爬虫技术 -- 进阶学习(九)使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
菜鸟HtmlAgilityPack初体验。。。弱弱的代码。。。
Html Agility Pack是一个开源项目,为网页提供了标准的DOM API和XPath导航。使用WebBrowser和HttpWebRequest下载的网页可以用Html Agility Pack来解析。
HtmlAgilityPack的文档是CHM格式的,有时会无法正常阅读CHM格式的文件。如果是IE不能链接到您请求的网页或者打开后“页面无法显示”。请在要打开的CHM文件上右击属性,会在底下属性多了个“解除锁定”,单击后就可以正常显示了。
如果有需要下载,请点击HtmlAgilityPack.1.4.0下载,解压后找到HtmlAgilityPack.dll,把它添加到项目中。
HtmlAgilityPack.dll中的类都位于HtmlAgilityPack命名空间。
HtmlDocument表示一个完整的HTML文档。用Load方法加载网页。
下面进行HtmlAgilityPack初体验,
实现目标:,点击按钮后,根据给定的网址,打印出该页面的所有链接。简单代码如下:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using HtmlAgilityPack; namespace HtmlAgilityPackDemo1
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
} private void Form1_Load(object sender, EventArgs e)
{ } private void button1_Click(object sender, EventArgs e)
{
HtmlWeb webClient = new HtmlWeb();
HtmlAgilityPack.HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei"); HtmlNodeCollection hrefList = doc.DocumentNode.SelectNodes(".//a[@href]"); if (hrefList != null)
{
foreach (HtmlNode href in hrefList)
{
HtmlAttribute att = href.Attributes["href"];
Console.WriteLine(att.Value); } } }
}
}
当上面第28行代码写成如下,
HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei");
会出现错误提示,

于是修改如下,
HtmlAgilityPack.HtmlDocument doc = webClient.Load("http://www.cnblogs.com/lmei");
接下来,看下控制台的输出,截图如下:

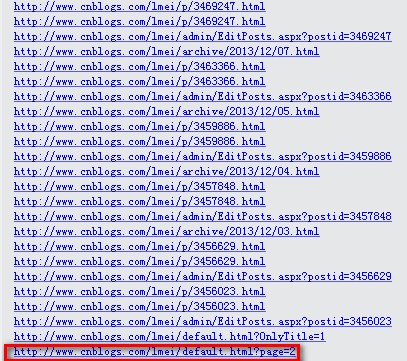
可见,网页上面的超链接都被打印出来了。。。
当然,如果想要抓取的是网页上面的正文,加载后可能出现乱码问题,则可以指定文件的编码:
HtmlAgilityPack.HtmlDocument htmlDoc = new HtmlAgilityPack.HtmlDocument();
Encoding encoder = Encoding.GetEncoding("utf-8");
htmlDoc.Load("http://www.cnblogs.com/lmei/p/3485649.html", encoder);
爬虫技术 -- 进阶学习(九)使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)的更多相关文章
- 爬虫技术(六)-- 使用HtmlAgilityPack获取页面链接(附c#代码及插件下载)
菜鸟HtmlAgilityPack初体验...弱弱的代码... Html Agility Pack是一个开源项目,为网页提供了标准的DOM API和XPath导航.使用WebBrowser和HttpW ...
- 爬虫技术 -- 基础学习(一)HTML规范化(附特殊字符编码表)
最近在做网页信息提取这方面的,由于没接触过这系列的知识点,所以逛博客,看文档~~看着finallyly大神的博文和文档,边看边学习边总结~~ 对网站页面进行信息提取,需要进行页面解析,解析的方法有以下 ...
- 爬虫技术 -- 进阶学习(十)网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决定试一试~ 于是到https://www.nuget.org/packages/Scrapy ...
- 爬虫技术 -- 进阶学习(十一)【补充】获取html中meta标签中的content的内容
上一篇网易新闻页面信息抓取 -- htmlagilitypack搭配scrapysharp中提及了很多如何快速抓取html中的文本的语句, 但是meta标签中的content内容的抓取,没有提及到! ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术 -- 进阶学习(八)模拟简单浏览器(附c#代码)
由于最近在做毕业设计,需要用到一些简单的浏览器功能,于是学习了一下,顺便写篇博客~~大牛请勿喷,菜鸟练练手~ 实现界面如下:(简单朴素版@_@||) button_go实现如下: private vo ...
- 爬虫技术 -- 基础学习(五)解决页面编码识别(附c#代码)
实现从Web网页提取文本之前,首先要识别网页的编码,有时候还需要进一步识别网页所使用的语言.因为同一种编码可能对应多种语言,例如UTF-8编码可能对应英文或中文等语言. 识别编码整体流程如下: (1) ...
- 爬虫技术 -- 基础学习(四)HtmlParser基本认识
利用爬虫技术获取网页源代码后,针对网页抽取出它的特定文本内容,利用正则表达式和抽取工具,能够更好地抽取这些内容. 下面介绍一种抽取工具 -- HtmlParser HtmlParser是一个用来解析H ...
- jQuery基础学习5——JavaScript方法获取页面中的元素
给网页中的所有<p>元素添加onclick事件 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN& ...
随机推荐
- Liferay7 BPM门户开发之30: 通用帮助类Validator、ArrayUtil、StringUtil等使用
废话不多说,直接上代码. 验证类Validator 主要是空验证.数字.格式验证 调用的例子: protected void validateEmailFrom(ActionRequest actio ...
- Linux 下Shell 脚本几种基本命令替换区别
Shell 脚本几种基本命令替换区别 前言:因为工作需要,需要编写 shell script .编写大量 shell script 时,累计了大量经验,也让自己开始迷糊几种函数输出调用的区别.后面和 ...
- Leetcode-237 Delete Node in a Linked List
#237. Delete Node in a Linked List Write a function to delete a node (except the tail) in a singl ...
- MAT(Memory Analyzer Tool)工具入门介绍(转)
1.MAT是什么? MAT(Memory Analyzer Tool),一个基于Eclipse的内存分析工具,是一个快速.功能丰富的JAVA heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗 ...
- c#之第二课
输出语句: /////////////////////////////// public class Hello1 { public static void Main() { System.Conso ...
- 网页二维码推广App的实现
移动互联网时代,一个APP的平均推广成本早已经超过了10块.而推广通常分二类: 1.已经下载过的用户,可以直接打开应用(一般人的手机上安装的应用都非常多,要快速找到某个应用是很困难的事情,而且Andr ...
- solr课程学习系列-solr的概念与结构(1)
Solr是基于Lucene的采用Java5开发的一个高性能全文搜索服务器.源于lucene,却更比Lucene更为丰富更为强大的查询语言.同时实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个 ...
- Folder Recursion with C#
by Richard Carr, published at http://www.blackwasp.co.uk/FolderRecursion.aspx Some applications must ...
- Oracle 一次生产分库,升级,迁移
今天完成了一个负载较高的中央数据库的分库操作, 并实现了oracle的滚动升级(10.2.0.1->10.2.0.4), 业务中断仅15分钟. 平台: RHEL AS 4 + Oracle 10 ...
- ajax 异步请求webservice(XML格式)
function callAjaxWebservice(){ alert("call ajax"); try { $.ajax({ type: "POST", ...