再谈hive-1.0.0与hive-1.2.1到JDBC编程忽略细节问题
不多说,直接上干货,这个问题一直迷惑已久,今天得到亲身醒悟。

所以,建议hadoop-2.6.0.tar.gz的用户与hive-1.0.0搭配使用。当然,也可以去用高版本去覆盖它。
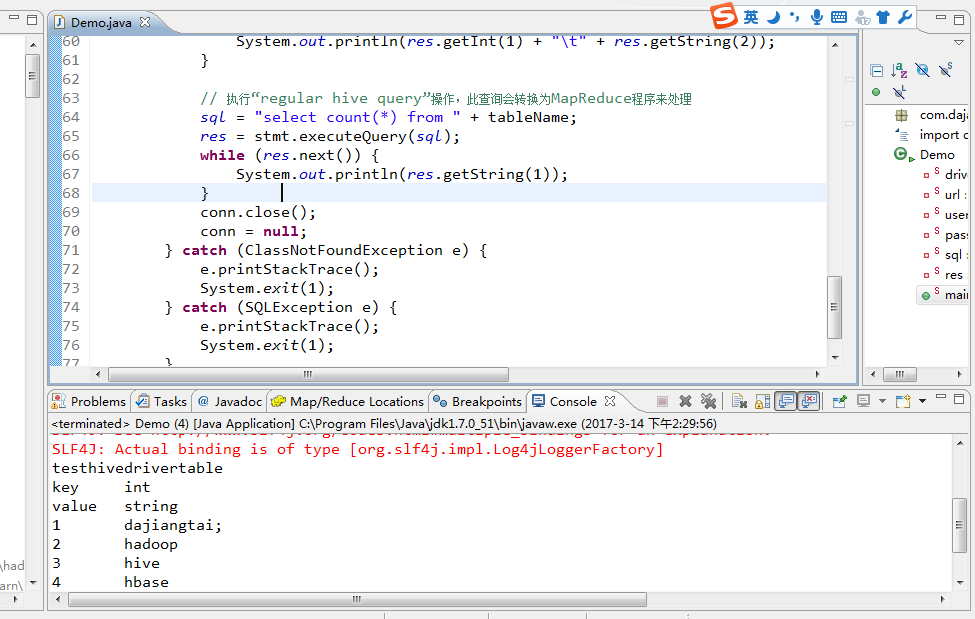
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/SoftWare/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/SoftWare/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
testhivedrivertable
key int
value string
1 dajiangtai;
2 hadoop
3 hive
4 hbase
5 spark
5
注意:在编程这端运行成功的同时:
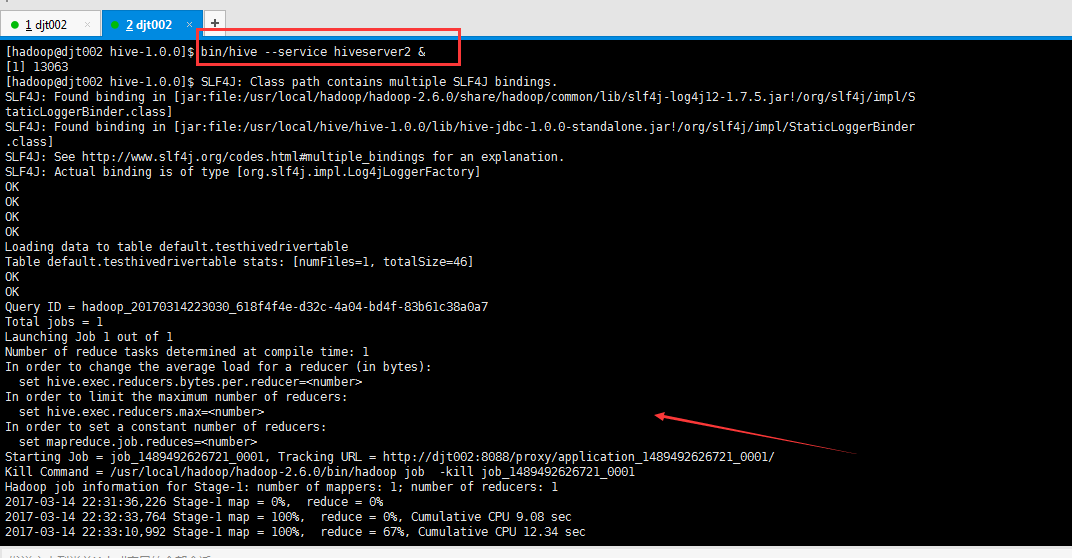
[hadoop@djt002 hive-1.0.0]$ bin/hive --service hiveserver2 &
[1] 13063
[hadoop@djt002 hive-1.0.0]$ SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hive/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
OK
OK
OK
OK
Loading data to table default.testhivedrivertable
Table default.testhivedrivertable stats: [numFiles=1, totalSize=46]
OK
OK
Query ID = hadoop_20170314223030_618f4f4e-d32c-4a04-bd4f-83b61c38a0a7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1489492626721_0001, Tracking URL = http://djt002:8088/proxy/application_1489492626721_0001/
Kill Command = /usr/local/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1489492626721_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-03-14 22:31:36,226 Stage-1 map = 0%, reduce = 0%
2017-03-14 22:32:33,764 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.08 sec
2017-03-14 22:33:10,992 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 12.34 sec
2017-03-14 22:33:14,485 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.51 sec
MapReduce Total cumulative CPU time: 14 seconds 510 msec
Ended Job = job_1489492626721_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 14.51 sec HDFS Read: 266 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 14 seconds 510 msec
OK
[hadoop@djt002 hive-1.0.0]$
总结,在用hive编程时,hive-1.0.0与hadoop-2.6.0搭配。还是最好的一个搭档。
我这里是手动新建的普通项目,即,将hadoop下的lib下所有的jar包和hive下的lib下的所有jar包,都导进入。
再谈hive-1.0.0与hive-1.2.1到JDBC编程忽略细节问题的更多相关文章
- Windows环境下搭建Hadoop(2.6.0)+Hive(2.2.0)环境并连接Kettle(6.0)
前提:配置JDK1.8环境,并配置相应的环境变量,JAVA_HOME 一.Hadoop的安装 1.1 下载Hadoop (2.6.0) http://hadoop.apache.org/release ...
- hadoop: hive 1.2.0 在mac机上的安装与配置
环境:mac OS X Yosemite + hadoop 2.6.0 + hive 1.2.0 + jdk 1.7.0_79 前提:hadoop必须先安装,且处于运行状态(伪分式模式或全分布模式均可 ...
- Ubuntu + hadoop2.6.0下安装Hive
第一步:准备hive和mysql安装包 下载hive 1.1.1 地址:http://www.eu.apache.org/dist/hive/ 下载Mysql JDBC 5.1.38驱动:http:/ ...
- apache hive 1.0.0发布
直接从0.14升级到1.0.0,主要变化有: 去掉hiveserver 1 定义公共的API,比如HiveMetaStoreClient 当然,也需要使用新的beeline cli客户端. 不过最值得 ...
- spark 2.0.0集群安装与hive on spark配置
1. 环境准备: JDK1.8 hive 2.3.4 hadoop 2.7.3 hbase 1.3.3 scala 2.11.12 mysql5.7 2. 下载spark2.0.0 cd /home/ ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- hive 3.1.0 安装配置
环境: hadoop 3.1.1 hive 3.1.0 mysql 8.0.11 安装前准备: 准备好mysql-connector-java-8.0.12.jar驱动包 上传hive的tar包并解压 ...
- hive on spark (spark2.0.0 hive2.3.3)
hive on spark真的很折腾人啊!!!!!!! 一.软件准备阶段 maven3.3.9 spark2.0.0 hive2.3.3 hadoop2.7.6 二.下载源码spark2.0.0,编译 ...
- HIVE 2.1.0 安装教程。(数据源mysql)
前期工作 安装JDK 安装Hadoop 安装MySQL 安装Hive 下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2.1.0-bi ...
随机推荐
- jquery ajax中error返回错误解决办法
转自:https://www.jb51.net/article/72198.htm 进入百度搜索此问题,发现有人这么说了一句 Jquery中的Ajax的async默认是true(异步请求),如果想一个 ...
- IE9以及IE9以下,无法执行innerHTML这一操作的解决方法
例如:在select下无法用innerHTML添加<option> 解决代码: var s=document.createElement("option"); s.te ...
- eclipse 报错:GC overhead limit exceeded
还是eclipse内存问题 修改eclipse.ini -Xms512m -Xmx1024m 必要的情况下, 添加 -XX:MaxPermSize=1024M 表示在编译文件时一直占有最大内存
- 读书笔记<深入理解JVM>01 关于OutOfMemoryError 堆空间的溢出
代码片段如下: package com.gosaint.shiro; import java.util.ArrayList; import java.util.List; public class H ...
- 20行核心代码:jQuery实现省市二级联动
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 290. Word Pattern 单词匹配模式
[抄题]: Given a pattern and a string str, find if str follows the same pattern. Here follow means a fu ...
- php学习笔记-关联数组
传统的数组定义方法如下: <?php $names[0]= 'chinese'; $names[1]= 'math'; $names[2]= 'english'; echo $names[2]; ...
- 正割、余割、正弦、余弦、正切、余切之间的关系的公式 sec、csc与sin、cos、tan、cot之间的各种公式
1.倒数关系 tanα ·cotα=1 sinα ·cscα=1 cosα ·secα=1 2.商数关系 tanα=sinα/cosα cotα=cosα/sinα 3.平方关系 sinα²+cosα ...
- 100200F Think Positive
传送门 题目大意 给你一个数n和长度为n的序列,序列中的每个数均为1或-1,如果一个点j对于任意的k都满足题目中给的式子,则j是一个合法位置,问这样的j有多少个 分析 这道题有两种方法,分别对应代码1 ...
- Pig Latin程序设计1
Pig是一个大规模数据分析平台.Pig的基础结构层包括一个产生MapReduce程序的编译器.在编译器中,大规模并行执行依据存在.Pig的语言包括一个叫Pig Latin的文本语言,此语言有如下特性: ...