【HDFS API编程】副本系数深度剖析
上一节我们使用Java API操作HDFS文件系统创建了文件a.txt并写入了hello hadoop(回顾:https://www.cnblogs.com/Liuyt-61/p/10739018.html)
我们在终端控制台上使用hadoop fs -ls /hdfsapi/test查看a.txt文件是否创建成功的时候有没有发现一个问题。
[hadoop@hadoop000 ~]$ hadoop fs -ls /hdfsapi/test
Found 1 items
-rw-r--r-- 3 hadoop supergroup 14 2019-04-19 16:31 /hdfsapi/test/a.txt
为什么a.txt文件创建了3个副本文件?
我们来到浏览器中查看a.txt文件,也是显示创建了3个副本文件。
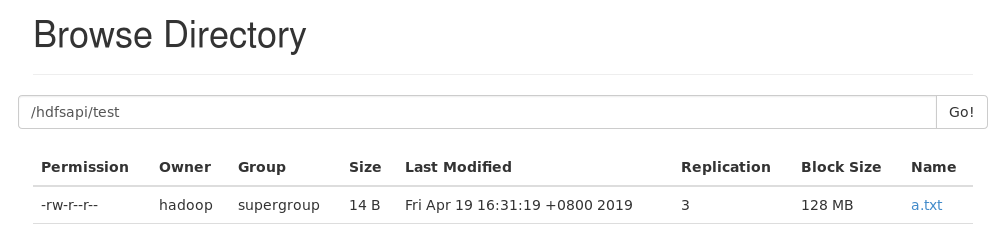
我们点开a.txt,block,用户名都是在里面的
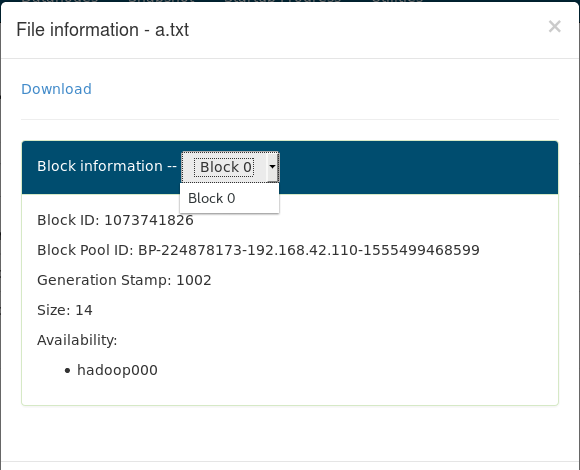
问题来了,为什么是3呀?
还记不记得我们在查看HDFS文件内容的时候-put了一个README.txt文件(见最顶上回顾链接),我们通过浏览器发现它的副本系数是1。

这里为 1 ,我们可能应该知道是我们在/hadoop/etc/hadoop/hdfs-site.xml文件下副本系数设置的为1。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
那么我们使用hdfs shell脚本的方式设置上去他默认走的是我们hdfs-site的配置为 1。那么为什么外面使用Java API传上去的怎么就不是1了?
我们写一个测试类来查看下使用Java API下的副本系数是多少。
public class HDFSApp {
public static final String HDFS_PATH = "hdfs://hadoop000:8020";
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void setUp() throws Exception{
System.out.println("setUp-----------");
configuration = new Configuration();/*
* 构造一个访问制定HDFS系统的客户端对象
* 第一个参数:HDFS的URI
* 第二个参数:客户端制定的配置参数
* 第三个参数:客户端的身份,说白了就是用户名
*/
fileSystem = FileSystem.get(new URI(HDFS_PATH),configuration,"hadoop");
}
@Test
public void testReplication(){
System.out.println(configuration.get("dfs.replication"));
}
@After
public void tearDown(){
configuration = null;
fileSystem = null;
System.out.println("----------tearDown------");
}
}
输出:
/home/hadoop/app/jdk1.8.0_91/bin/java -ea -Didea.test.cyclic.buffer.size=1048576 -javaagent:/home/hadoop/app/idea-IU-183.5429.30/lib/idea_rt.jar=40319:/home/hadoop/app/idea-IU-183.5429.30/bin -Dfile.encoding=UTF-8 -classpath /home/hadoop/app/idea-IU-183.5429.30/lib/idea_rt.jar:/home/hadoop/app/idea-IU-183.5429.30/plugins/junit/lib/junit-rt.jar:/home/hadoop/app/idea-IU-183.5429.30/plugins/junit/lib/junit5-rt.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/charsets.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/deploy.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/cldrdata.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/dnsns.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/jaccess.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/jfxrt.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/localedata.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/nashorn.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/sunec.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/sunjce_provider.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/sunpkcs11.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/ext/zipfs.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/javaws.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/jce.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/jfr.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/jfxswt.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/jsse.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/management-agent.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/plugin.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/resources.jar:/home/hadoop/app/jdk1.8.0_91/jre/lib/rt.jar:/home/hadoop/IdeaProjects/hadoop-train-v2/target/test-classes:/home/hadoop/IdeaProjects/hadoop-train-v2/target/classes:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-client/2.6.0-cdh5.15.1/hadoop-client-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-common/2.6.0-cdh5.15.1/hadoop-common-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/com/google/guava/guava/11.0.2/guava-11.0.2.jar:/home/hadoop/.m2/repository/commons-cli/commons-cli/1.2/commons-cli-1.2.jar:/home/hadoop/.m2/repository/org/apache/commons/commons-math3/3.1.1/commons-math3-3.1.1.jar:/home/hadoop/.m2/repository/xmlenc/xmlenc/0.52/xmlenc-0.52.jar:/home/hadoop/.m2/repository/commons-httpclient/commons-httpclient/3.1/commons-httpclient-3.1.jar:/home/hadoop/.m2/repository/commons-codec/commons-codec/1.4/commons-codec-1.4.jar:/home/hadoop/.m2/repository/commons-io/commons-io/2.4/commons-io-2.4.jar:/home/hadoop/.m2/repository/commons-net/commons-net/3.1/commons-net-3.1.jar:/home/hadoop/.m2/repository/commons-collections/commons-collections/3.2.2/commons-collections-3.2.2.jar:/home/hadoop/.m2/repository/commons-logging/commons-logging/1.1.3/commons-logging-1.1.3.jar:/home/hadoop/.m2/repository/log4j/log4j/1.2.17/log4j-1.2.17.jar:/home/hadoop/.m2/repository/commons-lang/commons-lang/2.6/commons-lang-2.6.jar:/home/hadoop/.m2/repository/commons-configuration/commons-configuration/1.6/commons-configuration-1.6.jar:/home/hadoop/.m2/repository/commons-digester/commons-digester/1.8/commons-digester-1.8.jar:/home/hadoop/.m2/repository/commons-beanutils/commons-beanutils/1.7.0/commons-beanutils-1.7.0.jar:/home/hadoop/.m2/repository/commons-beanutils/commons-beanutils-core/1.8.0/commons-beanutils-core-1.8.0.jar:/home/hadoop/.m2/repository/org/slf4j/slf4j-api/1.7.5/slf4j-api-1.7.5.jar:/home/hadoop/.m2/repository/org/slf4j/slf4j-log4j12/1.7.5/slf4j-log4j12-1.7.5.jar:/home/hadoop/.m2/repository/org/codehaus/jackson/jackson-core-asl/1.8.8/jackson-core-asl-1.8.8.jar:/home/hadoop/.m2/repository/org/codehaus/jackson/jackson-mapper-asl/1.8.8/jackson-mapper-asl-1.8.8.jar:/home/hadoop/.m2/repository/org/apache/avro/avro/1.7.6-cdh5.15.1/avro-1.7.6-cdh5.15.1.jar:/home/hadoop/.m2/repository/com/thoughtworks/paranamer/paranamer/2.3/paranamer-2.3.jar:/home/hadoop/.m2/repository/org/xerial/snappy/snappy-java/1.0.4.1/snappy-java-1.0.4.1.jar:/home/hadoop/.m2/repository/com/google/protobuf/protobuf-java/2.5.0/protobuf-java-2.5.0.jar:/home/hadoop/.m2/repository/com/google/code/gson/gson/2.2.4/gson-2.2.4.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-auth/2.6.0-cdh5.15.1/hadoop-auth-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/httpcomponents/httpclient/4.2.5/httpclient-4.2.5.jar:/home/hadoop/.m2/repository/org/apache/httpcomponents/httpcore/4.2.4/httpcore-4.2.4.jar:/home/hadoop/.m2/repository/org/apache/directory/server/apacheds-kerberos-codec/2.0.0-M15/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/.m2/repository/org/apache/directory/server/apacheds-i18n/2.0.0-M15/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/.m2/repository/org/apache/directory/api/api-asn1-api/1.0.0-M20/api-asn1-api-1.0.0-M20.jar:/home/hadoop/.m2/repository/org/apache/directory/api/api-util/1.0.0-M20/api-util-1.0.0-M20.jar:/home/hadoop/.m2/repository/org/apache/curator/curator-framework/2.7.1/curator-framework-2.7.1.jar:/home/hadoop/.m2/repository/org/apache/curator/curator-client/2.7.1/curator-client-2.7.1.jar:/home/hadoop/.m2/repository/org/apache/curator/curator-recipes/2.7.1/curator-recipes-2.7.1.jar:/home/hadoop/.m2/repository/com/google/code/findbugs/jsr305/3.0.0/jsr305-3.0.0.jar:/home/hadoop/.m2/repository/org/apache/htrace/htrace-core4/4.0.1-incubating/htrace-core4-4.0.1-incubating.jar:/home/hadoop/.m2/repository/org/apache/zookeeper/zookeeper/3.4.5-cdh5.15.1/zookeeper-3.4.5-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/commons/commons-compress/1.4.1/commons-compress-1.4.1.jar:/home/hadoop/.m2/repository/org/tukaani/xz/1.0/xz-1.0.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-hdfs/2.6.0-cdh5.15.1/hadoop-hdfs-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/mortbay/jetty/jetty-util/6.1.26.cloudera.4/jetty-util-6.1.26.cloudera.4.jar:/home/hadoop/.m2/repository/io/netty/netty/3.10.5.Final/netty-3.10.5.Final.jar:/home/hadoop/.m2/repository/io/netty/netty-all/4.0.23.Final/netty-all-4.0.23.Final.jar:/home/hadoop/.m2/repository/xerces/xercesImpl/2.9.1/xercesImpl-2.9.1.jar:/home/hadoop/.m2/repository/xml-apis/xml-apis/1.3.04/xml-apis-1.3.04.jar:/home/hadoop/.m2/repository/org/fusesource/leveldbjni/leveldbjni-all/1.8/leveldbjni-all-1.8.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-app/2.6.0-cdh5.15.1/hadoop-mapreduce-client-app-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-common/2.6.0-cdh5.15.1/hadoop-mapreduce-client-common-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-yarn-client/2.6.0-cdh5.15.1/hadoop-yarn-client-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-yarn-server-common/2.6.0-cdh5.15.1/hadoop-yarn-server-common-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-shuffle/2.6.0-cdh5.15.1/hadoop-mapreduce-client-shuffle-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-yarn-api/2.6.0-cdh5.15.1/hadoop-yarn-api-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-core/2.6.0-cdh5.15.1/hadoop-mapreduce-client-core-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-yarn-common/2.6.0-cdh5.15.1/hadoop-yarn-common-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/javax/xml/bind/jaxb-api/2.2.2/jaxb-api-2.2.2.jar:/home/hadoop/.m2/repository/javax/xml/stream/stax-api/1.0-2/stax-api-1.0-2.jar:/home/hadoop/.m2/repository/javax/activation/activation/1.1/activation-1.1.jar:/home/hadoop/.m2/repository/javax/servlet/servlet-api/2.5/servlet-api-2.5.jar:/home/hadoop/.m2/repository/com/sun/jersey/jersey-core/1.9/jersey-core-1.9.jar:/home/hadoop/.m2/repository/com/sun/jersey/jersey-client/1.9/jersey-client-1.9.jar:/home/hadoop/.m2/repository/org/codehaus/jackson/jackson-jaxrs/1.8.8/jackson-jaxrs-1.8.8.jar:/home/hadoop/.m2/repository/org/codehaus/jackson/jackson-xc/1.8.8/jackson-xc-1.8.8.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-jobclient/2.6.0-cdh5.15.1/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-aws/2.6.0-cdh5.15.1/hadoop-aws-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/com/amazonaws/aws-java-sdk-bundle/1.11.134/aws-java-sdk-bundle-1.11.134.jar:/home/hadoop/.m2/repository/com/fasterxml/jackson/core/jackson-core/2.2.3/jackson-core-2.2.3.jar:/home/hadoop/.m2/repository/com/fasterxml/jackson/core/jackson-databind/2.2.3/jackson-databind-2.2.3.jar:/home/hadoop/.m2/repository/com/fasterxml/jackson/core/jackson-annotations/2.2.3/jackson-annotations-2.2.3.jar:/home/hadoop/.m2/repository/org/apache/hadoop/hadoop-annotations/2.6.0-cdh5.15.1/hadoop-annotations-2.6.0-cdh5.15.1.jar:/home/hadoop/.m2/repository/junit/junit/4.11/junit-4.11.jar:/home/hadoop/.m2/repository/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar com.intellij.rt.execution.junit.JUnitStarter -ideVersion5 -junit4 com.LIuyt.bigdata.hadoop.hdfs.HDFSApp,testReplication
setUp-----------
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
3
----------tearDown------
Process finished with exit code 0
看到输出里面没,3 ,这个3怎么来的?
在project中的外部库中找到如图所示hdfs-default.xml文件,我们可以看到里面的副本系数参数配置是3。
因为我们new出来的Configuration configuration = null,它自己就会去加载default.xml,所以它读取出来的是3。
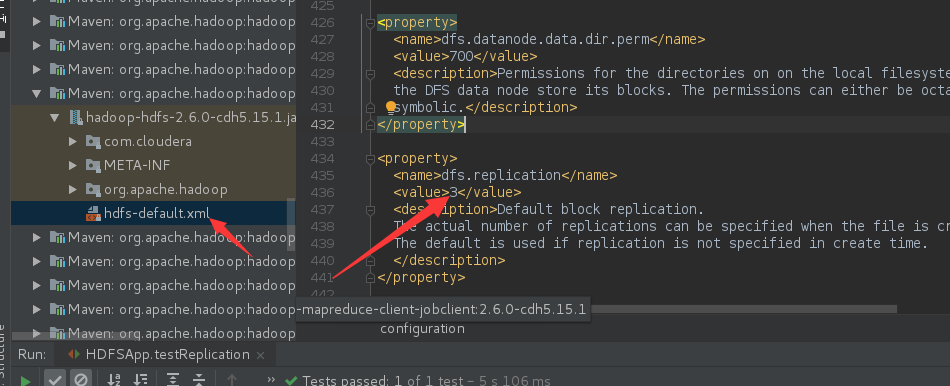
既然我们已经知道了原因,那么我们就可以new之后自己设置一下:
configuration = new Configuration();
configuration.set("dfs.replication","1");
我们再通过同样的方法在a.txt的文件目录下创建一个b.txt来测试一下
@Test
public void create() throws Exception{
//FSDataOutputStream out = fileSystem.create(new Path("/hdfsapi/test/a.txt"));
FSDataOutputStream out = fileSystem.create(new Path("/hdfsapi/test/b.txt"));
out.writeUTF("Hello hadoop:replication 1");
out.flush();//输出走缓冲区,所以先flush
out.close();
}
我们再通过终端 -ls查看一下,此时b.txt文件的副本数就是 1 ,再通过浏览器再看一看副本数也是 1 。
[hadoop@hadoop000 ~]$ hadoop fs -ls /hdfsapi/test
Found 2 items
-rw-r--r-- 3 hadoop supergroup 14 2019-04-19 16:31 /hdfsapi/test/a.txt
-rw-r--r-- 1 hadoop supergroup 28 2019-04-19 16:50 /hdfsapi/test/b.txt
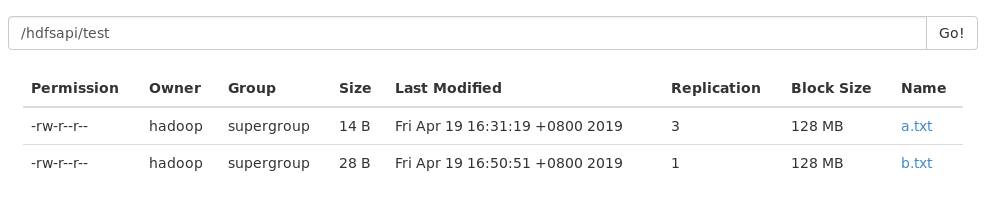
总结:如果是通过命令行传输的就以hdfs-site配置的为准,如果是通过代码传输的就以代码设置的为准。
【HDFS API编程】副本系数深度剖析的更多相关文章
- 【HDFS API编程】从本地拷贝文件,从本地拷贝大文件,拷贝HDFS文件到本地
接着之前继续API操作的学习 CopyFromLocalFile: 顾名思义,从本地文件拷贝 /** * 使用Java API操作HDFS文件系统 * 关键点: * 1)create Configur ...
- 【HDFS API编程】查看HDFS文件内容、创建文件并写入内容、更改文件名
首先,重点重复重复再重复: /** * 使用Java API操作HDFS文件系统 * 关键点: * 1)创建 Configuration * 2)获取 FileSystem * 3)...剩下的就是 ...
- 【HDFS API编程】jUnit封装-改写创建文件夹
首先:什么是jUnit 回顾: https://www.cnblogs.com/Liuyt-61/p/10374732.html 上一节我们知道: /** * 使用Java API操作HDFS文件系 ...
- 【HDFS API编程】第一个应用程序的开发-创建文件夹
/** * 使用Java API操作HDFS文件系统 * 关键点: * 1)创建 Configuration * 2)获取 FileSystem * 3)...剩下的就是 HDFS API的操作了*/ ...
- 【HDFS API编程】开发环境搭建
使用HDFS API的方式来操作HDFS文件系统 IDEA Java 使用Maven来管理项目 先打开IDEA,New Project 创建GAV然后next 默认使用的有idea内置的Maven,可 ...
- 【HDFS API编程】查看文件块信息
现在我们把文件都存在HDFS文件系统之上,现在有一个jdk.zip文件存储在上面,我们想知道这个文件在哪些节点之上?切成了几个块?每个块的大小是怎么样?先上测试类代码: /** * 查看文件块信息 * ...
- 【HDFS API编程】查看目标文件夹下的所有文件、递归查看目标文件夹下的所有文件
使用hadoop命令:hadoop fs -ls /hdfsapi/test 我们能够查看HDFS文件系统/hdfsapi/test目录下的所有文件信息 那么使用代码怎么写呢?直接先上代码:(这之后 ...
- 干货--安装eclipse-hadoop-plugin插件及HDFS API编程两个遇到的重要错误的解决
在Windows的eclipse上写hdfs的API程序,都会遇到两个错误,在网上查了很多资料,都没有解决的办法,经过了很多时间的研究,终于把这个问题解决了 错误是 1.java.io.IOExcep ...
- HDFS API编程
3.1常用类 3.1.1Configuration Hadoop配置文件的管理类,该类的对象封装了客户端或者服务器的配置(配置集群时,所有的xml文件根节点都是configuration ...
随机推荐
- $(window).scroll()无法触发问题
在微信端开发中遇到一个这种问题:明明用的公共文件(代码如下图),其他页面每次都能触发这个滚动条$(window).scroll事件,以显示右下角“回到顶部”这个按钮图标 但是,问题来了,最该需要使用“ ...
- java第三章笔记
java的基本程序设计结构: 1. 声明一个变量之后,必须用赋值语句对变量进行显示初始化,千万不能使用未被初始化的变量. 2.在java中不区分变量的声明与定义. 3.当参与/运算的两个操作数都是整数 ...
- adv生成控制器手腕位置倾斜原因以及解决方案
系统默认问题导致手腕倾斜详情描述: 手腕部分默认生成轴向是冲向模板下一层级第一个物体 简单说就是 FK轴向冲向模板中指方向 如图 默认模板没问题是因为 默认模板没有改动情况下系统中指与手腕在一条直 ...
- Ubuntu 下超简单的安装指定版本的nodejs
第一步 指定版本源 执行 curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash - setup_5.x 需要安装的版本号,替换数字就 ...
- Deloyment Descriptor web.xml
Deployment Descriptor部署描述符: - 部署描述符是要部署到Web容器或EJB容器的Web应用程序或EJB应用程序的配置文件. - 部署描述符应包含EJB应用程序中所有企业bean ...
- Git学习之第一次使用PR
发起PR的流程 1.Fork想要pr的项目,在自己的仓库里建立一个相同的项目. 2.Clone我们Fork的项目,在本地建立一个项目,方便修改. 3.将修改后的本地项目上传到github上. 4.向原 ...
- ubuntu16.04 使用kinectv2跑Elasticfusion
1.安装openni2 参考:https://blog.csdn.net/D206_hero/article/details/78985859?utm_source=blogxgwz3 sudo a ...
- 2-Add Two Numbers @LeetCode
2-Add Two Numbers @LeetCode 题目 思路 题目中得到的信息有: 这是两个非负数,每位分别保存在链表的一个结点上: 逆序保存,从低位到高位依次. 一般整数的相加都是从低往高进行 ...
- flagr 数据库配置
flagr 是一个很不错的特性开关.a/b 测试服务,默认使用的是sqlite 数据库,但是我们可以通过配置,使用不同的数据库 sqlite.mysql.postrgresql.json_file.j ...
- imp 导入报错
imp user/passwd file=/data/oracle/oraclesetup/passwd.dmp 报错: Export file created by EXPORT:V11.02.00 ...