Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎。
概要
本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读。
拟牛顿法
数学原理









代码实现
L-BFGS算法中使用到的正则化方法是SquaredL2Updater。
算法实现上使用到了由scalanlp的成员项目breeze库中的BreezeLBFGS函数,mllib中自定义了BreezeLBFGS所需要的DiffFunctions.
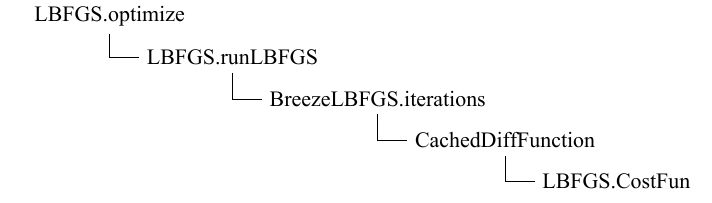
runLBFGS函数的源码实现如下
def runLBFGS(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
numCorrections: Int,
convergenceTol: Double,
maxNumIterations: Int,
regParam: Double,
initialWeights: Vector): (Vector, Array[Double]) = {
val lossHistory = new ArrayBuffer[Double](maxNumIterations)
val numExamples = data.count()
val costFun =
new CostFun(data, gradient, updater, regParam, numExamples)
val lbfgs = new BreezeLBFGS[BDV[Double]](maxNumIterations, numCorrections, convergenceTol)
val states =
lbfgs.iterations(new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector)
/**
* NOTE: lossSum and loss is computed using the weights from the previous iteration
* and regVal is the regularization value computed in the previous iteration as well.
*/
var state = states.next()
while(states.hasNext) {
lossHistory.append(state.value)
state = states.next()
}
lossHistory.append(state.value)
val weights = Vectors.fromBreeze(state.x)
logInfo("LBFGS.runLBFGS finished. Last 10 losses %s".format(
lossHistory.takeRight(10).mkString(", ")))
(weights, lossHistory.toArray)
}
costFun函数是算法实现中的重点
private class CostFun(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
regParam: Double,
numExamples: Long) extends DiffFunction[BDV[Double]] {
private var i = 0
override def calculate(weights: BDV[Double]) = {
// Have a local copy to avoid the serialization of CostFun object which is not serializable.
val localData = data
val localGradient = gradient
val (gradientSum, lossSum) = localData.aggregate((BDV.zeros[Double](weights.size), 0.0))(
seqOp = (c, v) => (c, v) match { case ((grad, loss), (label, features)) =>
val l = localGradient.compute(
features, label, Vectors.fromBreeze(weights), Vectors.fromBreeze(grad))
(grad, loss + l)
},
combOp = (c1, c2) => (c1, c2) match { case ((grad1, loss1), (grad2, loss2)) =>
(grad1 += grad2, loss1 + loss2)
})
/**
* regVal is sum of weight squares if it's L2 updater;
* for other updater, the same logic is followed.
*/
val regVal = updater.compute(
Vectors.fromBreeze(weights),
Vectors.dense(new Array[Double](weights.size)), 0, 1, regParam)._2
val loss = lossSum / numExamples + regVal
/**
* It will return the gradient part of regularization using updater.
*
* Given the input parameters, the updater basically does the following,
*
* w' = w - thisIterStepSize * (gradient + regGradient(w))
* Note that regGradient is function of w
*
* If we set gradient = 0, thisIterStepSize = 1, then
*
* regGradient(w) = w - w'
*
* TODO: We need to clean it up by separating the logic of regularization out
* from updater to regularizer.
*/
// The following gradientTotal is actually the regularization part of gradient.
// Will add the gradientSum computed from the data with weights in the next step.
val gradientTotal = weights - updater.compute(
Vectors.fromBreeze(weights),
Vectors.dense(new Array[Double](weights.size)), 1, 1, regParam)._1.toBreeze
// gradientTotal = gradientSum / numExamples + gradientTotal
axpy(1.0 / numExamples, gradientSum, gradientTotal)
i += 1
(loss, gradientTotal)
}
}
}
Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现的更多相关文章
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- Apache Spark源码走读之1 -- Spark论文阅读笔记
欢迎转载,转载请注明出处,徽沪一郎. 楔子 源码阅读是一件非常容易的事,也是一件非常难的事.容易的是代码就在那里,一打开就可以看到.难的是要通过代码明白作者当初为什么要这样设计,设计之初要解决的主要问 ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读. 线性回归模型 ...
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
随机推荐
- wpf 触发器,属性触发器,事件触发器,事件触发器。
<EventTrigger RoutedEvent="Mouse.MouseEnter"/> <DataTrigger Binding="{Bindin ...
- 【bzoj2440】【bzoj3994】莫比乌斯反演学习
哇..原来莫比乌斯代码这么短..顿时感觉逼格-- 写了这道题以后,才稍稍对莫比乌斯函数理解了一些 定理:和是定义在非负整数集合上的两个函数,并且满足条件,那么我们得到结论 在上面的公式中有一个函数,它 ...
- PL/SQL 循环结构
(1)LOOP...EXIT...END语句示例: control_var:; LOOP then EXIT; END IF; control_var:; END LOOP; 上述,初始化contro ...
- BZOJ3414 : Poi2013 Inspector
二分答案,没有出现过的时刻没有用,可以进行离散化. 首先如果某个时刻出现多个人数,那么肯定矛盾. 然后按时间依次考虑,维护: $t$:剩余可选人数. $s$:现在必定有的人数. $cl$:往左延伸的人 ...
- 图解Storm
问题导读:1.你认为什么图形可以显示hadoop与storm的区别?(电梯)2.本文是如何形象讲解hadoop与storm的?(离线批量处理.实时流式处理)3.hadoop map/reduce对应s ...
- 关于scrollbar-face-color只支持ie的解决办法!
关于scrollbar-face-color只支持ie的解决方法!!今天突然有人问我滚动条css自定义的方法,我发现用scrollbar-base-color这种方法只有ie支持,查了半天资料总结如下 ...
- 如何伪装成为一名前端(JS方向)
作为一个菜鸟级别的.NET开发者,在连服务器都没搞定的情况下,要研究前端,这是在扯淡,不过,迫于工作的需要,时常需要去前端打杂,所以经常伪装成为一名前端,有时候竟产生错觉,去应聘Y一份前端work吧. ...
- BZOJ 1015 题解
1015: [JSOI2008]星球大战starwar Description 很久以前,在一个遥远的星系,一个黑暗的帝国靠着它的超级武器统治者整个星系.某一天,凭着一个偶然的机遇,一支反抗军摧毁了帝 ...
- [BZOJ2803][Poi2012]Prefixuffix
2803: [Poi2012]Prefixuffix Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 219 Solved: 95[Submit][St ...
- Codeforces Beta Round #6 (Div. 2 Only)
A,B,C都是水题... D题,直接爆搜.我换了好多姿势,其实最简单的方法,就能过. #include <cstdio> #include <string> #include ...