Hadoop 倒排索引
倒排索引是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
一、实例描述
倒排索引简单地就是,根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他的一些策略(如页面点击投票率)等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。
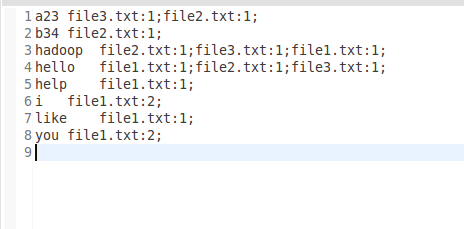
样例输入:

样例输出:
二、设计思路
倒排索引涉及几个过程:Map过程,Combine过程,Reduce过程。
Map过程:
当你把需要处理的文档上传到hdfs时,首先默认的TextInputFormat类对输入的文件进行处理,得到文件中每一行的偏移量和这一行内容的键值对<偏移量,内容>做为map的输入。在改写map函数的时候,我们就需要考虑,怎么设计key和value的值来适合MapReduce框架,从而得到正确的结果。由于我们要得到单词,所属的文档URL,词频,而<key,value>只有两个值,那么就必须得合并其中得两个信息了。这里我们设计key=单词+URL,value=词频。即map得输出为<单词+URL,词频>,之所以将单词+URL做为key,时利用MapReduce框架自带得Map端进行排序。
Combine过程:
Combine过程将key值相同得value值累加,得到一个单词在文档上得词频。但是为了把相同得key交给同一个reduce处理,我们需要设计为key=单词,value=URL+词频。
Reduce过程:
Reduce过程其实就是一个合并的过程了,只需将相同的key值的value值合并成倒排索引需要的格式即可。
三、程序代码
程序代码如下:
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class InvertedIndex { public static class Map extends Mapper<LongWritable, Text, Text, Text>{
private static Text word = new Text();
private static Text one = new Text(); @Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
String fileName = ((FileSplit)context.getInputSplit()).getPath().getName();
StringTokenizer st = new StringTokenizer(value.toString());
while (st.hasMoreTokens()) {
word.set(st.nextToken()+"\t"+fileName);
context.write(word, one);
}
}
} public static class Combine extends Reducer<Text, Text, Text, Text>{
private static Text word = new Text();
private static Text index = new Text(); @Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
String[] splits = key.toString().split("\t");
if (splits.length != 2) {
return ;
}
long count = 0;
for(Text v:values){
count++;
}
word.set(splits[0]);
index.set(splits[1]+":"+count);
context.write(word, index);
}
} public static class Reduce extends Reducer<Text, Text, Text, Text>{
private static StringBuilder sub = new StringBuilder(256);
private static Text index = new Text(); @Override
protected void reduce(Text word, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
for(Text v:values){
sub.append(v.toString()).append(";");
}
index.set(sub.toString());
context.write(word, index);
sub.delete(0, sub.length());
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"Invert Index ");
job.setJarByClass(InvertedIndex.class); job.setMapperClass(Map.class);
job.setCombinerClass(Combine.class);
job.setReducerClass(Reduce.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
} }
Hadoop 倒排索引的更多相关文章
- hadoop倒排索引
1.前言 学习hadoop的童鞋,倒排索引这个算法还是挺重要的.这是以后展开工作的基础.首先,我们来认识下什么是倒拍索引: 倒排索引简单地就是:根据单词,返回它在哪个文件中出现过,而且频率是多少的结果 ...
- Hadoop之倒排索引
前言: 从IT跨度到DT,如今的数据每天都在海量的增长.面对如此巨大的数据,如何能让搜索引擎更好的工作呢?本文作为Hadoop系列的第二篇,将介绍分布式情况下搜索引擎的基础实现,即“倒排索引”. 1. ...
- hadoop学习笔记之倒排索引
开发工具:eclipse 目标:对下面文档phone_numbers进行倒排索引: 13599999999 1008613899999999 12013944444444 13800138000137 ...
- hadoop实现倒排索引
hadoop实现倒排索引 本文用hadoop实现倒排索引算法,用基本的分两步完成,不使用combine 第一步 读入文档,统计文档中各个单词的个数,与word count类似,但这里把word-fil ...
- Hadoop学习笔记(8) ——实战 做个倒排索引
Hadoop学习笔记(8) ——实战 做个倒排索引 倒排索引是文档检索系统中最常用数据结构.根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index).结构如 ...
- Hadoop案例(四)倒排索引(多job串联)与全局计数器
一. 倒排索引(多job串联) 1. 需求分析 有大量的文本(文档.网页),需要建立搜索索引 xyg pingping xyg ss xyg ss a.txt xyg pingping xyg pin ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- Hadoop实战-MapReduce之倒排索引(八)
倒排索引 (就是key和Value对调的显示结果) 一.需求:下面是用户播放音乐记录,统计歌曲被哪些用户播放过 tom LittleApple jack YesterdayO ...
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
随机推荐
- Spring Boot SSL
转载 https://howtodoinjava.com/spring-boot/spring-boot-ssl-https-example/ Spring Boot SSL 学习如何将Web应用程 ...
- linux回顾
linux内容回顾: centos6.9 ubuntu12 麒麟linux suse(德国linux) depin xshell(连接工具) vmware workstation(个人学习) ...
- python基础之Day23
1.封装 什么是? 封:明确地把属性隐藏起来 ,对外隐藏,对内开放 申请名称空间,往里面装入一系列名字 /属性(类比 类 和对象 只是装的概念) 为什么要用? __init__往对象里丢属性 封装 ...
- QTcpSocket 相关知识总结
1. 连接服务器 m_tcpSocket->connectToHost("127.0.0.1", 9877); connected = m_tcpSocket->wa ...
- 调用Excel宏批量处理文件
'1.用户可以任意选择文件夹进行遍历 '2.限定遍历时仅搜索EXCEL文件(你可以改变文件类型) '这个程序要先在“引用”下选择"microsoft scripting runtime&qu ...
- C# 互通操作 (一)
回顾一下自己学习的内容然后从互通的基础案例开始写起. 这次实现一个很简单的互通demo,就是 在unity里 在c#里调用windows窗体的MessageBox 消息提示 public class ...
- s3c2440 nandflash 初始化
1.什么是 nandflash ? FLASH闪存 闪存的英文名称是"Flash Memory",一般简称为"Flash",它属于内存器件的一种,是一种非易失性 ...
- MongoDB学习记录(三) - MongoDB的"增查改删"操作之"查"
查找使用的方法: db.collection.find() 查找所有文档 db.collection.find({})或者db.collection.find({}) 指定键值对 db.collect ...
- 关于python,完善我计算机知识的一步。
因为身为理科男,所以特别喜欢涉及其他领域的知识.而对我来说,计算机是很有诱惑力的--尤其是程序语言设计,懂得一门“外语”是多么的重要.大一时候接触过包括有计算机的基本知识,c语言,这个新的学期也开始接 ...
- 1111. Online Map (30)
Input our current position and a destination, an online map can recommend several paths. Now your jo ...