hadoop之快照
在hadoop第前几个版本中是没有快照功能的,2.x中是有这个特性的
Hadoop 2.x HDFS新特性
HDFS快照
HDFS快照
在2.x终于实现了快照
设置一个目录为可快照:
hdfs dfsadmin -allowSnapshot <path>
取消目录可快照:
hdfs dfsadmin -disallowSnapshot <path>
生成快照:
hdfs dfs -createSnapshot <path> [<snapshotName>]
删除快照:
hdfs dfs -deleteSnapshot <path> <snapshotName>
快照位置
可快照目录下的.snapshot子目录
其它快照操作
列出所有可快照目录:
hdfs lsSnapshottableDir
比较快照之间的差异:
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
详细查考这个:http://www.cnblogs.com/nucdy/p/5684139.html
Hdfs的快照原理
Hdfs的快照(snapshot)是在某一时间点对指定文件系统拷贝,快照采用只读模式,可以对重要数据进行恢复、防止用户错误性的操作。
快照分两种:
一种是:建立文件系统的索引,每次更新文件不会真正的改变文件,而是新开辟一个空间用来保存更改的文件,
一种是:拷贝所有的文件系统。Hdfs属于前者。 Hdfs的快照的特征如下:
1. 快照的创建是瞬间的,代价为O(1),取决于子节点扫描文件目录的时间。
2. 当且仅当做快照的文件目录下有文件更新时才会占用小部分内存,占用内存的大小为
O(M),其中M为更改文件或者目录的数量;
3. 新建快照的时候,Datanode中的block不会被复制,快照中只是记录了文件块的列表和
大小信息。
4. 快照不会影响正常的hdfs的操作。对做快照之后的数据进行的更改将会按照时间顺序逆
序的记录下来,用户访问的还是当前最新的数据,快照里的内容为快照创建的时间点时文件的内容减去当前文件的内容。
每个快照最高限额为65536个文件或者文件夹,在快照的子文件夹中不允许在创建新的快照。
注意,mv命令和del命令是不允许的,因为快照是只读的
来源:http://wenku.baidu.com/link?url=Yy16EN-wHlyfiF4A4f9DYnxUlKyr-AuUBGwtIS-bu4FcvbIs_QNeWPD17eoUm72YW8TXv4p_V4g5V1i9D1IyZbmfM8qwyOva2W5qLEY3znO
hadoop snapshots 快照
HDFS 快照是文件系一个时间点的只读的副本。快照可以是部分文件系统,或者整个文件系统。一些场景使用快照的场景是数据备份,防止用户误操作和灾难恢复。
使用HDFS 快照是高效的:
- 快照创建是瞬间的:成本是0(1)排除查找信息节点的时间 。
- 额外的内存使用仅仅当对快照进行修改时产生:内存使用时0(M),M是修改文件/目录的数量。
- 在datanode中的块不会被拷贝:快照文件记录这些块列表和文件大小。不会产生数据拷贝。
- 快照不会对日常的HDFS操作产生不利的影响:修改被按反向时间排序记录,这样当前数据可以直接的访问。快照数据是由当前数据减去修改数据计算出来的(t.dbdao.com)。
1.1 snapshottable目录
快照可以产生在任何被设置为snapshottable的目录中。一个snapshottable目录可以同时容纳65536个快照。snapshottable目录没有个数上限,管理员可以设置任意个snapshottable。如果一个snapshottable中存在快照,那么这个目录在删除所有快照之前,不能删除或改名。
嵌套的snapshottable目录在现在并不支持(日期:2015-11-02)。换句话说,如果一个目录的父目录/子目录是一个snapshottable目录的话,那么其不能设置为snapshottable。
1.2 快照 路径
对于一个snapshottable目录,”.snapshot”组件有利于访问其快照。假设/foo是一个snapshottable目录,/foo/bar是 /foo中的一个文件/目录,/foo有一个快照s0,那么这个路径
/foo/.snapshot/s0/bar
/foo/.snapshot/s0/bar
列出一个snapshottable目录中所有的快照:关联到快照副本/foo/bar。一般的API和CLI都可以在”.snapshot”路径上工作。下面是一些例子
Shell
hdfs dfs -ls /foo/.snapshot
hdfs dfs-ls/foo/.snapshot
- 列出在快照s0中的文件:
Shell
hdfs dfs -ls /foo/.snapshot/s0
hdfs dfs-ls/foo/.snapshot/s0
- 从快照s0中拷贝文件:
Shell
hdfs dfs -cp -ptopax /foo/.snapshot/s0/bar /tmp
hdfs dfs-cp-ptopax/foo/.snapshot/s0/bar/tmp
注意这个例子使用了保存选项来保存时间戳,所有权,权限,ACLS和XAttrs
2 在有快照的时候升级HDFS版本
HDFS快照特性引用了一个新的保留路径名,来进行快照交互:.snapshot。当HDFS从一个旧版本升级时,现存的路径名称.snapshot需要首先重命名或者删除,来避免保留路径的冲突。更多详细类容,参考HDFS用户指南升级部分(t.dbdao.com)。
3快照操作
3.1管理员操作
本节中描述的操作需要超级用户权限
允许快照
允许一个快照目录被创建。如果这个操作成功完成,这个目录就变成snapshottable
- 命令:
Shell
hdfs dfsadmin -allowSnapshot <path>
hdfs dfsadmin-allowSnapshot<path>
- 参数:
path snapshottable目录的路径
禁止快照
禁止快照目录创建。在静止快照之前目录中的所有快照必须删除。
- 命令:
Shell
hdfs dfsadmin -disallowSnapshot <path>
hdfs dfsadmin-disallowSnapshot<path>
- 参数
path snapshottable目录的路径
也可以参考Hdfsadmin中相关JAVA API void disallowSnapshot(Path path)
3.2 用户操作
本节介绍用户操作。注意HDFS超级用户,可以执行除了个人操作需要满足的安全权限之外的所有操作(t.dbdao.com)。
创建快照
在snapshottable目录中创建一个一个快照。这个操作需要拥有snapshottabl目录所有者权限。
- 命令
Shell
hdfs dfs -createSnapshot <path> [<snapshotName>]
hdfs dfs-createSnapshot<path>[<snapshotName>]
- 参数:
| path | snapshottable目录的路径 |
| snapshotName | 快照的名称,是一个可选参数。当其省略时,默认的名称是使用时间戳”s’yyyyMMdd-HHmmss.SSSS”的格式,例如”s20130412-151029.033″ |
也可以参考文件系统中相关JAVA API Path createSanpshot(Path path)和Path createSnapshot(Path path,String snapshotName)。在这些方法中返回了快照路径。
删除快照
从一个snapshottable目录中删除快照。这个操作需要拥有snapshottabl目录所有者权限(t.dbdao.com)。
- 命令
Shell
hdfs dfs -deleteSnapshot <path> <snapshotName>
hdfs dfs-deleteSnapshot<path><snapshotName>
- 参数:
| path | snapshottable目录的路径 |
| snapshotName | 快照名称 |
重命名快照
重命名一个快照。这个操作需要拥有snapshottabl目录所有者权限。
- 命令:
Shell
hdfs dfs -renameSnapshot <path> <oldName> <newName>
hdfs dfs-renameSnapshot<path><oldName><newName>
- 参数:
| path | snapshottable目录的路径 |
| oldName | 旧的快照名 |
| newName | 新的快照名 |
也可以参考文件系统中相关JAVA API void renameSnapshot(Path path, String oldName, String newName)
获得snapshottable目录列表
获得当前用户有权限产生快照的所有snapshottabl目录
- 命令:
Shell
hdfs lsSnapshottableDir
hdfs lsSnapshottableDir
- 参数:无
也可以参考分布式文件系统中相关JAVA API SnapshottableDirectoryStatus[] getSnapshottableDirectoryListing()
获得 快照差异报告
在2个快照之间获得差异。这个操作需要在2个快照中,所有文件/目录的读和访问权限(t.dbdao.com)。
- 命令:
Shell
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
hdfs snapshotDiff<path><fromSnapshot><toSnapshot>
- 参数:
| path | snapshottable目录的路径 |
| fromSnapshot | 开始快照的名称 |
| toSnapshot | 结束快照的名称 |
- 结果:
| + | 文件/目录 被创建 |
| _ | 文件/目录 被删除 |
| M | 文件/目录 被修改 |
| R | 文件/目录 被重命名 |
一个RENAME提示一个文件/目录被重命名,但是仍然存在相同的snapshottabl目录中。如果一个文件/目录被重命名到snapshottabl目录外,那么会打印为删除。从snapshottabl目录之外重命名进来的文件/目录,被打印为新创建。
快照差异报告不能保证相同操作的顺序。例如,如果我们将目录”/foo”重命名为”/foo2″,然后增加一个新文件为”/foo2/bar”,这个差异报告将是:
R. /foo -> /foo2
M. /foo/bar
R./foo->/foo2
M./foo/bar
即,在一个目录重命名下的文件/目录 变更,在报告的时候,是使用原来未重命名之前的名称。(例如上面的”/foo/bar”)
也可以参考分布式文件系统中相关JAVA API SnapshotDiffReport getSnapshotDiffReport(Path path, String fromSnapshot, String toSnapshot)
Hbase的基于快照的表修复
Hdfs的快照同样适用于hbase表的恢复。在hbase的数据表目录/hbase/data/default/(default为默认namespace空间)中新建快照,就会在该目录下生成.snapshot的文件夹,里面放着针对该目录的所有快照。

如果存在用户误删hbase表
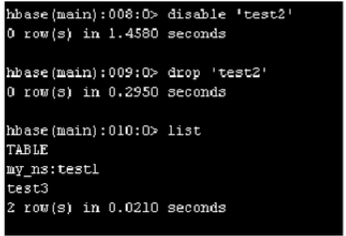
将快照中保存的数据表文件夹cp到/hbase/data/default下,然后执行如下命令,修复元数据即可。

注意,cp到/hbase/data/default目录下的数据表文件夹的权限要修改成hbase:hbase。 否则修改元数据的命令会失败。

上面是对整个hbase的namespace空间进行的快照备份,如果在某一个表目录下建快照,那么这个表目录就会变成只读,在hbase shell中执行disable+drop <tablename>不会将表删除,在建快照之后新增的表数据也不会丢失。
虽然数据不会丢失但是元数据会被drop命令删除,还得用repair命令进行修复。

修复完之后,再enable这个表,就ok了。
source: http://www.thebigdata.cn/Hadoop/15618.html
另外练习的可以到这个网址:
hadoop snapshots 快照实验
hadoop之快照的更多相关文章
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- hadoop2.x HDFS快照介绍
说明:由于近期正好在研究hadoop的快照机制.看官网上的文档讲的非常仔细.就顺手翻译了.也没有去深究一些名词的标准译法,所以可能有些翻译和使用方法不是非常正确,莫要介意~~ 原文地址:(Apache ...
- Hadoop介绍篇
Hadoop详解 1.前言 对于初次接触Hadoop的小伙伴来说,Hadoop是一个很陌生的东西,尤其是Hadoop与大数据之间的关联,写这篇文章之前,我也有许多关于Hadoop与大数据的疑惑,接下来 ...
- Hadoop的多节点集群启动,唯独没有namenode进程?(血淋淋教训,一定拍快照)(四十五)
前言 大家在搭建hadoop集群时,第一次格式化后,一路要做好快照.别随便动不动缺少什么进程,就来个格式化. 问题描述:启动hadoop时报namenode未初始化:java.io.IOExcepti ...
- Apache Hadoop 2.9.2 的快照管理
Apache Hadoop 2.9.2 的快照管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 快照相当于对目录做一个备份.并不会立即复制所有文件,而是指向同一个文件.当写入发生 ...
- Hadoop基础-Hadoop快照管理
Hadoop基础-Hadoop快照管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.快照的作用 快照可以迅速对文件(夹)进行备份,不产生新文件,使用差值存储,默认是禁用状态. ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink--容错机制(ACK,RDD,基于log和状态快照),消息处理at least once,exactly once两个是关键
分布式流处理是对无边界数据集进行连续不断的处理.聚合和分析.它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别.这类系统一般采用有向无环图(DAG). DAG是任务链的图形化表示 ...
- hadoop快照管理
快照相当于对目录做备份,并不会复制所有文件,而是记录文件的变化命令用法 ()hdfs dfsadmin -allowSnapshot 路径 (开启指定目录的快照功能) ()hdfs dfsadmin ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
随机推荐
- SGU 275 To xor or not to xor
time limit per test: 0.25 sec. memory limit per test: 65536 KB input: standard output: standard The ...
- JBoss7.1配置外网访问
在JBoss7.1目录jboss-as-7.1.1.Final/standalone/configuration下找到standalone.xml,找到以下的节点,在尝试了以下两种方法: 1. < ...
- 自动打包iOS项目
基于Lexrus的博文iOS-makefile,本文对自动打包涉及到的操作步骤以及理论基础进行了适当的补充. 请在阅读本文前先阅读<iOS makefile>.文章地址:http: ...
- easyui form submit 不提交
http://bbs.csdn.net/topics/390811964 function saveProduct() { //$('#fm').form('submit', ...
- 清除TFS版本控制信息
http://blog.csdn.net/feihu_guest/article/details/8442434 How to permanently remove TFS Source Contro ...
- jdk版本
windows: set java_home:查看JDK安装路径 java -version:查看JDK版本 linux: whereis java which java (java执行路径) ech ...
- Java中各种(类、方法、属性)访问修饰符与修饰符的说明
类: 访问修饰符 修饰符 class 类名称 extends 父类名称 implement 接口名称 (访问修饰符与修饰符的位置可以互换) 访问修饰符 名称 说明 备注 public 可以被本项目的所 ...
- alert对ajax阻塞调查(IE, Chrome, FF)
前阵子做保守工作,对一个js效果进行了改进,由于自己在chrome下测试没问题就丢给同事测试,同事用的是FF,发现不正常,后来又发现这个js在IE10下也不行,不得不调查,结果发现Chrome的ale ...
- UrlConnection连接和Socket连接的区别
关于UrlConnection连接和Socket连接的区别,只知道其中的原理如下: 抽象一点的说,Socket只是一个供上层调用的抽象接口,隐躲了传输层协议的细节. urlconnection 基于H ...
- MVC中使用WebMail 发送注册验证信息
在MVC中发送Email 可以使用WebMail :使用起来十分简单.如下: WebMail.SmtpServer = ConfigurationHelper.GetValue("SmtpS ...