Kosaraju与Tarjan(图的强连通分量)
Kosaraju
这个算法是用来求解图的强连通分量的,这个是图论的一些知识,前段时间没有学,这几天在补坑...
强连通分量:
有向图中,尽可能多的若干顶点组成的子图中,这些顶点都是相互可到达的,则这些顶点成为一个强连通分量
如下图所示,a、b、e以及f、g和c、d、h各自构成一个强联通分量
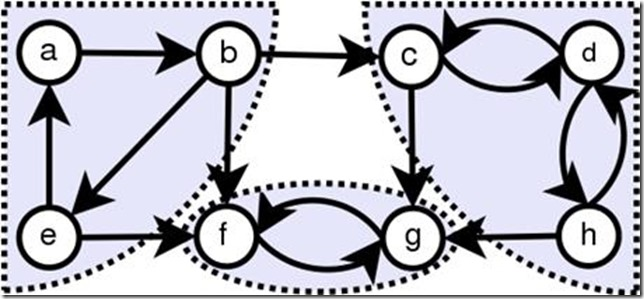
Kosaraju的求解方法
对于一个无向图的连通分量,从连通分量的任意一个顶点开始进行一次DFS,一定是可以遍历这个连通分量的所有定点的。所以,整个图的连通分量数就等价于我们对于这个图找了几次起点(也就是我们遍历这个图了几次DFS)。在这其中我们每一次遍历中所得到的定点属于同一个连通分量。
我们从无向图来推向有向图:
我们为了求得这个图的强联通分量,我们就需要对其进行DFS遍历,而顺序正遍历的DFS的过程是显然的,我们仍需要一种遍历顺序来满足可以达到我们可以使得每一个强联通分量都可以被遍历到且遍历的顺序是有序的算法。
逆后序遍历:
DFS的逆后序遍历指的是假如到达了A节点且A节点并没有被访问过,就去遍历与A节点相连的且没有被访问的其他节点,然后将这些节点假如栈中,最后这个栈从栈顶到栈底的顺序DFS逆后序遍历。
Kosaraju的步骤过程
对于任意的两个强联通分量之间是不可能存在有两条路互相连接形成环的(这是显然的,因为如果有环我们即需要将其看成是同一个强联通分量)。
所以求解的步骤可以分为以下两步:
第一步:
对原图取反,从任意一个顶点开始对反向图进行逆后续DFS遍历
第二步:
按照逆后续遍历中栈中的顶点出栈顺序,对原图进行DFS遍历,一次DFS遍历中访问的所有顶点都属于同一强连通分量。
证明算法的正确性:
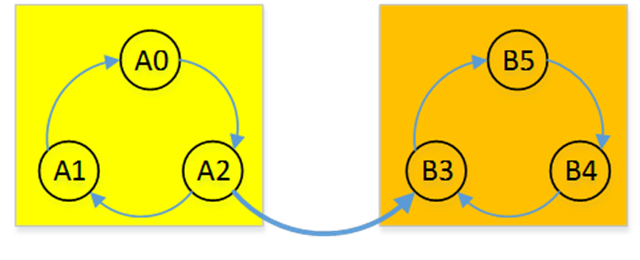
假设这一个图是需要求解强联通分量的图
那么对于这个图进行取反就得到了这个图: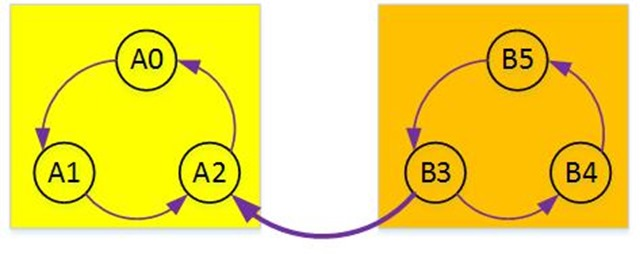
一共有两种DFS的可能性:
从A点开始:
假设DFS从位于强连通分量A中的任意一个节点开始。那么第一次DFS完成后,栈中全部都是强连通分量A的顶点,第二次DFS完成后,栈顶一定是强连通分量B的顶点。
从B点开始:
假设DFS从位于强连通分量B中的任意一个顶点开始。显然我们只需要进行一次DFS就可以遍历整个图,由于是逆后续遍历,那么起始顶点一定最后完成,所以栈顶的顶点一定是强连通分量B中的顶点。
所以对于每一次DFS,都会有一个对应的强联通分量,证毕
Code:
void dfsone(int x)
{
vst[x] = ;
for(int i=;i<=n;i++)
if(!vst[i] && map[x][i])
dfsone(i);
d[++t] = x; //最后访问的节点
}
//d[i] = x : i -> 组 x -> 节点 void dfstwo(int x)
{
vst[x] = t;
for(int i=;i<=n;i++)
if(!vst[i] && map[i][x])
dfstwo(i);
} void kosaraju()
{
int t = ;
for(int i=;i<=n;i++)
if(!vst[i])
dfsone(i);
memset(vst,,sizeof(vst));
t = ;
for(int i=n;i>=;i--)
if(!vst[d[i]])
{
t++;
dfstwo(d[i]);
}
}
以上就是Kosaraju
接下来开始Tarjan
Tarjan
Tarjan是一种基于DFS的算法 ,图中每个强连通分量为搜索树的一棵子树
我们在DFS的过程中会遇到四种边:
树枝边:一条经过的边,即DFS搜索树上的一条边
前向边:与DFS方向一致,从某个节点指向其子孙的边
后向边:与DFS方向相反,从某个节点指向其祖先的边
横叉边:从某个节点指向搜索树中另一子树的某节点的边
定义一下:
DFN[i]:在DFS中该节点被搜索的次序(时间戳)
LOW[i]:为i或i的子树能够追溯到的最早的栈中节点的次序号
那么我们就可以显然地得到:
如果(u,v)为树枝边,u为v的父节点,则 LOW[u] = min(LOW[u],LOW[v])
如果(u,v)为后向边或者是指向栈中节点的横叉边,则 LOW[u] = min(LOW[u],DFN[v])
当节点u的搜索过程结束后,如果当DFN[ i ]==LOW[ i ]时,为i或i的子树可以构成一个强连通分量。
算法过程:
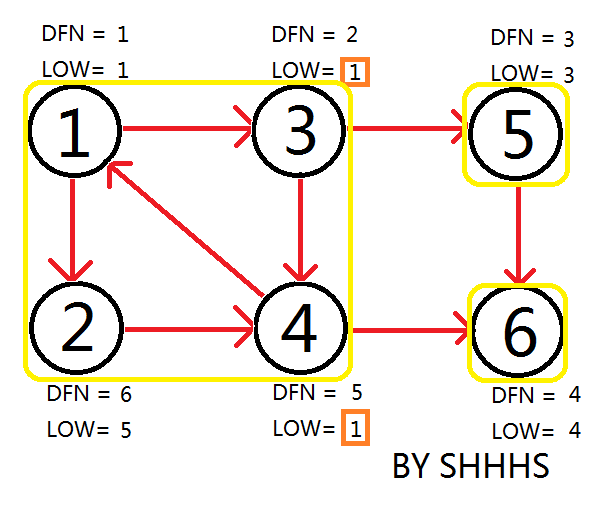
以1为Tarjan 算法的起始点,如图
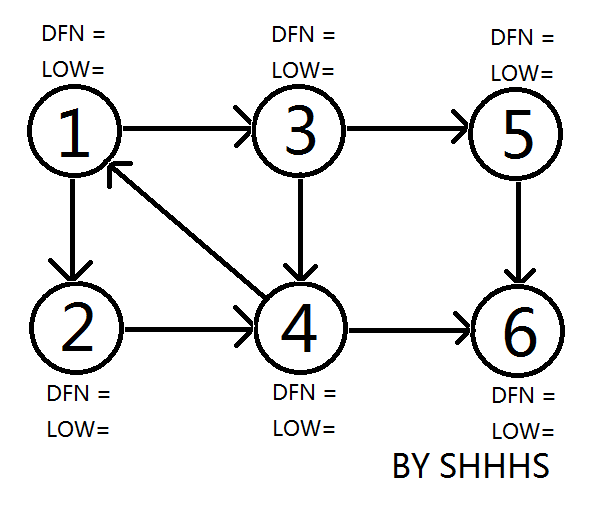
顺次DFS搜到节点6
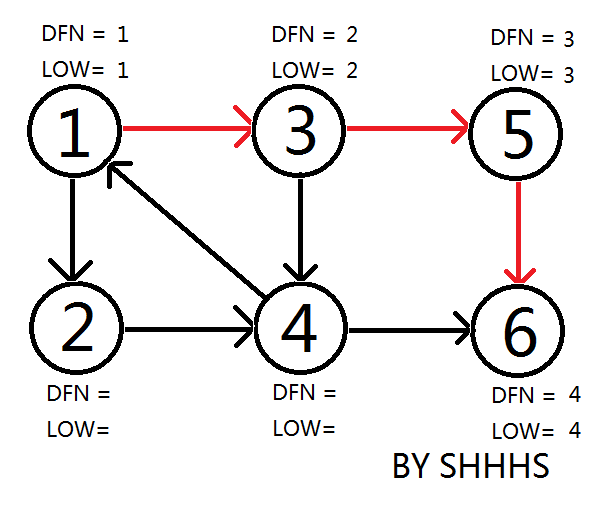
回溯时发现LOW[ 5 ]==DFN[ 5 ] , LOW[ 6 ]==DFN[ 6 ] ,则{ 5 } , { 6 } 为两个强连通分量。回溯至3节点,拓展节点4.
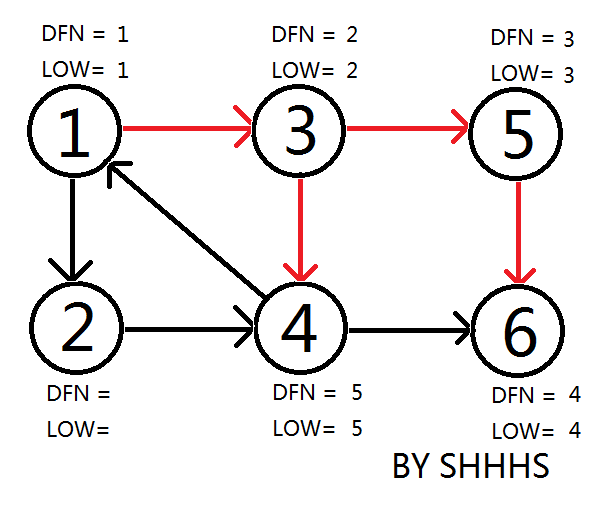
拓展节点1 , 发现1再栈中更新LOW[ 4 ],LOW[ 3 ] 的值为1
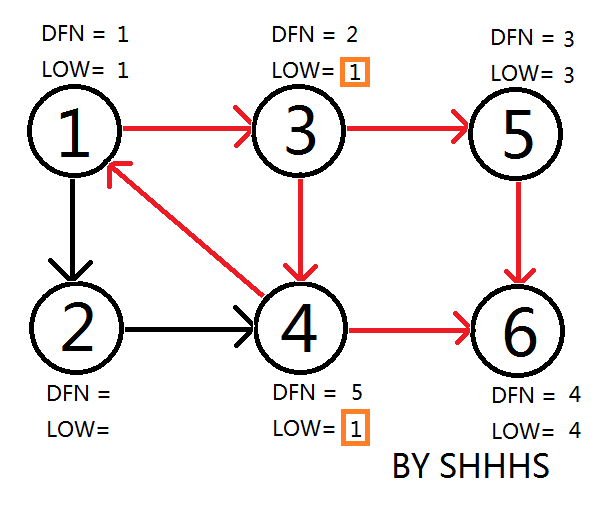
回溯节点1,拓展节点2
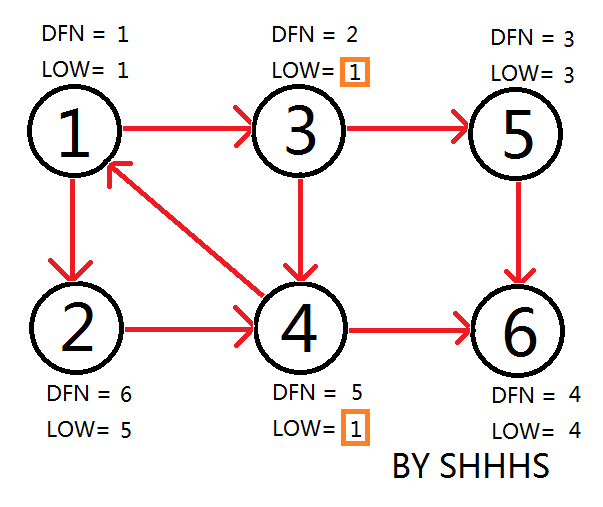
自此,Tarjan Algorithm 结束,{1 , 2 , 3 , 4 } , { 5 } , { 6 } 为图中的三个强连通分量。
不难发现,Tarjan Algorithm 的时间复杂度为O(E+V).
Code:
void tarjan(int x)
{
dfn[u] = low[u] = ++num;
st[++top] = u;
for(int i=fir[u];i;i=nex[i])
{
int v = to[i];
if(!dfn[i])
{
tarjan(v);
low[u] = min(low[u],low[v]);
}
else
if(! co[v])
low[u] = min(low[u],dfn[v]);
}
if(low[u] == dfn[u])
{
co[u] = ++col;
while(st[top] != u)
{
co[st[top]] = col;
top--;
}
top--;
}
}
Kosaraju与Tarjan(图的强连通分量)的更多相关文章
- Tarjan算法分解强连通分量(附详细参考文章)
Tarjan算法分解强连通分量 算法思路: 算法通过dfs遍历整个连通分量,并在遍历过程中给每个点打上两个记号:一个是时间戳,即首次访问到节点i的时刻,另一个是节点u的某一个祖先被访问的最早时刻. 时 ...
- Kosaraju算法解析: 求解图的强连通分量
Kosaraju算法解析: 求解图的强连通分量 欢迎探讨,如有错误敬请指正 如需转载,请注明出处 http://www.cnblogs.com/nullzx/ 1. 定义 连通分量:在无向图中,即为连 ...
- 求图的强连通分量--tarjan算法
一:tarjan算法详解 ◦思想: ◦ ◦做一遍DFS,用dfn[i]表示编号为i的节点在DFS过程中的访问序号(也可以叫做开始时间)用low[i]表示i节点DFS过程中i的下方节点所能到达的开始时间 ...
- 寻找图的强连通分量:tarjan算法简单理解
1.简介tarjan是一种使用深度优先遍历(DFS)来寻找有向图强连通分量的一种算法. 2.知识准备栈.有向图.强连通分量.DFS. 3.快速理解tarjan算法的运行机制提到DFS,能想到的是通过栈 ...
- 图的强连通分量-Kosaraju算法
输入一个有向图,计算每个节点所在强连通分量的编号,输出强连通分量的个数 #include<iostream> #include<cstring> #include<vec ...
- 20行代码实现,使用Tarjan算法求解强连通分量
今天是算法数据结构专题的第36篇文章,我们一起来继续聊聊强连通分量分解的算法. 在上一篇文章当中我们分享了强连通分量分解的一个经典算法Kosaraju算法,它的核心原理是通过将图翻转,以及两次递归来实 ...
- tarjan算法(强连通分量 + 强连通分量缩点 + 桥(割边) + 割点 + LCA)
这篇文章是从网络上总结各方经验 以及 自己找的一些例题的算法模板,主要是用于自己的日后的模板总结以后防失忆常看看的, 写的也是自己能看懂即可. tarjan算法的功能很强大, 可以用来求解强连通分量, ...
- Tarjan算法【强连通分量】
转自:byvoid:有向图强连通分量的Tarjan算法 Tarjan算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一棵子树.搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时可以判断 ...
- Tarjan在图论中的应用(一)——用Tarjan来实现强连通分量缩点
前言 \(Tarjan\)是一个著名的将强连通分量缩点的算法. 大致思路 它的大致思路就是在图上每个联通块中任意选一个点开始进行\(Tarjan\)操作(依据:强连通分量中的点可以两两到达,因此从任意 ...
随机推荐
- Confluence 6 数据中心的 SAML 单点登录最佳实践和故障排除
最佳实践 SAML 授权仅仅在有限的时间进行校验.你需要确定运行你的应用的计算机时间与 IdP 的时间是同步的. 如果你应用中的用户和用户组是通过用户目录进行配置的,你通常希望用户来源目录和你的 Id ...
- Confluence 6 复杂授权或性能问题
提交一个 服务器请求(support request) 然后在你的服务请求中同时提供下面的信息. Confluence 服务器 登录 Confluence 然后访问管理员控制台. 将 系统信息(Sys ...
- 好用的JS拖拽插件
下载artDialog插件的时候发现它把拖拽单独封装成了一个方法,挺好用的,使用方法如下... 第一种拖拽方式-点击容器指定区域进行拖拽 $('.ui-dialog').on(DragEvent.ty ...
- STL的注意事项
template是一个泛化的:使用template时开始仅仅是声明,具体的例如:k<int> a;叫做实例化显式实例化:类似k<int>a:明确指出哪种类型:隐式实例化:类似k ...
- Python继承、方法重写
继承 在编写类时,并不是每次都要从空白开始.当要编写的类和另一个已经存在的类之间存在一定的继承关系时,就可以通过继承来达到代码重用的目的,提高开发效率. class one(): "&quo ...
- 插件使用一树形插件---zTree
zTree是一款挺好用的树形插件,中文文档齐全,demo丰富. 官方网站是 http://www.treejs.cn/v3/main.php#_zTreeInfo 源码网站 https://githu ...
- hdfs数据到hbase过程
需求:将HDFS上的文件中的数据导入到hbase中 实现上面的需求也有两种办法,一种是自定义mr,一种是使用hbase提供好的import工具 一.hdfs中的数据是这样的 hbase创建好表 cre ...
- java 解析域名得到host
// 形如https://www.baidu.com 或 www.baidu.com, 判断这两种情况,并解析前者去掉http头,传入domain host // 方案1:正则表达式 + URI解析方 ...
- How to disable Microsoft Compatibility Telemetry
Issue: How to disable Microsoft Compatibility Telemetry (CompatTelRunner.exe)? Option : Disable Mi ...
- [转] React 中组件间通信的几种方式
在使用 React 的过程中,不可避免的需要组件间进行消息传递(通信),组件间通信大体有下面几种情况: 父组件向子组件通信 子组件向父组件通信 跨级组件之间通信 非嵌套组件间通信 下面依次说下这几种通 ...