Self Organizing Maps (SOM): 一种基于神经网络的聚类算法
自组织映射神经网络, 即Self Organizing Maps (SOM), 可以对数据进行无监督学习聚类。它的思想很简单,本质上是一种只有输入层--隐藏层的神经网络。隐藏层中的一个节点代表一个需要聚成的类。训练时采用“竞争学习”的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫“winning neuron”。 紧接着用随机梯度下降法更新激活节点的参数。同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
所以,SOM的一个特点是,隐藏层的节点是有拓扑关系的。这个拓扑关系需要我们确定,如果想要一维的模型,那么隐藏节点依次连成一条线;如果想要二维的拓扑关系,那么就行成一个平面,如下图所示(也叫Kohonen Network):
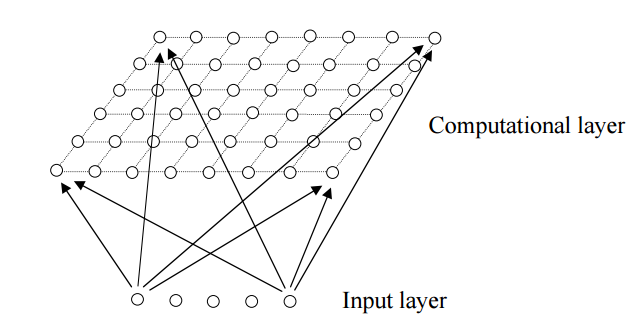
既然隐藏层是有拓扑关系的,所以我们也可以说,SOM可以把任意维度的输入离散化到一维或者二维(更高维度的不常见)的离散空间上。 Computation layer里面的节点与Input layer的节点是全连接的。
拓扑关系确定后,开始计算过程,大体分成几个部分:
1) 初始化:每个节点随机初始化自己的参数。每个节点的参数个数与Input的维度相同。
2)对于每一个输入数据,找到与它最相配的节点。假设输入时D维的, 即 X={x_i, i=1,...,D},那么判别函数可以为欧几里得距离:

3) 找到激活节点I(x)之后,我们也希望更新和它临近的节点。令S_ij表示节点i和j之间的距离,对于I(x)临近的节点,分配给它们一个更新权重:

简单地说,临近的节点根据距离的远近,更新程度要打折扣。
4)接着就是更新节点的参数了。按照梯度下降法更新:

迭代,直到收敛。
与K-Means的比较
同样是无监督的聚类方法,SOM与K-Means有什么不同呢?
(1)K-Means需要事先定下类的个数,也就是K的值。 SOM则不用,隐藏层中的某些节点可以没有任何输入数据属于它。所以,K-Means受初始化的影响要比较大。
(2)K-means为每个输入数据找到一个最相似的类后,只更新这个类的参数。SOM则会更新临近的节点。所以K-mean受noise data的影响比较大,SOM的准确性可能会比k-means低(因为也更新了临近节点)。
(3) SOM的可视化比较好。优雅的拓扑关系图 。
参考文献:http://www.cs.bham.ac.uk/~jxb/NN/l16.pdf
Self Organizing Maps (SOM): 一种基于神经网络的聚类算法的更多相关文章
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- 【机器学习】DBSCAN Algorithms基于密度的聚类算法
一.算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层 ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- 基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级.例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 基于ReliefF和K-means算法的医学应用实例
基于ReliefF和K-means算法的医学应用实例 数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据 ...
- 一种新型聚类算法(Clustering by fast search and find of density peaksd)
最近在学习论文的时候发现了在science上发表的关于新型的基于密度的聚类算法 Kmean算法有很多不足的地方,比如k值的确定,初始结点选择,而且还不能检测费球面类别的数据分布,对于第二个问题,提出了 ...
- 数据挖掘案例:基于 ReliefF和K-means算法的应用
数据挖掘案例:基于 ReliefF和K-means算法的应用 数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘(DataMiriing),指的是从大型数据库 ...
随机推荐
- 《SQL Server企业级平台管理实践》读书笔记——关于SQL Server数据库的还原方式
本篇是继上篇的备份方式,本篇介绍的是还原方案,在SQL Server在2005以上现有的还原方案一般分为以下4个级别的数据还原: 1.数据库完整还原级别: 还原和恢复整个数据库.数据库在还原和恢复操作 ...
- MongoDB(一)
问题解决 1.由于目标计算机积极拒绝 无法连接 原因:还没有启动mongodb,就使用mongo命令 解决方法:在bin目录下输入 mongod --dbpath XXXX/data 然后在输入 mo ...
- fis自动化部署
1,自动部署到远程服务器 (1),参考:https://github.com/fex-team/receiver (2),接收服务代码目录:/var/www/html/fis/receiver-mas ...
- 编译时:virtual memory exhausted: Cannot allocate memory
一.问题 当安装虚拟机时系统时没有设置swap大小或设置内存太小,编译程序会出现virtual memory exhausted: Cannot allocate memory的问题,可以用swap扩 ...
- 第八篇 :微信公众平台开发实战Java版之如何网页授权获取用户基本信息
第一部分:微信授权获取基本信息的介绍 我们首先来看看官方的文档怎么说: 如果用户在微信客户端中访问第三方网页,公众号可以通过微信网页授权机制,来获取用户基本信息,进而实现业务逻辑. 关于网页授权回调域 ...
- Android中手机号、车牌号正则表达式
手机号 手机号的号段说明转载自:国内手机号码的正则表达式|蜗牛的积累 手机名称有GSM:表示只支持中国联通或者中国移动2G号段(130.131.132.134.135.136.137.138.139. ...
- linux内核宏container_of前期准备之gcc扩展关键字typeof
typeof基本介绍 typeof(x) 这是它的使用方法,x可以是数据类型或者表达式.它的作用时期和sizeof类似,就是它是在编译器从高级语言(如C语言)翻译成汇编语言时起作用,这个很重要,稍后会 ...
- Combine small files to Sequence file
Combine small files to sequence file or avro files are a good method to feed hadoop. Small files in ...
- SSAS CUBE TEST CASES
经过周末两天和今天的努力,基本上完成并修复了一些bug并且集成到我的MSBIHelper项目中去,可以进行数据测试了.效果图如下: 可以帮助开发人员快速生成等值的Tsql和mdx查询,辅助测试人员快速 ...
- NOIP2008提高组火柴棒等式(模拟)——yhx
题目描述 给你n根火柴棍,你可以拼出多少个形如“A+B=C”的等式?等式中的A.B.C是用火柴棍拼出的整数(若该数非零,则最高位不能是0).用火柴棍拼数字0-9的拼法如图所示: 注意: 加号与等号各自 ...