003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途。
本程序仍有很多不足之处,请读者不吝赐教。
依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装。下面是代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import sys
reload(sys)
sys.setdefaultencoding('utf-8') #解决编码问题 """一个简单的从豆瓣网获取电影标签的示例,
1. 首先获取所有标签以及它所对应的请求连接,
获取所有标签的请求链接是https://movie.douban.com/tag/?view=cloud
2. 请求每个标签对应的链接获取该标签下所有电影信息
""" import urllib
import urllib2
import re
import codecs
# BeautifulSoup 用于解析html使用,本程序中使用lxml作为解析器
from bs4 import BeautifulSoup # url正则表达式,用于将url分割为多个部分,对其中某些部分进行url编码使用
URL_RGX = re.compile(r'(?P<prefix>https?://)(?P<mid>[^?]+)(?P<has_key>\??)(?P<parms>[^?]*)')
DOUBAN_TAG_URL = r'https://movie.douban.com/tag/?view=cloud' # url请求
def get_request(url):
# 对url特定部分进行编码
matches = URL_RGX.match(url)
if matches:
dic = matches.groupdict()
prefix = dic.get('prefix', '')
mid = urllib.quote(dic.get('mid', ''))
has_key = dic.get('has_key', '')
parms = dic.get('parms', '')
if parms != '':
tmp_dic = dict()
for kv in parms.split('&'):
k, v = kv, ''
if '=' in kv:
k, v = kv.split('=', 1)
tmp_dic[k] = v
parms = urllib.urlencode(tmp_dic)
url = '{0}{1}{2}{3}'.format(prefix, mid, has_key, parms)
else:
url = None
if url:
try:
res = urllib.urlopen(url)
if res and res.getcode() == 200:
return res.read()
except Exception as e:
pass
return '' # 获取所有标签信息,返回值为列表,列表中每个元素格式为(标签名, 标签url地址)
def get_all_tags():
all_tags = list()
page_text = get_request(DOUBAN_TAG_URL)
soup = BeautifulSoup(page_text, 'lxml')
tags = soup.find_all('a', attrs={'class': 'tag'})
for tag in tags:
tag_name = tag.string
# 将原有链接中的?focus=替换为空,替换后url为分页显示地址
tag_url = tag['href'].replace('?focus=', '')
all_tags.append((tag_name, tag_url))
return all_tags # 解析单个电影节点信息,返回电影信息字典
def parse_movie_tag(movie_tag):
# 下面15行代码好烂,下次改下它
movie_title_tag = movie_tag.find('a', attrs={'class': 'title'})
movie_title = '无名电影'
movie_detail_url = '无链接'
if movie_title_tag:
movie_title = movie_title_tag.string.strip()
movie_detail_url = movie_title_tag['href'].strip()
# movie_detail_url = movie_tag.find('a', attrs={'class': 'title'})['href']
movie_desc_tag = movie_tag.find('div', attrs={'class': 'desc'})
movie_desc = '无描述信息'
if movie_desc_tag:
movie_desc = movie_desc_tag.string.strip()
movie_rating_nums_tag = movie_tag.find('span', attrs={'class': 'rating_nums'})
movie_rating_nums = '无评分信息'
if movie_rating_nums_tag:
movie_rating_nums = movie_rating_nums_tag.string.strip()
return {'title': movie_title, 'detail_url': movie_detail_url,
'desc': movie_desc, 'rating_nums': movie_rating_nums} # 获取当前页面中的电影信息节点
def get_current_page_movies(page_url):
page_text = get_request(page_url)
soup = BeautifulSoup(page_text, 'lxml')
movies = soup.find_all('dd')
movie_info_lst = list()
for movie in movies:
# 将解析后的电影信息加入列表中
movie_info_lst.append(parse_movie_tag(movie))
return movie_info_lst if __name__ == '__main__':
# 获取所有标签信息
all_tags = get_all_tags()
# 标签信息存到文件中
all_tags_file = codecs.open('all_tags_info.txt', 'wb')
all_tags_file.write('标签名\t标签url地址\r\n')
for tag_name, tag_url in all_tags:
all_tags_file.write('{0}\t{1}\r\n'.format(tag_name, tag_url))
all_tags_file.flush()
all_tags_file.close() # 获取每个标签下的所有电影
for tag_name, tag_url in all_tags:
movie_infos_file = codecs.open(tag_name + '.txt', 'wb')
movie_infos_file.write('电影名\t标签名\t电影描述\t评分\t详细链接\r\n')
start = 0
while True:
target_url = '{base_url}?start={start}'.format(base_url=tag_url,
start=start)
movies = get_current_page_movies(target_url)
for movie in movies:
title = movie.get('title', '')
detail_url = movie.get('detail_url', '')
desc = movie.get('desc', '')
rating_nums = movie.get('rating_nums', '')
movie_infos_file.write('{0}\t{1}\t{2}\t{3}\t{4}\r\n'.format(title,
tag_name,
desc,
rating_nums,
detail_url))
movie_infos_file.flush()
# 计算当前页电影总个数,因单页只显示15条信息,
# 所以如果单页电影数小于15则表示无后续页面,则跳出循环不再请求此分类
current_page_movies_count = len(movies)
if current_page_movies_count < 15:
break
# 请求下一页标记数
start += current_page_movies_count
movie_infos_file.close()
运行结果截图:
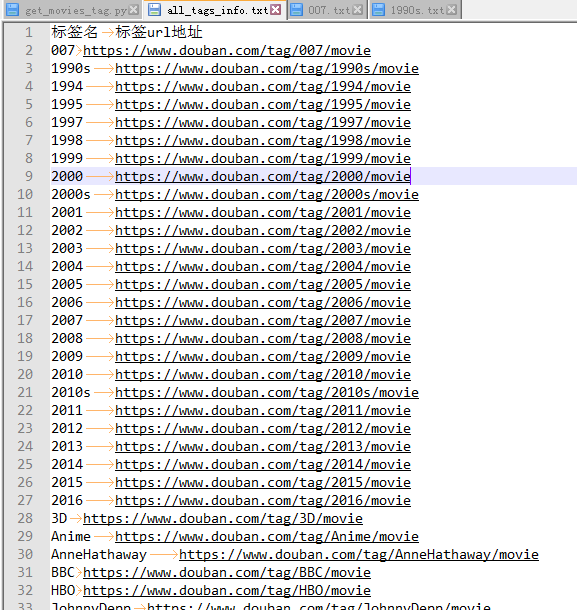
图1-电影标签信息
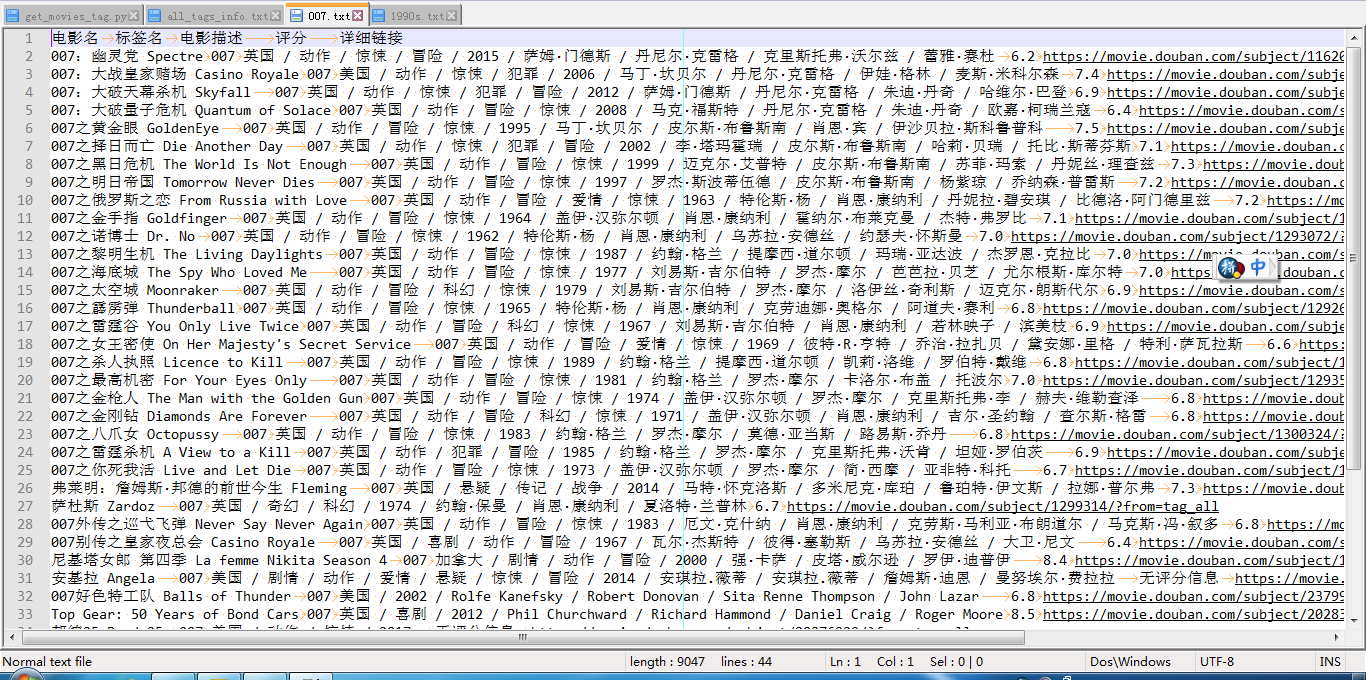
图2-具体分类下电影信息
后续优化:1、获取电影详细信息;2、请求太频繁会被禁止访问
003.[python学习] 简单抓取豆瓣网电影信息程序的更多相关文章
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- Python学习 - 简单抓取页面
最近想做一个小web应用,就是把豆瓣读书和亚马逊等写有书评的网站上关于某本书的打分记录下来,这样自己买书的时候当作参考. 这篇日志这是以豆瓣网为例,只讨论简单的功能. 向服务器发送查询请求 这很好处理 ...
- 抓取豆瓣的电影排行榜TOP100
#!/usr/bin/env python # -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前100的电影的名称 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
随机推荐
- 文件及文件夹操作- File类、Directory 类、FileInfo 类、DirectoryInfo 类
文件及文件夹操作: C/S:WinForm可以操作客户端文件 Client ServerB/S:Brower Server 命名空间:using system .IO; 1. File类: 创建:Fi ...
- sublime An unhandled OS error was encountered nodejspath_error
sublime An unhandled OS error was encountered nodejspath_error 点击ok,修改node_path typescript 插件下载 ctr ...
- ORACLE数据库_迁移(新机器,新存储)
迁移: (10g 64老机器,老存储) ------>(11g 64新机器,新存储)注意要点:新老服务的时间,字符集,sid升级顺序:10.2.0.1------>10.2.0.4或10. ...
- asd短片数篇
黄乙己 黄乙己是站着AK而正常的唯一的人.他身材挺高大:蜡黄脸色,眼角间时常夹着些饼干屑:一副黑色的眼镜.虽然挺正常,可是他有良好的饮食习惯,似乎十多个月都是吃的牛奶泡饭,也没有洗饭盒.他对人说话,总 ...
- 前端的UI框架
iView 框架 使用场景 iView 主要适合大中型中后台产品,比如某产品的运营平台.数据监控平台.管理平台等,从工程配置.到样式布局,甚至后面规划的业务套件,是一整套的解决方案,所以它可能不太适合 ...
- 服务器A制定计划任务,BAT脚本自动备份oracle数据文件,拷贝至服务器B的共享目录。
运行环境:windows server 2008 R2 目的:在数据库服务器A进行数据库自动备份,并且保留5天. 为了安全,需要在web应用服务器B进行数据库的冗余备份,建立双保险.(保留15天) A ...
- hibernate的lazy初始化结果
package com.ehcache; import java.io.Serializable; public class User implements Serializable{ private ...
- java数据结构之HashSet和HashMap(java核心卷Ⅰ读书笔记)
增加 删除 remove方法,可以删除指定的一个元素. 查找 ********************* **************************** HashSet既不可以用 0 1 2 ...
- mysql根据某个字符串拆分表中的字段,然后赋值给另外一个字段
sql语句示例: UPDATE user_info SET area_code = SUBSTRING_INDEX(telphone,'-',1) SUBSTRING_INDEX函数说明: subs ...
- kvm中重命名虚拟机
kvm中重命名虚拟机 1.查看虚拟机 [root@linux ~]# virsh list --all Id Name State ---------------------------------- ...