spark与hive的集成
一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别为(区别):
-1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
--1.1 需要将连接数据库的驱动添加到Spark应用的classpath中
-2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
--2.1 直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式

4.启动hive service metastore服务
三:测试
1.spark-sql
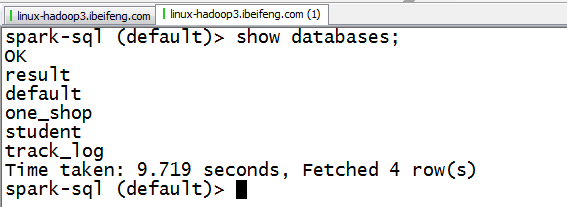
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache

五:使用spark-shell
1.启动
2.使用
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version.
http://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.27
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
备注:如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:
spark与hive的集成的更多相关文章
- 035 spark与hive的集成
一:介绍 1.在spark编译时支持hive 2.默认的db 当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库. ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 使用spark访问hive错误记录
在spark集群中执行./spark-shell时报以下错误: 18/07/23 10:02:39 WARN DataNucleus.Connection: BoneCP specified but ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark SQL -- Hive
使用Saprk SQL 操作Hive的数据 前提准备: 1.启动Hdfs,hive的数据存储在hdfs中; 2.启动hive -service metastore,元数据存储在远端,可以远程访问; 3 ...
随机推荐
- GoogleNet:inceptionV3论文学习
Rethinking the Inception Architecture for Computer Vision 论文地址:https://arxiv.org/abs/1512.00567 Abst ...
- Html5笔记之第八天
HTML字符实体 显示结果 描述 实体名称 实体编号 空格 < 小于号 < < > 大于号 > > & 和号 & & " ...
- Html5笔记之第六天
Canvas元素 <canvas> 标签定义图形,比如图表和其他图像,您必须使用脚本来绘制图形. 在画布上(Canvas)画一个红色矩形,渐变矩形,彩色矩形,和一些彩色的文字. <c ...
- spring mvc 处理流程整理
1. 首先用户发送请求-->DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制: 2. Dispatc ...
- mongodb 的服务启动和基本操作命令
由于在dos 下操作mongodb 很不方便 所以我推荐大家使用mongodb 的可视化工具robomongo 这个是robomongo的下载网址 https://robomongo.org/dow ...
- MongoDB导入导出以及数据库备份
-------------------MongoDB数据导入与导出------------------- 1.导出工具:mongoexport 1.概念: mongoDB中的m ...
- jvm系列 (四) ---强、软、弱、虚引用
java引用 目录 jvm系列(一):jvm内存区域与溢出 jvm系列(二):垃圾收集器与内存分配策略 jvm系列(三):锁的优化 我的博客目录 为什么将引用分为不同的强度 因为我们需要实现这样一种情 ...
- android TranslateAnimation 顶部segment分段移动动画
这里实现的功能是从主页布局的fragment点击跳转到一个acitivity,然后顶部是一个切换的segment顶部是一个listview,点击segment分段让listview加载不同的内容.我这 ...
- ASP.NET Core的身份认证框架IdentityServer4(8)- 使用密码认证方式控制API访问
前言 本文及IdentityServer这个系列使用的都是基于.net core 2.0的.上一篇博文在API项目中我使用了icrosoft.AspNetCore.Authentication.Jwt ...
- 当今游戏大作share的特性大盘点
极品游戏制作时的考虑要素大盘点 不知不觉入坑Steam已近4年,虽然说Steam的毒性让很多人走向一条不归路,但是想我这样即使"中毒"还是很快乐很感恩的.那么本期文章就谈谈我对其中 ...