课程回顾-Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
划分的量
要保证数据来自一个分布
偏差方差分析
如果存在high bias
如果存在high variance
正则化
正则化减少过拟合的intuition
Dropout
dropout分析
其它正则化方法
数据增加(data augmentation)
early stopping
ensemble
归一化输入
归一化可以加速训练
归一化的步骤
归一化应该应用于:训练、验证、测试
梯度消失/爆炸
权重初始化
通过数值近似计算梯度
优化算法
mini-batch
momentum
RMSprop
Adam
调参
顺序
批规范化Batch Normalization
Reference
训练、验证、测试
划分的量
- If size of the dataset is 100 to 1000000 ==> 60/20/20
- If size of the dataset is 1000000 to INF ==> 98/1/1 or 99.5/0.25/0.25
要保证数据来自一个分布
偏差方差分析
如果存在high bias
- 尝试用更大的网络
- 尝试换一个网络模型
- 跑更长的时间
- 换不同的优化算法
如果存在high variance
- 收集更多的数据
- 尝试正则化方法
- 尝试一个不同的模型
如果存在high bias
- 尝试用更大的网络
- 尝试换一个网络模型
- 跑更长的时间
- 换不同的优化算法
如果存在high variance
- 收集更多的数据
- 尝试正则化方法
- 尝试一个不同的模型
一般来说更大的网络更好
正则化
正则化减少过拟合的intuition
太大会导致其为0
Dropout
- 原始的dropout
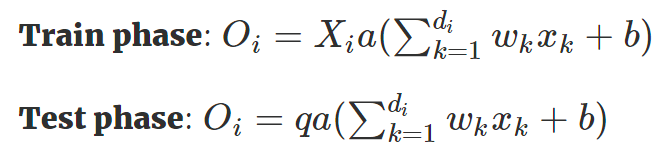
- Inverted Dropout
我们稍微将 Dropout 方法改进一下,使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。这个改进的 Dropout 方法就被称之为 Inverted Dropout 。比例因子将修改为是保留概率的倒数,即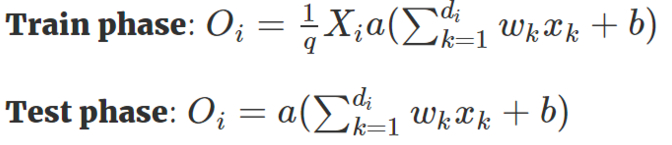
dropout分析
- 因为我们不能够过分依赖一个特征,dropout可以一定程度将权重分出去
- 我们可以在不同的层设置不同的dropout
- 输入层的dropout应该接近1,因为我们需要从中学习信息
- CNN中dropout广泛应用
- dropout带来的问题是调试困难,通常我们需要关掉dropout调试,确认无误再继续用dropout
其它正则化方法
数据增加(data augmentation)
我们稍微将 Dropout 方法改进一下,使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。这个改进的 Dropout 方法就被称之为 Inverted Dropout 。比例因子将修改为是保留概率的倒数,即
数据增加(data augmentation)
就是通过一些变换得到新的图片(这种其实是在图像领域最为广泛应用,但是思想可以推广)
early stopping
就是在迭代中选择验证错误不再降低的点
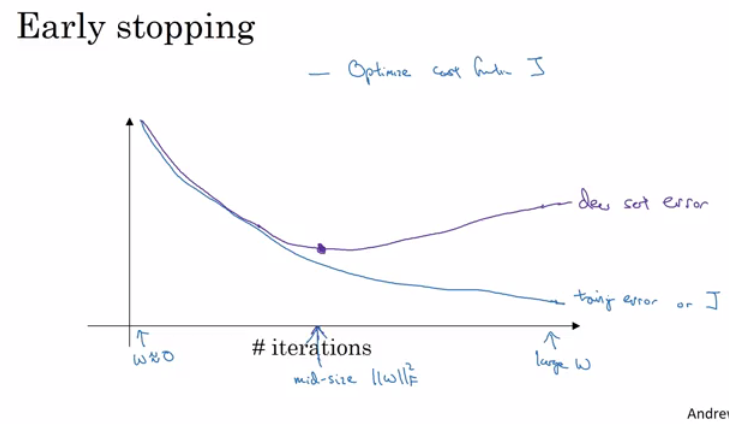
好处是不用调超参,坏处是it makes us think about something else more than optimize W's and b's.
ensemble
训练多个模型,组合
可以带来2%左右的提升,减少泛化误差
归一化输入
归一化可以加速训练
归一化的步骤
- 计算均值
- 所有数据减去均值
- 计算方差
x/=variance
归一化应该应用于:训练、验证、测试
梯度消失/爆炸
x/=variance这是训练深度学习难的一个点
权重初始化
是解决梯度消失/爆炸的一个部分的解决方案
对于sigmoid和tanh
np.random.rand(shape)*np.sqrt(1/n[l-1]) 对于relu
np.random.rand(shape)*np.sqrt(2/n[l-1]) #n[l-1] In the multiple layers.一个方差是1/Nx" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">1/Nx,另一个是2/Nx" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">2/Nx
通过数值近似计算梯度
- 注意添加正则项的损失函数
优化算法
mini-batch
- 为了利用向量化,batch大小应该是2的指数
- 注意CPU/GPU内存大小
momentum
mini-batch
- 为了利用向量化,batch大小应该是2的指数
- 注意CPU/GPU内存大小
momentum
计算权重的指数加权平均
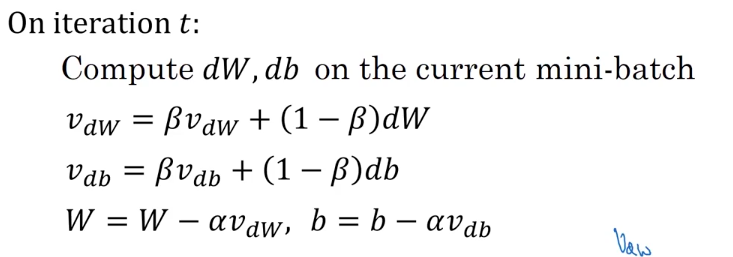
RMSprop
Root mean square prop

使用这个算法可以选择较大的学习率
Adam
Adaptive Momentum Estimation。其实就是把rmsprop和momentem放一起了,另加了一个纠正
其中推荐β1=0.9" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">β1=0.9, β2=0.999" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">β2=0.999, ϵ=10−8" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">ϵ=10−8
深度神经网络中的主要问题不是局部最小点,因为在高维空间中出现局部最优的可能性很小,但是很容易出现鞍点,鞍点会导致训练很慢,所以上面的几个方法会很有用
调参
顺序
Learning rate.
Mini-batch size.
No. of hidden units.
Momentum beta.
No. of layers.
Use learning rate decay?
Adam beta1 & beta2
regularization lambda
Activation functions
批规范化Batch Normalization
可以加速训练
和前面的对于输入数据的处理不一样,这里考虑的是对于隐层,我们能否对A[l]进行操作,使得训练加快。

这里γ" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">γ和β" role="presentation" style="font-size: 100%; display: inline-block; position: relative;">β是参数
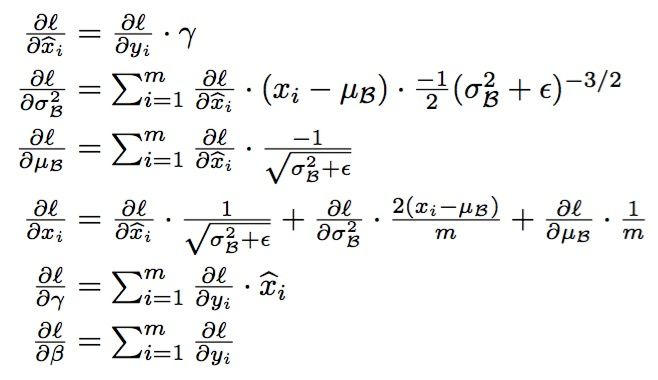
解决了梯度弥散的问题
批规范化其实做了一点正则化的工作,如果你希望减弱这种效果可以增大批大小。
测试用需要估计均值和方差
Reference
https://github.com/mbadry1/DeepLearning.ai-Summary
课程回顾-Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization的更多相关文章
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第三周(Hyperparameter tuning, Batch Normalization and Programming Frameworks) —— 2.Programming assignments
Tensorflow Welcome to the Tensorflow Tutorial! In this notebook you will learn all the basics of Ten ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第一周(Practical aspects of Deep Learning) —— 4.Programming assignments:Gradient Checking
Gradient Checking Welcome to this week's third programming assignment! You will be implementing grad ...
- 《Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization》课堂笔记
Lesson 2 Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization 这篇文章其 ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Initialization)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Initialization Welcome to the first assignment of "Improving D ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Assignment(Optimization Methods)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. 请不要ctrl+c/ctrl+v作业. Optimization Methods Until now, you've always u ...
- Coursera, Deep Learning 2, Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Course
Train/Dev/Test set Bias/Variance Regularization 有下面一些regularization的方法. L2 regularation drop out da ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Gradient Checking)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Gradient Checking Welcome to the final assignment for this week! In ...
随机推荐
- spring jar包解读(转)
作者:http://www.cnblogs.com/leehongee/archive/2012/10/01/2709541.html spring.jar 是包含有完整发布模块的单个jar 包.但是 ...
- angular4.0懒加载
用angular4.0进行前后端分离已经好几个月了,现在接近了尾声,pc端和移动端.可是却还存在着很多问题,最近这几天一直在研究懒加载问题,因为通过ng build --prod打包后主文件很大,有2 ...
- vue中created、mounted、 computed,watch,method 等方法整理
created:html加载完成之前,执行.执行顺序:父组件-子组件 mounted:html加载完成后执行.执行顺序:子组件-父组件 methods:事件方法执行 watch:watch是去监听一个 ...
- JS中的同步和异步
javascript语言是一门“单线程”的语言,不像java语言,类继承Thread再来个thread.start就可以开辟一个线程,所以,javascript就像一条流水线,仅仅是一条流水线而已,要 ...
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- 关于PHP读取HTTP头的部分
本文转载自https://my.oschina.net/luoczi/blog/86608 1.关于PHP读取HTTP头的方法 $_SERVER['PHP_SELF'] #当前正在执行脚本的文件名,与 ...
- Fiddler-设置取消自动更新
fiddler 启动时老弹出要更新,但不想更新,可以这样设置 Tools-Optons->General 把第一个√去掉
- 深入浅出Git教程【转载】转载
深入浅出Git教程(转载) 目录 一.版本控制概要 1.1.什么是版本控制 1.2.常用术语 1.3.常见的版本控制器 1.4.版本控制分类 1.4.1.本地版本控制 1.4.2.集中版本控制 1 ...
- 转发对python装饰器的理解
[Python] 对 Python 装饰器的理解的一些心得分享出来给大家参考 原文 http://blog.csdn.net/sxw3718401/article/details/3951958 ...
- Mac 下 python 环境问题
一.Mac下,可能存在的 python 环境: 1.Mac系统自带的python环境在(由于不同的 mac 系统,默认自带的 python 版本可能不一样): Python 2.7.10: /Syst ...