一起学Hadoop——TotalOrderPartitioner类实现全局排序
- SplitSampler 分片采样器,从数据分片中采样数据,该采样器不适合已经排好序的数据
- RandomSampler随机采样器,按照设置好的采样率从一个数据集中采样
- IntervalSampler间隔采样机,以固定的间隔从分片中采样数据,对于已经排好序的数据效果非常好。
public class TotalSortMap extends Mapper<Text, Text, Text, IntWritable> {
@Override
protected void map(Text key, Text value,
Context context) throws IOException, InterruptedException {
context.write(key, new IntWritable(Integer.parseInt(key.toString())));
}
}
public class TotalSortReduce extends Reducer<Text, IntWritable, IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
for (IntWritable value : values)
context.write(value, NullWritable.get());
}
}
入口类:
public class TotalSort extends Configured implements Tool{
//实现一个Kye比较器,用于比较两个key的大小,将key由字符串转化为Integer,然后进行比较。
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable writableComparable1, WritableComparable writableComparable2) {
int num1 = Integer.parseInt(writableComparable1.toString());
int num2 = Integer.parseInt(writableComparable2.toString());
return num1 - num2;
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.totalorderpartitioner.naturalorder", "false");
Job job = Job.getInstance(conf, "Total Sort app");
job.setJarByClass(TotalSort.class);
//设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置比较器,用于比较数据的大小,然后按顺序排序,该例子主要用于比较两个key的大小
job.setSortComparatorClass(KeyComparator.class);
job.setNumReduceTasks(3);//设置reduce数量
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
//设置保存partitions文件的路径
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]));
//key值采样,0.01是采样率,
InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 1000, 100);
//将采样数据写入到分区文件中
InputSampler.writePartitionFile(job, sampler);
job.setMapperClass(TotalSortMap.class);
job.setReducerClass(TotalSortReduce.class);
//设置分区类。
job.setPartitionerClass(TotalOrderPartitioner.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args)throws Exception{
int exitCode = ToolRunner.run(new TotalSort(), args);
System.exit(exitCode);
}
}
#!/bin/bash
do
for k in $(seq )
echo $RANDOM;
done
sh create_data.sh > test_data.txt
hadoop fs -put test_data.txt /data/
/usr/local/src/hadoop-2.6./bin/hadoop jar TotalSort.jar \
hdfs://hadoop-master:8020/data/test_data1.txt \
hdfs://hadoop-master:8020/total_sort_output \
hdfs://hadoop-master:8020/total_sort_partitions
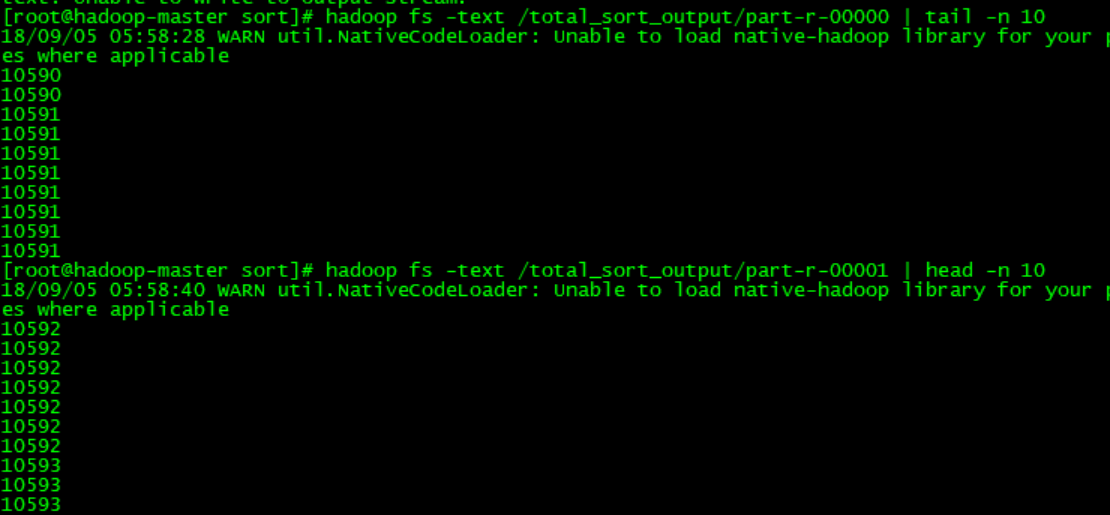
下面有几个坑要注意,大家不要踩:
- 数据的输入类型必须使用KeyValueTextInputFormat类而不是TextInputFormat类,因为hadoop采样器是对key值采样,而TextInputFormat的key是位置偏移量,value存放的是每行的输入数据,对该key采样没有任何意义。KeyValueTextInputFormat的key存放的是输入数据,对key采样才能更好的划分分区。用法:
job.setInputFormatClass(KeyValueTextInputFormat.class);
- 使用代码conf.set("mapreduce.totalorderpartitioner.naturalorder", "false")设置分区的排序策略,否则是每个分区内有序,而不是全局有序。
- 采样器只能是Text,Text类型:InputSampler.Sampler<Text, Text>,否则会报Exception in thread "main" java.io.IOException: wrong key class: org.apache.hadoop.io.Text is not class org.apache.hadoop.io.LongWritable这个错误。
- job.setMapOutputKeyClass(Text.class)和job.setMapOutputValueClass(IntWritable.class)这两行代码必须在InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 1000, 100);这行代码之前调用,否则会报Exception in thread "main" java.io.IOException: wrong key class: org.apache.hadoop.io.Text is not class org.apache.hadoop.io.LongWritable错误。
- 调用setSortComparatorClass方法设置排序类,对key进行排序。job.setSortComparatorClass(KeyComparator.class);类似例子中的KeyComparator类。否则是按照字典序进行排序。MapReduce默认输出的key是字符类型时,默认是按照字典序排序。
一起学Hadoop——TotalOrderPartitioner类实现全局排序的更多相关文章
- Hadoop对文本文件的快速全局排序
一.背景 Hadoop中实现了用于全局排序的InputSampler类和TotalOrderPartitioner类,调用示例是org.apache.hadoop.examples.Sort. 但是当 ...
- MapReduce TotalOrderPartitioner 全局排序
我们知道Mapreduce框架在feed数据给reducer之前会对map output key排序,这种排序机制保证了每一个reducer局部有序,hadoop 默认的partitioner是Has ...
- 三种方法实现Hadoop(MapReduce)全局排序(1)
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序.但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序.基于此,本文提供三 ...
- 一起学Hadoop——使用自定义Partition实现hadoop部分排序
排序在很多业务场景都要用到,今天本文介绍如何借助于自定义Partition类实现hadoop部分排序.本文还是使用java和python实现排序代码. 1.部分排序. 部分排序就是在每个文件中都是有序 ...
- Hadoop的partitioner、全排序
按数值排序 示例:按气温字段对天气数据集排序问题:不能将气温视为Text对象并以字典顺序排序正统做法:用顺序文件存储数据,其IntWritable键代表气温,其Text值就是数据行常用简单做法:首先, ...
- MapReduce怎么优雅地实现全局排序
思考 想到全局排序,是否第一想到的是,从map端收集数据,shuffle到reduce来,设置一个reduce,再对reduce中的数据排序,显然这样和单机器并没有什么区别,要知道mapreduce框 ...
- [大牛翻译系列]Hadoop(6)MapReduce 排序:总排序(Total order sorting)
4.2.2 总排序(Total order sorting) 有的时候需要将作业的的所有输出进行总排序,使各个输出之间的结果是有序的.有以下实例: 如果要得到某个网站中最受欢迎的网址(URL),就需要 ...
- Mapreduce的排序(全局排序、分区加排序、Combiner优化)
一.MR排序的分类 1.部分排序:MR会根据自己输出记录的KV对数据进行排序,保证输出到每一个文件内存都是经过排序的: 2.全局排序: 3.辅助排序:再第一次排序后经过分区再排序一次: 4.二次排序: ...
- 大数据mapreduce全局排序top-N之python实现
a.txt.b.txt文件如下: a.txt hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop ...
随机推荐
- 【Tomcat】tomcat内存配置登记册
20141202: 环境:windows2003 tomcat6.x jdk1.6 启动方式:windows服务方式启动 启动异常:java.lang.OutOfMemoryError: PermGe ...
- localtime函数和strftime函数
localtime函数 功能: 把从1970-1-1零点零分到当前时间系统所偏移的秒数时间转换为本地时间,而gmtime函数转换后的时间没有经过时区变换,是UTC时间 . 用法: #include & ...
- 缓存系列之二:CDN与其他层面缓存
缓存系列之二:CDN与其他层面缓存 一:内容分发网络(Content Delivery Network),通过将服务内容分发至全网加速节点,利用全球调度系统使用户能够就近获取,有效降低访问延迟,提升服 ...
- Linux i2c 读写程序
/* This software uses a BSD license. Copyright (c) 2010, Sean Cross / chumby industriesAll rights re ...
- MR1和MR2(Yarn)工作原理流程
一.Mapreduce1 图1 MR1工作原理图 工作流程主要分为以下6个步骤: 1 作业的提交 1)客户端向jobtracker请求一个新的作业ID(通过JobTracker的getNewJobI ...
- JMeter3.2生成图形化HTML报告
JMeter3.0引入了Dashboard Report,用于生成HTML页面格式图形化报告的扩展模块. 该模块支持通过两种方式生成多维度图形化测试报告: 在JMeter性能测试结束时,自动生成本次测 ...
- SpriteKit 学习体会贴(不断完善中)
1. 关于 SKShapeNode 刚接触SpriteKit时,看到这个类,以为它会比SKSpriteNode更为轻量级,但其实不是: Shape nodes are useful for conte ...
- C#一元二次方程
- Confluence 6 后台中的默认空间模板设置
Confluence 6 后台中的默认空间模板设置界面的布局. https://www.cwiki.us/display/CONFLUENCEWIKI/Customizing+Default+Spac ...
- Confluence 6 中进行用户管理的优化配置和限制的基本建议
避免跨目录的多个用户名:如果你连接了超过一个的目录服务器,我们建议你需要确定你的用户名在目录服务器中是唯一的.例如:我们不建议你定义一个用户同时在'Directory1' 和 'Directory2' ...