003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途。
本程序仍有很多不足之处,请读者不吝赐教。
依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装。下面是代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import sys
reload(sys)
sys.setdefaultencoding('utf-8') #解决编码问题 """一个简单的从豆瓣网获取电影标签的示例,
1. 首先获取所有标签以及它所对应的请求连接,
获取所有标签的请求链接是https://movie.douban.com/tag/?view=cloud
2. 请求每个标签对应的链接获取该标签下所有电影信息
""" import urllib
import urllib2
import re
import codecs
# BeautifulSoup 用于解析html使用,本程序中使用lxml作为解析器
from bs4 import BeautifulSoup # url正则表达式,用于将url分割为多个部分,对其中某些部分进行url编码使用
URL_RGX = re.compile(r'(?P<prefix>https?://)(?P<mid>[^?]+)(?P<has_key>\??)(?P<parms>[^?]*)')
DOUBAN_TAG_URL = r'https://movie.douban.com/tag/?view=cloud' # url请求
def get_request(url):
# 对url特定部分进行编码
matches = URL_RGX.match(url)
if matches:
dic = matches.groupdict()
prefix = dic.get('prefix', '')
mid = urllib.quote(dic.get('mid', ''))
has_key = dic.get('has_key', '')
parms = dic.get('parms', '')
if parms != '':
tmp_dic = dict()
for kv in parms.split('&'):
k, v = kv, ''
if '=' in kv:
k, v = kv.split('=', 1)
tmp_dic[k] = v
parms = urllib.urlencode(tmp_dic)
url = '{0}{1}{2}{3}'.format(prefix, mid, has_key, parms)
else:
url = None
if url:
try:
res = urllib.urlopen(url)
if res and res.getcode() == 200:
return res.read()
except Exception as e:
pass
return '' # 获取所有标签信息,返回值为列表,列表中每个元素格式为(标签名, 标签url地址)
def get_all_tags():
all_tags = list()
page_text = get_request(DOUBAN_TAG_URL)
soup = BeautifulSoup(page_text, 'lxml')
tags = soup.find_all('a', attrs={'class': 'tag'})
for tag in tags:
tag_name = tag.string
# 将原有链接中的?focus=替换为空,替换后url为分页显示地址
tag_url = tag['href'].replace('?focus=', '')
all_tags.append((tag_name, tag_url))
return all_tags # 解析单个电影节点信息,返回电影信息字典
def parse_movie_tag(movie_tag):
# 下面15行代码好烂,下次改下它
movie_title_tag = movie_tag.find('a', attrs={'class': 'title'})
movie_title = '无名电影'
movie_detail_url = '无链接'
if movie_title_tag:
movie_title = movie_title_tag.string.strip()
movie_detail_url = movie_title_tag['href'].strip()
# movie_detail_url = movie_tag.find('a', attrs={'class': 'title'})['href']
movie_desc_tag = movie_tag.find('div', attrs={'class': 'desc'})
movie_desc = '无描述信息'
if movie_desc_tag:
movie_desc = movie_desc_tag.string.strip()
movie_rating_nums_tag = movie_tag.find('span', attrs={'class': 'rating_nums'})
movie_rating_nums = '无评分信息'
if movie_rating_nums_tag:
movie_rating_nums = movie_rating_nums_tag.string.strip()
return {'title': movie_title, 'detail_url': movie_detail_url,
'desc': movie_desc, 'rating_nums': movie_rating_nums} # 获取当前页面中的电影信息节点
def get_current_page_movies(page_url):
page_text = get_request(page_url)
soup = BeautifulSoup(page_text, 'lxml')
movies = soup.find_all('dd')
movie_info_lst = list()
for movie in movies:
# 将解析后的电影信息加入列表中
movie_info_lst.append(parse_movie_tag(movie))
return movie_info_lst if __name__ == '__main__':
# 获取所有标签信息
all_tags = get_all_tags()
# 标签信息存到文件中
all_tags_file = codecs.open('all_tags_info.txt', 'wb')
all_tags_file.write('标签名\t标签url地址\r\n')
for tag_name, tag_url in all_tags:
all_tags_file.write('{0}\t{1}\r\n'.format(tag_name, tag_url))
all_tags_file.flush()
all_tags_file.close() # 获取每个标签下的所有电影
for tag_name, tag_url in all_tags:
movie_infos_file = codecs.open(tag_name + '.txt', 'wb')
movie_infos_file.write('电影名\t标签名\t电影描述\t评分\t详细链接\r\n')
start = 0
while True:
target_url = '{base_url}?start={start}'.format(base_url=tag_url,
start=start)
movies = get_current_page_movies(target_url)
for movie in movies:
title = movie.get('title', '')
detail_url = movie.get('detail_url', '')
desc = movie.get('desc', '')
rating_nums = movie.get('rating_nums', '')
movie_infos_file.write('{0}\t{1}\t{2}\t{3}\t{4}\r\n'.format(title,
tag_name,
desc,
rating_nums,
detail_url))
movie_infos_file.flush()
# 计算当前页电影总个数,因单页只显示15条信息,
# 所以如果单页电影数小于15则表示无后续页面,则跳出循环不再请求此分类
current_page_movies_count = len(movies)
if current_page_movies_count < 15:
break
# 请求下一页标记数
start += current_page_movies_count
movie_infos_file.close()
运行结果截图:
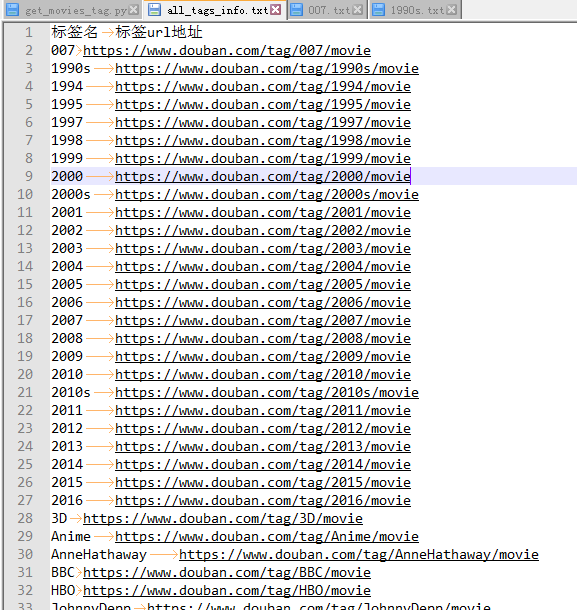
图1-电影标签信息
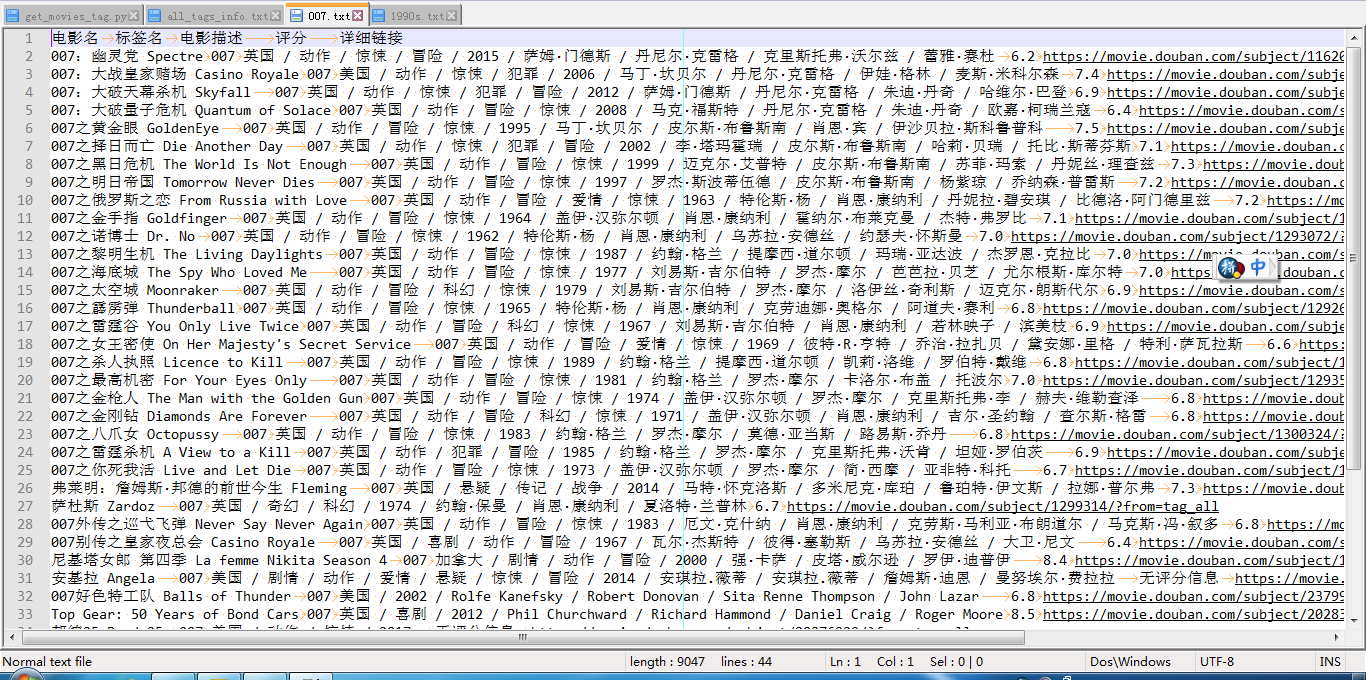
图2-具体分类下电影信息
后续优化:1、获取电影详细信息;2、请求太频繁会被禁止访问
003.[python学习] 简单抓取豆瓣网电影信息程序的更多相关文章
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- Python学习 - 简单抓取页面
最近想做一个小web应用,就是把豆瓣读书和亚马逊等写有书评的网站上关于某本书的打分记录下来,这样自己买书的时候当作参考. 这篇日志这是以豆瓣网为例,只讨论简单的功能. 向服务器发送查询请求 这很好处理 ...
- 抓取豆瓣的电影排行榜TOP100
#!/usr/bin/env python # -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前100的电影的名称 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
随机推荐
- UIImageView自适应图片大小
窗口大小获取: CGRect screenBounds = [ [UIScreenmainScreen]bounds];//返回的是带有状态栏的Rect CGRect rect = [ [UIScre ...
- JavaScript DOM&BOM
1.DOM含义 D: Document 文档 一份文档就是一棵节点树,每个节点都是一个对象O:Object 对象 JavaScript语言里对象可以分为三种类型: (1)用户定义的对象(user-de ...
- C++ 实数类
这是一堆我自己写完都怀疑人生的代码. 或许我见识太少了吧-- 实现一个实数类.这个类也可以看作是分数类.实现了基本的四则运算和比较.另外,与整数或小数的转换还没有实现,无限循环小数转分数也暂时没有实现 ...
- The Best Books on Game Dev
https://www.goodreads.com/list/show/99288.The_Best_Books_on_Game_Dev
- PHP swoole实现redis订阅和发布
前戏:实现用户下单,服务器通知后台接收订单...类似美团外卖 1.首先要实现一个订阅程序 $result = $client->connect('127.0.0.1', 6379, functi ...
- QNET,一款给力的APP弱网络测试工具
目前在测试移动设备上进行弱网络专项测试的方案主要有两种: 通过Android设备连接到PC上进行弱网络测试,比如Fiddler,Charles,NET-Simulator等.基本思路是在PC上装一个F ...
- Apache Atlas元数据管理从入门到实战(1)
一.前言 元数据管理是数据治理非常重要的一个方向,元数据的一致性,可追溯性,是实现数据治理非常重要的一个环节.传统数据情况下,有过多种相对成熟的元数据管理工具,而大数据时代,基于hadoop,最为 ...
- 使用 JavaScript 拦截和跟踪浏览器中的 HTTP 请求
HTTP 请求的拦截技术可以广泛地应用在反向代理.拦截 Ajax 通信.网页的在线翻译.网站改版重构等方面.而拦截根据位置可以分为服务器端和客户端两大类,客户端拦截借助 JavaScript 脚本技术 ...
- 报错:Heartbeating to master:7182 failed.
报错背景: cloudera-scm-agent 可以启动并且存活,但是jps没有进程. 报错现象: 查看报错日志:/opt/cm-5.15.1/log/cloudera-scm-agent/clou ...
- 报错:/usr/sbin/mysqld: Can't find file: './performance_schema/events_waits_summary_by_account_by_event_name.frm' (errno: 13 - Permission denied)
报错背景: Linux环境下安装MySQL数据库. 安装完成,数据库初始化,启动数据库时报错. 报错现象: -- :: [ERROR] Native table 'performance_schema ...