estimate them directly from our data.
Notice that all of the data must be available to traverse and calculate the parameters.
plt.scatter(train.ENGINESIZE, train.CO2EMISSIONS, color='blue')
plt.plot(train_x, regr.coef_[0][0]*train_x + regr.intercept_[0], '-r')
# 通过斜率和截距画出线性回归曲线
plt.xlabel("Engine size")
plt.ylabel("Emission")
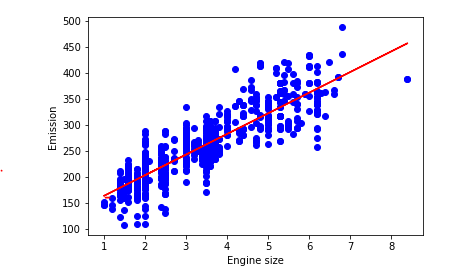
使用sklearn.linear_model.LinearRegression进行线性回归 参考以下连接:
https://www.cnblogs.com/magle/p/5881170.html
AI-IBM-cognitive class --Liner Regression的更多相关文章
- (三)用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- CS229 3.用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- (线性回归)Liner Regression简单应用
警告:本文为小白入门学习笔记 数据连接: http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearni ...
- (转)A curated list of Artificial Intelligence (AI) courses, books, video lectures and papers
A curated list of Artificial Intelligence (AI) courses, books, video lectures and papers. Updated 20 ...
- (四)Logistic Regression
1 线性回归 回归就是对已知公式的未知参数进行估计.线性回归就是对于多维空间中的样本点,用特征的线性组合去拟合空间中点的分布和轨迹,比如已知公式是y=a∗x+b,未知参数是a和b,利用多真实的(x,y ...
- 广义线性模型 GLM
Logistic Regression 同 Liner Regression 均属于广义线性模型,Liner Regression 假设 $y|x ; \theta$ 服从 Gaussian 分布,而 ...
- 决策树之 CART
继上篇文章决策树之 ID3 与 C4.5,本文继续讨论另一种二分决策树 Classification And Regression Tree,CART 是 Breiman 等人在 1984 年提出的, ...
- [machine learning] Loss Function view
[machine learning] Loss Function view 有关Loss Function(LF),只想说,终于写了 一.Loss Function 什么是Loss Function? ...
- 【转】Loss Function View
感谢原文作者!原文地址:http://eletva.com/tower/?p=186 一.Loss Function 什么是Loss Function?wiki上有一句解释我觉得很到位,引用一下:Th ...
随机推荐
- HTML表单(来自MDN的总结)
表单介绍 HTML表单是用户和web站点或应用程序之间交互的主要内容之一.它们允许用户将数据发送到web站点.大多数情况下,数据被发送到web服务器,但是web页面也可以拦截它自己并使用它. HTML ...
- javascript笔记收集
因为前端编程的兴起, 慢慢地对css/javascript越来越淡, 偶尔用一下,得查半天资料. 这里就收藏一下比较生僻, 但是做工具时会用到的. json获取属性名 Object.keys(), 只 ...
- RMQ Fanout
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11795256.html RMQ Fanout Project Directory Maven Depe ...
- 如何Docker化任意一个应用
网上有很多关于如何将应用Docker化的教程,为什么我还要再写一个呢? 我见过的大部分教程都是限定在某种特定技术(例如Java或者Python),可能无法满足读者的需求.同时,这些教程也没有说清楚关于 ...
- luoguP4721 【模板】分治 FFT (分治NTT)
给定 $g[1....n-1]$,求 $f[0],f[1],...,f[n-1]$,其中 $f[i]=\sum_{j=1}^{i}f[i-j]g[j]$ 变界为 $f[0]=1$ 答案模 9 ...
- android开发里跳过的坑——GridView使用Glide加载图片不显示
用grideview显示本地图片列表,用了Glide加载框架,具体调用如下: Glide.with(mContext).load(Uri.fromFile(file)).into(imageView) ...
- pandas 之dataFrame 数据显示不完全的解决方案
对于这种省略部分,可以使用set_option进行设置,就可以看到了. # 显示所有行(参数设置为None代表显示所有行,也可以自行设置数字) pd.set_option('display.max_c ...
- ubuntu 虚拟机安装vmware tools
1.打开ubuntu虚拟机,点击“虚拟机”---> "安装 vmware tools" 2.进入vmware tools光盘,将VMwaretools压缩包复制粘贴到桌面 ...
- gitlab+jenkins自动化打包IOS-jenkins配置
实现的效果如图: 构建界面: 完成效果: 功能说明: 根据选择的代码分支,执行构建打包 构建成功后根据ipa/apk生成二维码,并可在历史构建列表中展示各个版本的二维码,通过手机扫描二维码可直接安装 ...
- Ajax对数据的删除与查看
1.数据库找一张表: 颜色表2.主页面主页面的代码用到tbody:TBODY作用是:可以控制表格分行下载,从而提高下载速度.(网页的打开是先表格的的内容全部下载完毕后,才显示出来,分行下载可以先显示部 ...