Sampling Matrix
这些天看了一些关于采样矩阵(大概是这么翻译的)的论文,简单做个总结。
- FAST MONTE CARLO ALGORITHMS FOR MATRICES I: APPROXIMATING MATRIX MULTIPLICATION
算法如下:
目的是为了毕竟矩阵的乘积AB, 以CR来替代。
其中右上角带有i_t的A表示A的第i_t列,右下角带有i_t的B表示B的第i_t行。
关于 c 的选择,以及误差的估计,请回看论文。
下面是一个小小的测试:
代码:
import numpy as np
def Generate_P(A, B): #生成概率P
try:
n1 = len(A[1,:])
n2 = len(B[:,1])
if n1 == n2:
n = n1
else:
print('Bad matrices')
return 0
except:
print('The matrices are not fit...')
A_New = np.square(A)
B_New = np.square(B)
P_A = np.array([np.sqrt(np.sum(A_New[:,i])) for i in range(n)])
P_B = np.array([np.sqrt(np.sum(B_New[i,:])) for i in range(n)])
P = P_A * P_B / (np.sum(P_A * P_B))
return P
def Generate_S(n, c, P): #生成采样矩阵S 简化了一下算法
S = np.zeros((n, c))
T = np.random.choice(np.array([i for i in range(n)]), size = c, replace = True, p = P)
for i in range(c):
S[T[i], i] = 1 / np.sqrt(c * P[T[i]])
return S
def Summary(times, n, c, P, A_F, B_F, AB): #总结和分析
print('{0:^15} {1:^15} {2:^15} {3:^15} {4:^15} {5:^15} {6:^15}'.format('A_F', 'B_F', 'NEW_F', 'A_F * B_F', 'AB_F', 'RATIO', 'RATIO2'))
print('{0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15}'.format(''))
A_F_B_F = A_F * B_F
AB_F = np.sqrt(np.sum(np.square(AB)))
Max = -1
Min = 99999999999
Max2 = -1
Min2 = 99999999999
Max_NEW_F = 0
Min_NEW_F = 0
Mean_NEW_F = 0
Mean_ratio = 0
Mean_ratio2 = 0
for i in range(times):
S = Generate_S(n, c, P)
CR = np.dot(A.dot(S), (S.T).dot(B))
NEW = AB - CR
NEW_F = np.sqrt(np.sum(np.square(NEW)))
ratio = NEW_F / A_F_B_F
ratio2 = NEW_F / AB_F
Mean_NEW_F += NEW_F
Mean_ratio += ratio
Mean_ratio2 += ratio2
if ratio > Max:
Max = ratio
Max2 = ratio2
Max_NEW_F = NEW_F
if ratio < Min:
Min = ratio
Min2 = ratio2
Min_NEW_F = NEW_F
print('{0:^15.5f} {1:^15.5f} {2:^15.5f} {3:^15.5f} {4:^15.5f} {5:^15.3%} {6:^15.3%}'.format(A_F, B_F, NEW_F, A_F_B_F, AB_F, ratio, ratio2))
Mean_NEW_F = Mean_NEW_F / times
Mean_ratio = Mean_ratio / times
Mean_ratio2 = Mean_ratio2 / times
print('{0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15}'.format(''))
print('{0:^15.5f} {1:^15.5f} {2:^15.5f} {3:^15.5f} {4:^15.5f} {5:^15.3%} {6:^15.3%}'.format(A_F, B_F, Mean_NEW_F, A_F_B_F, AB_F, Mean_ratio, Mean_ratio2))
print('{0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15} {0:-<15}'.format(''))
print('Count: {0} times'.format(times))
print('Max_ratio: {0:<15.3%} Min_ratio: {1:<15.3%}'.format(Max, Min))
print('Max_ratio2: {0:<15.3%} Min_ratio2: {1:<15.3%}'.format(Max2, Min2))
print('Max_NEW_F: {0:<15.5f} Min_NEW_F: {1:<15.5f}'.format(Max_NEW_F, Min_NEW_F))
#下面是关于矩阵行列的一些参数,我是采用均匀分布产生的矩阵
m = 47
n = 120
p = 55
A = np.array([[np.random.rand() * 100 for j in range(n)] for i in range(m)])
B = np.array([[np.random.rand() * 100 for j in range(p)] for i in range(n)])
#构建c的一些参数 这个得参考论文
Thelta = 1/4
Belta = 1
Yita = 1 + np.sqrt((8/Belta * np.log(1/Thelta)))
e = 1/5
c = int(1 / (Belta * e ** 2)) + 1
P = Generate_P(A, B)
#结果分析
AB = A.dot(B)
A_F = np.sqrt(np.sum(np.square(A)))
B_F = np.sqrt(np.sum(np.square(B)))
times = 1000
Summary(times, n, c, P, A_F, B_F, AB)
粗略的结果:
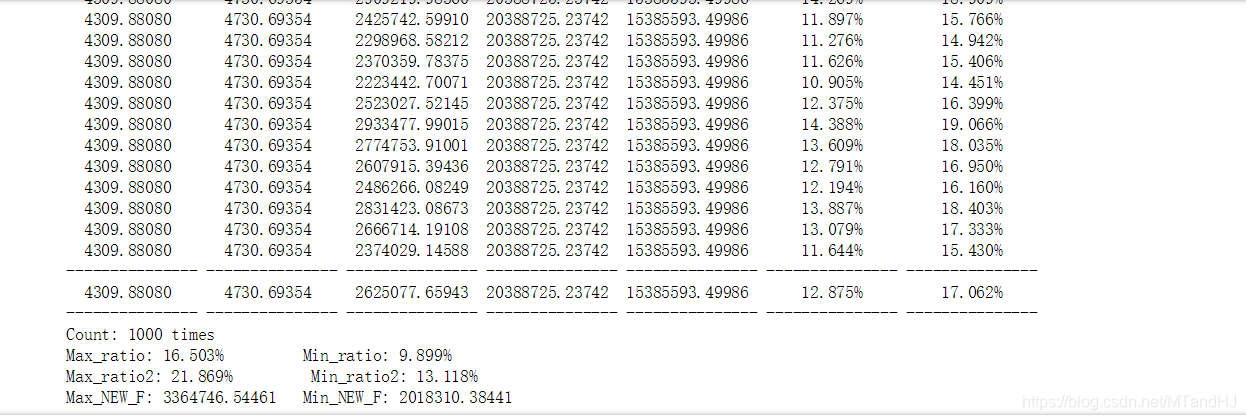
用了原矩阵的一半的维度,代价是约17%的误差。
用正态分布生成矩阵的时候,发现,如果是标准正态分布,效果很差,我猜是由计算机舍入误差引起的,这样的采样的性能不好。当均值增加的时候,和”均匀分布“差不多,甚至更优(F范数的意义上)。
补充:









Sampling Matrix的更多相关文章
- 【NLP】Conditional Language Modeling with Attention
Review: Conditional LMs Note that, in the Encoder part, we reverse the input to the ‘RNN’ and it per ...
- Sampling Distributions and Central Limit Theorem in R(转)
The Central Limit Theorem (CLT), and the concept of the sampling distribution, are critical for unde ...
- [LeetCode] Random Flip Matrix 随机翻转矩阵
You are given the number of rows n_rows and number of columns n_cols of a 2D binary matrix where all ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 470. Implement Rand10() Using Rand7() (拒绝采样Reject Sampling)
1. 问题 已提供一个Rand7()的API可以随机生成1到7的数字,使用Rand7实现Rand10,Rand10可以随机生成1到10的数字. 2. 思路 简单说: (1)通过(Rand N - 1) ...
- [Python] 01 - Number and Matrix
故事背景 一.大纲 如下,chapter4 是个概览,之后才是具体讲解. 二. 编译过程 Ref: http://www.dsf.unica.it/~fiore/LearningPython.pdf
- 目录:Matrix Differential Calculus with Applications in Statistics and Econometrics,3rd_[Magnus2019]
目录:Matrix Differential Calculus with Applications in Statistics and Econometrics,3rd_[Magnus2019] Ti ...
- 【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy Authors: Jiawei Chen, Can Wang, ...
- angular2系列教程(十一)路由嵌套、路由生命周期、matrix URL notation
今天我们要讲的是ng2的路由的第二部分,包括路由嵌套.路由生命周期等知识点. 例子 例子仍然是上节课的例子:
随机推荐
- sqlserver——cube:多维数据集
1.cube:生成多维数据集,包含各维度可能组合的交叉表格,使用with 关键字连接 with cube 根据需要使用union all 拼接 判断 某一列的null值来自源数据还是 cube 使用G ...
- 如何实现javascript js 类命名空间的写法
转载 猫猫小屋http://www.maomao365.com/?p=823 在C#中有namespace概念,java中有package的概念,有了这些概念之后,在系统的运行时,每一个方法就会拥有唯 ...
- CentOS6.5内 MySQL5.7.19编译安装
作为博主这样的Linux菜鸟,CentOS下最喜欢的就是yum安装.但有时候因为特殊情况(例如被墙等),某些软件可能没办法直接通过yum来安装,这时候我们可以使用编译安装或者直接二进制文件安装. 本博 ...
- [Hive_add_4] Hive 命令行客户端 Beeline 的使用
0. 说明 Hive 命令行客户端 beeline 的使用,建立在启动 Hadoop 集群和启动 hiveserver2 的基础之上 1. 使用指南 在确保集群启动和 hiveserver2 启动的 ...
- 谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用.本文将讲述进一步扩展其应用场景:首先是User- ...
- android开发——用户头像
最近,小灵狐得知了一种能够加快修炼速度的绝世秘法,那便是修炼android神功.小灵狐打算用android神功做一个app,今天他的修炼内容就是头像功能.可是小灵狐是个android小白啊,所以修炼过 ...
- 【存储】RAID磁盘阵列选择
RAID磁盘阵列(Redundant Arrays of Inexpensive Disks) 一个基本思想:将多个容量较小.相对廉价的磁盘进行有机组合,从而以较低的成本获得与昂贵大容量磁盘相当的容量 ...
- TCP Health Checks
This chapter describes how to configure health checks for TCP. Introduction NGINX and NGINX Plus can ...
- 【APIO2018】铁人两项
[APIO2018]铁人两项 题目描述 大意就是给定一张无向图,询问三元组\((s,c,f)\)中满足\(s\neq c\neq f\)且存在\((s\to c\to f)\)的简单路径(每个点最多经 ...
- django ORM的总结
1.django分表的方案: https://mp.weixin.qq.com/s?__biz=MjM5NjA3Nzk3Ng==&mid=2648154502&idx=1& ...