Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎。
概要
上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅。本篇讲述如何使用intellij idea来跟踪调试spark源码。
前提
本文假设开发环境是在Linux平台,并且已经安装下列软件,我个人使用的是arch linux。
- jdk
- scala
- sbt
- intellij-idea-community-edition
安装scala插件
为idea安装scala插件,具体步骤如下
- 选择File->Setting
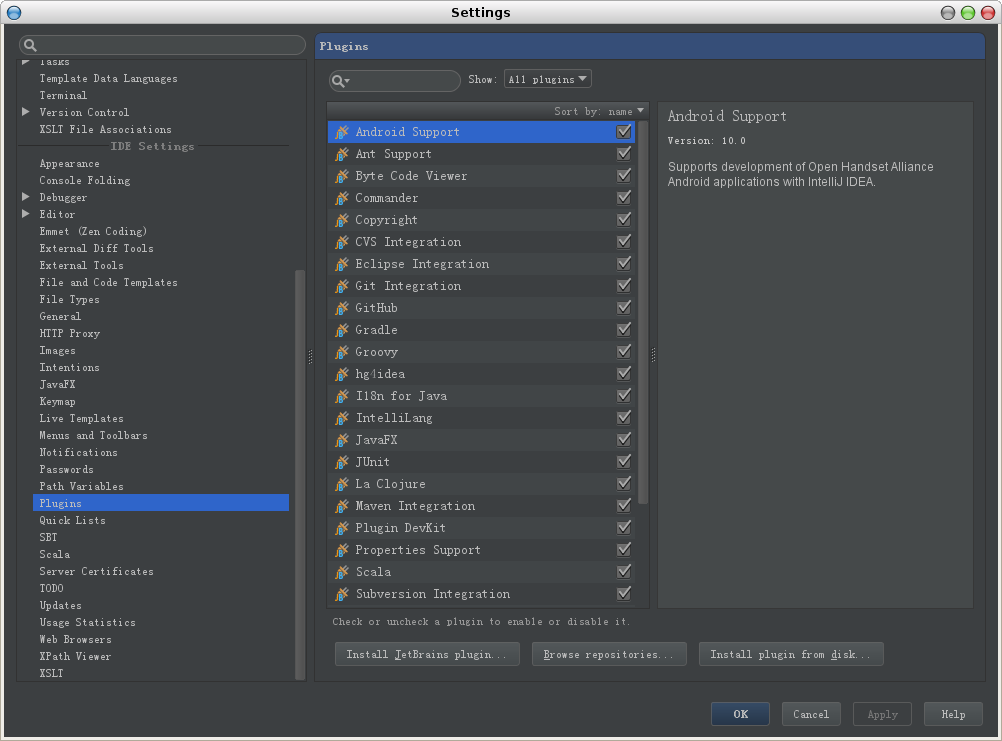
2 步骤2: 选择右侧的Install Jetbrains Plugin,在弹出窗口的左侧输入scala,然后点击安装,如下图所示
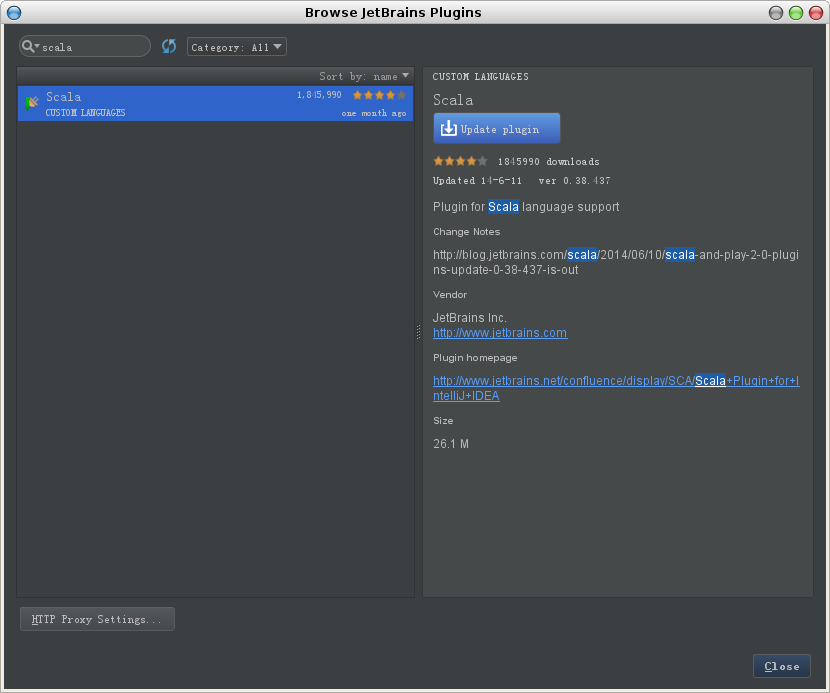
3. scala插件安装结束,需要重启idea生效
由于idea 13已经原生支持sbt,所以无须为idea安装sbt插件。
源码下载和导入
下载源码,假设使用git同步最新的源码
git clone https://github.com/apache/spark.git
导入Spark源码
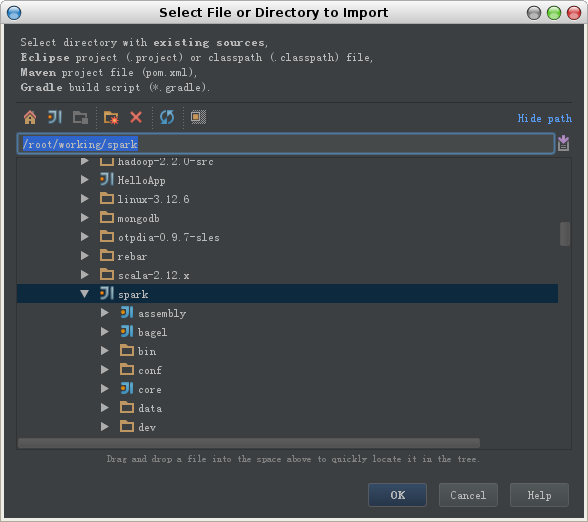
1. 选择File->Import Project, 在弹出的窗口中指定spark源码目录
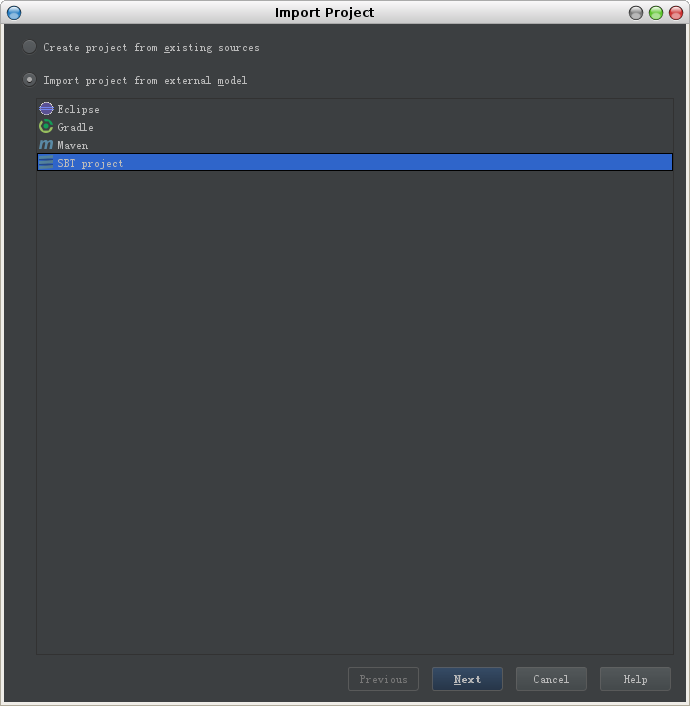
2. 选择项目类型为sbt project,然后点击next
3. 在新弹出的窗口中先选中"Use auto-import",然后点击Finish

导入设置完成,进入漫长的等待,idea会对导入的源码进行编译,同时会生成文件索引。
如果在提示栏出现如下的提示内容"is waiting for .sbt.ivy.lock",说明该lock文件无法创建,需要手工删除,具体操作如下
cd $HOME/.ivy2
rm *.lock
手工删除掉lock之后,重启idea,重启后会继续上次没有完成的sbt过程。
源码编译
使用idea来编译spark源码,中间会有多次出错,问题的根源是sbt/sbt gen-idea的时候并没有很好的解决依赖关系。
解决办法如下,
1. 选择File->Project Structures
2. 在右侧dependencies中添加新的module,

选择spark-core
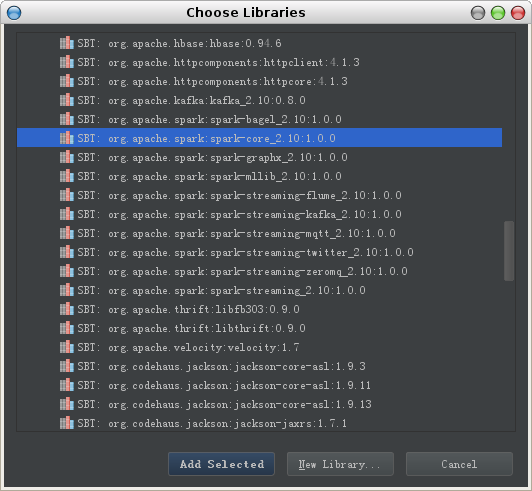
其它模块如streaming-twitter, streaming-kafka, streaming-flume, streaming-mqtt出错的情况解决方案与此类似。
注意Example编译报错时的处理稍有不同,在指定Dependencies的时候,不是选择Library而是选择Module dependency,在弹出的窗口中选择sql.
有关编译出错问题的解决可以看一下这个链接,http://apache-spark-user-list.1001560.n3.nabble.com/Errors-occurred-while-compiling-module-spark-streaming-zeromq-IntelliJ-IDEA-13-0-2-td1282.html
调试LogQuery
1. 选择Run->Edit configurations
2. 添加Application,注意右侧窗口中配置项内容的填写,分别为Main class, vm options, working directory, use classpath of module
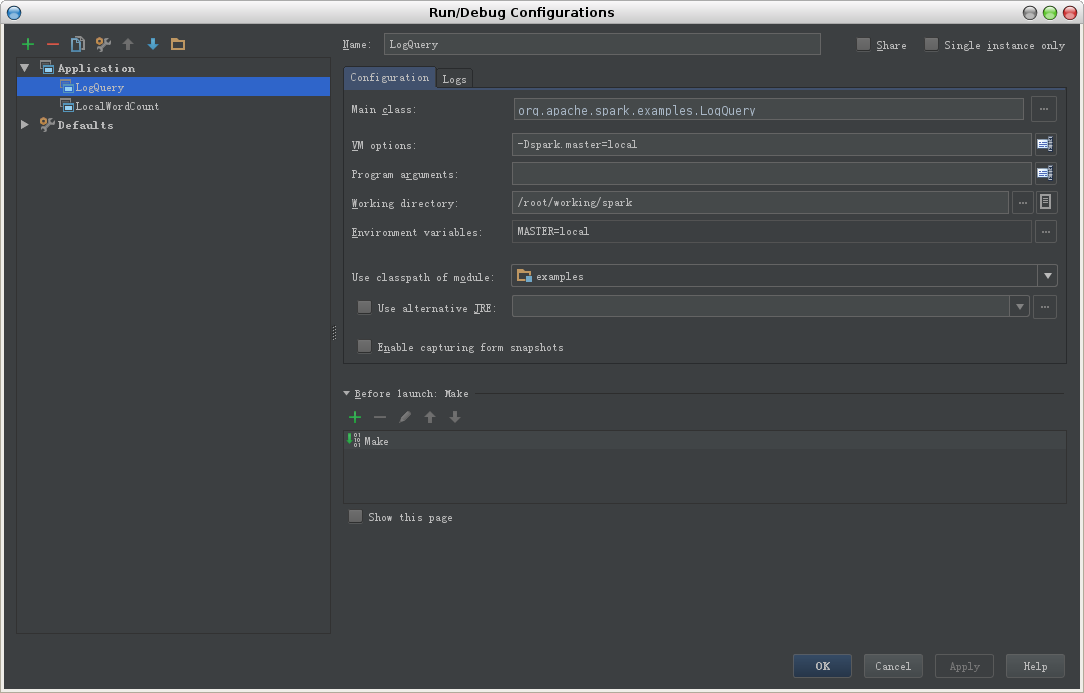
-Dspark.master=local 指定Spark的运行模式,可根据需要作适当修改。
3. 至此,在Run菜单中可以发现有"Run LogQuery"一项存在,尝试运行,保证编译成功。
4. 断点设置,在源文件的左侧双击即可打上断点标记,然后点击Run->"Debug LogQuery", 大功告成,如下图所示,可以查看变量和调用堆栈了。

参考
Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码的更多相关文章
- Maven 依赖调解源码解析(二):如何调试 Maven 源码和插件源码
本文是系列文章<Maven 源码解析:依赖调解是如何实现的?>第二篇,主要介绍如何调试 Maven 源码和插件源码.系列文章总目录参见:https://www.cnblogs.com/xi ...
- spark学习10(win下利用Intellij IDEA搭建spark开发环境)
第一步:启动IntelliJ IDEA,选择Create New Project,然后选择Scala,点击下一步,输入项目名称wujiadong.spark继续下一步 第二步:导入spark-asse ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Linux+eclipse+gdb调试postgresql源码
pg内核源码解析课上用的vs调试pg源码, VS用起来确实方便,但是配置调试环境着实有点麻烦.首先得装个windows系统,最好是xp,win7稍微麻烦点:最好使用vs05,08和10也可以,但是比0 ...
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Apache Spark源码走读之2 -- Job的提交与运行
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文以wordCount为例,详细说明spark创建和运行job的过程,重点是在进程及线程的创建. 实验环境搭建 在进行后续操作前,确保下列条件已满足. 下 ...
随机推荐
- struts2的s:iterator 标签 详解
s:iterator 标签有3个属性:value:被迭代的集合id :指定集合里面的元素的idstatus 迭代元素的索引1:jsp页面定义元素写法 数组或list <s:iterator ...
- WebRTC源码分析四:视频模块结构
转自:http://blog.csdn.net/neustar1/article/details/19492113 本文在上篇的基础上介绍WebRTC视频部分的模块结构,以进一步了解其实现框架,只有了 ...
- JAVA 获取web文件的相对路径
转自:http://wwwdd2315.blog.163.com/blog/static/66661889201091953350298/ 在JAVA文件中获取该项目的相对路径1.基本概念的理解 绝对 ...
- struts2的标签中得到JSP脚本的变量值
转自:http://www.cnblogs.com/modou/articles/1299024.html 大家先来看一段代码: <% int i=1; %> <s:property ...
- 继承ActionSupport,返回INPUT的原因
http://developer.51cto.com/art/200907/134757.htm 表面现象: 在WebWork中,当一个Action中既没有重写ActionSupport中的valid ...
- Adapter适配器
1.概念 *连接后端数据和前端显示的适配器接口 *数据和UI之间的重要连接 2. ArrayAdapter ArrayAdapter构造器如下: ArrayAdapter(Context con ...
- 浅析C#中的Attribute(转)
最近用到了,所以静下心来找些资料看了一下,终于把这东西搞清楚了. 一.什么是Attribute 先看下面的三段代码: 1.自定义Attribute类:VersionAttribute [Attribu ...
- 微信公众账号开发之微信登陆Oauth授权-第一篇
我曾经在2012年的时候开始研究微信,那时微信的版本还是处于1.0,当时给朋友帮忙做一个基于微信端的web应用,官方的文档是相当少的,百度搜索出来的东西基本也没有多少实用价值,不过是在官网的基础上作了 ...
- cocos2d 创建精灵图
// 在init这个函数当中做一些初始化的事情 bool HelloWorld::init() { ////////////////////////////// // 先构造父级对象 if ( !CC ...
- Codeforces 176B (线性DP+字符串)
题目链接: http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=28214 题目大意:源串有如下变形:每次将串切为两半,位置颠倒形成 ...