SQL Server索引的执行计划
如何知道索引有问题,最直接的方法就是查看执行计划。通过执行计划,可以回答表上的索引是否被使用的问题。
(1)包含索引:避免书签查找
常见的索引方面的性能问题就是书签查找,书签查找分为RID查找和键值查找。
当非聚集索引被用于查找数据,但又不能覆盖查询时,就会引起书签查找。此时优化器会借助堆上的RID或者聚集索引上的聚集索引键来查找所需的额外数据,前者叫做RID,后者叫做键值查找。
书签查找就是为了找额外的列,如果数据量少并不是什么问题,但是当数据量很大,额外的列很多时,往往会带来额外的I/O开销,影响性能。
select sod.ProductID,sod.OrderQty,sod.UnitPrice
from Sales.SalesOrderDetail sod where sod.ProductID=897
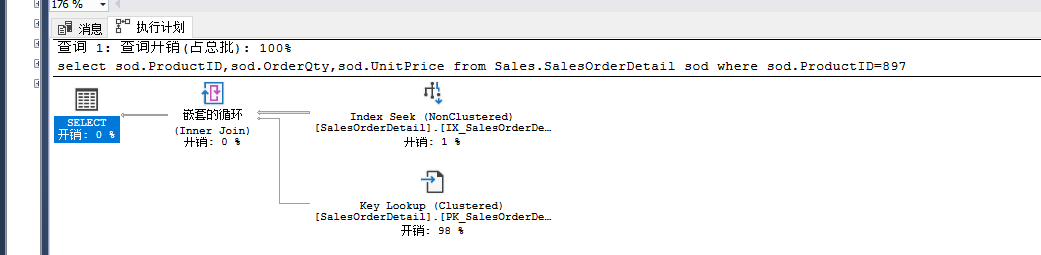
这个的性能根源----其实就是在键值查找上。对策,尽量使用查询在一个索引中完成,这一步可以通过覆盖索引和包含索引来实现。
if exists
(select * from sys.indexes where
object_id=OBJECT_ID(N'Sales.SalesOrderDetail')
and name=N'IX_SalesOrderDetail_ProductID')
drop index IX_SalesOrderDetail_ProductID on Sales.SalesOrderDetail with (online=off);
创建索引:
create nonclustered index IX_SalesOrderDetail_ProductID
on Sales.SalesOrderDetail(ProductID asc)
include (OrderQty,UnitPrice) with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off,
IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON)
ON [PRIMARY];
再次执行上述语句,执行计划如下:

逻辑读从1240下降到3次,是一个很大的提升,从实践来说,书签查找是常见的性能问题标志,当出现这个操作符,且百分比相对较高时,就必须分析是否有必要调整优化。
(2)索引选择度
对于每个索引,优化器都会自定创建统计信息来描述这个索引的数据分布情况。在后续的使用中,优化器会根据这些统计信息来决定查询是否使用这些索引。
通过以下语句可以查看统计信息:
dbcc show_Statistics('Sales.SalesOrderDetail','IX_SalesOrderDetail_ProductID')
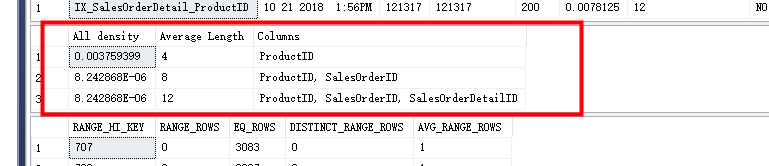
这个索引上的ProductID的密度为0.0037593999,是非常低的值也就是选择度很高,最优可能被使用,而其他两行是聚集索引的列,由于非聚集索引的叶子节点会指向聚集索引键,这里的统计信息会包含这两列,并同时给出对应的密度。如果表上没有聚集索引,那么非聚集索引会指向数据本身。如果选择度很低,优化器会放弃索引。
select sod.OrderQty,sod.SalesOrderID,
sod.SalesOrderDetailID,sod.LineTotal from Sales.SalesOrderDetail sod where sod.OrderQty=10;

优化器使用了聚集索引扫描来实现WHERE条件的筛选操作。对这个列加上索引。
create nonclustered Index IX_SalesOrderDetail_OrderQty
on Sales.SalesOrderDetail(orderQty asc)
with (PAD_Index=off,STATISTICS_NORECOMPUTE=off,SORT_IN_TEMPDB=off,
IGNORE_DUP_KEY=off,DROP_EXISTING=off,ONLINE=off,ALLOW_ROW_LOCKS=on,ALLOW_PAGE_LOCKS=ON)
on [Primary]
查看统计信息:
dbcc SHOW_STATISTICS('Sales.SalesOrderDetail','IX_SalesOrderDetail_OrderQty')
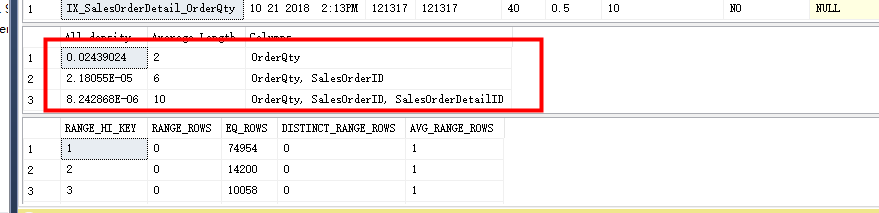
这个选择度不高,如果再次执行查询语句,可以看到执行计划中依旧会使用原有计划。

如果选择度不高,优化器依旧会放弃上面的索引。
删除新建的索引:
drop index Sales.SalesOrderDetail.IX_SalesOrderDetail_OrderQty
(3)统计信息和索引
优化器会对每个索引创建统计信息,如果统计信息过时,优化器同样可能不选择“有用索引”。
if EXISTS (select * from sys.objects where object_id=OBJECT_ID('N[NewOrders]') and type in (N'U'))
drop table[NewOrders]
go
select * into NewOrders from Sales.SalesOrderDetail
go
create index IX_NewOrders_ProductID on NewOrders(ProductID)
使用一个简答的查询生成预估执行计划,接着在事物中更新数据,影响ProductID列上的数据分布,让其选择度变低。最后获取实际执行计划。
set showplan_xml on
go
select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897
go
set showplan_xml off
预估执行计划:
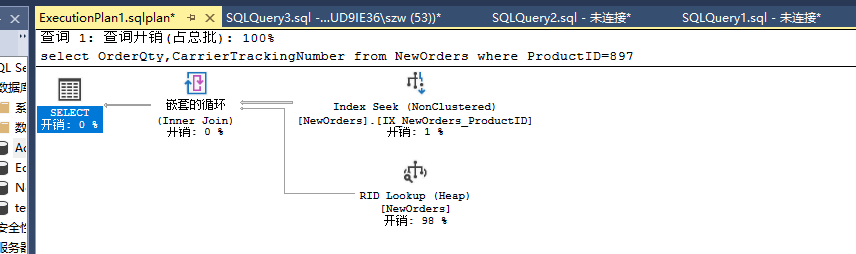
begin tran
update NewOrders
set ProductID=897
where ProductID between 800 and 900 --实际的执行计划
set statistics xml on
go
select OrderQty,CarrierTrackingNumber from NewOrders where ProductID=897
rollback tran
go
set statistics xml off
实际执行计划:
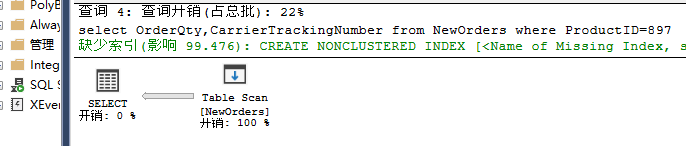
由于统计信息得变更,优化器对同一个查询选择不同的执行计划。更新操作使得列上的数据分布发生改变,选择度降低,优化器会“觉得”使用扫描操作时开销更低。因此,确保统计信息得实时性及有效性对性能的提升非常重要。
SQL Server索引的执行计划的更多相关文章
- 谈一谈SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- 浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询 ...
- 谈一谈SQL Server中的执行计划缓存(下)
简介 在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突.本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法. 将执行缓存考虑在内时的流程 上篇文章中提到了查询优 ...
- SQL Server如何固定执行计划
SQL Server 其实从SQL Server 2005开始,也提供了类似ORACLE中固定执行计划的功能,只是好像很少人使用这个功能.当然在SQL Server中不叫"固定执行计划&qu ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- 转: SQL Server索引的维护 - 索引碎片、填充因子
转:http://www.cnblogs.com/kissdodog/archive/2013/06/14/3135412.html 实际上,索引的维护主要包括以下两个方面: 页拆分 碎片 这两个问题 ...
- SQL Server 索引的自动维护 <第十三篇>
在有大量事务的数据库中,表和索引随着时间的推移而碎片化.因此,为了增进性能,应该定期检查表和索引的碎片,并对具有大量碎片的进行整理. 1.确定当前数据库中所有需要分析碎片的表. 2.确定所有表和索引的 ...
随机推荐
- Deep Learning Tutorial - Classifying MNIST digits using Logistic Regression
Deep Learning Tutorial 由 Montreal大学的LISA实验室所作,基于Theano的深度学习材料.Theano是一个python库,使得写深度模型更容易些,也可以在GPU上训 ...
- 最长增长子序列(LIS)
给定一个无序的整数数组,找到其中最长上升子序列的长度. 示例: 输入: [10,9,2,5,3,7,101,18] 输出: 4 解释: 最长的上升子序列是 [2,3,7,101],它的长度是 4. 说 ...
- fabric.js PatternBrush
// Original canvas const canvas = new fabric.Canvas('canvas'); fabric.Image.fromURL('https://picsum. ...
- Git学习笔记07-删除文件
在Git中,删除也是一种修改.先新建一个文件,添加并提交.然后删除下看看. 一般删除直接从工作区把文件删了,或者使用rm命令 这是使用git status查看状态,会告诉我们删了哪个文件 这个 ...
- 使用cstdiofile在vs2010中无法写入中文的问题
在VC2010环境下, 以下代码无法实现使用CStdioFile向文本文件中写入中文(用notepad.exe查看不到写入的中文) CStdioFile file; file.Open(…); fil ...
- ObjectArx2013新建工程出错的解决办法
最近将一个ObjectArx升级到Arx2013版,使用ObjectArx2013向导时,新建项目时弹出错误"未能加载项目文件.给定编码中的字符无效.第1行,位置1",经网上查找发 ...
- boost 文件系统
第 9 章 文件系统 目录 9.1 概述 9.2 路径 9.3 文件与目录 9.4 文件流 9.5 练习 该书采用 Creative Commons License 授权 9.1. 概述 库 Boo ...
- 第三章 Models详解
摘自:http://www.cnblogs.com/xdotnet/archive/2012/03/07/aspnet_mvc40_validate.html Model的概念 万丈高楼平地起,先理解 ...
- vue2.x + vux采坑总结(一)
1.<tab-bar> 切换时,iocn高亮跟着切换问题 vux的Tabbar组件是用来实现底部tab栏,详情见官网文档 , 实现实例截图: 代码如下,控制高亮的是代码凸显部分:selec ...
- ansible笔记(9):常用模块之包管理模块
ansible笔记():常用模块之包管理模块 yum_repository模块 yum_repository模块可以帮助我们管理远程主机上的yum仓库. 此处我们介绍一些yum_repository模 ...