[Spark内核] 第37课:Task执行内幕与结果处理解密
本课主题
- Task执行内幕与结果处理解密
引言
这一章我们主要关心的是 Task 是怎样被计算的以及结果是怎么被处理的
- 了解 Task 是怎样被计算的以及结果是怎么被处理的
Task 执行原理流程图
[下图是Task执行原理流程图]

- Executor 会通过 TaskRunner 在 ThreadPool 来运行具体的 Task,TaskRunner 内部会做一些准备的工作,例如反序例化 Task,然后通过网络获取需要的文件、Jar等
- 运行 Thread 的 run 方法,导致 Task 的 runTask 被调用来执行具体的业务逻辑处理
- 在Task 的 runTask内部会调用 RDD 的 iterator( ) 方法,该方法就是我们针对当前 Task 所对应的 Partition 进行计算的关键之所在,在处理内部会迭代 Partition 的元素并交给我们先定义的 Function 进行处理
- ShuffleMapTask: ShuffleMapTask 在计算具体的 Partition 之后实际上会通过 ShuffleManager 获得的 ShuffleWriter 把当前 Task 计算的数据具体 ShuffleManger 的实现来写入到具体的文件。操作完成后会把 MapStatus 发送给 DAGScheduler; (把 MapStatus 汇报给 MapOutputTracker)
- ResultTask: 根据前面 Stage 的执行结果进行 Shuffle 产生整个 Job 最后的结果;(MapOutputTracker 會把 ShuffleMapTask 執行結果交給 ResultTask)
Task 执行内幕源码解密
- 当 Driver 中的 CoarseGrainedSchedulerBackend 给 CoarseGrainedExecutorBackend 发送 LaunchTask 之后,CoarseGrainedExecutorBackend 在收到 LaunchTask 消息后,首先会判断一下有没有 Executor,没有的话直接退出和打印出提示信息,有的话会反序例化 TaskDescription,在执行具体的业务逻辑前会进行3次反序例化,第一个是 taskDescription,第二个是任务 Task 本身进行反序例化,还有的是RDD 的反序例化。
[下图是 CoarseGrainedExecutorBackend.scala 接收 LaunchTask case class 信息后的逻辑]
然后再发 LaunchTask 消息,里面会创建一个 TaskRunner,然后把它交给一个 runningTasks 的数据结构中,然后交给线程池去执行 Thread Pool。
[下图是 Executor.scala 中的 launchTask 方法]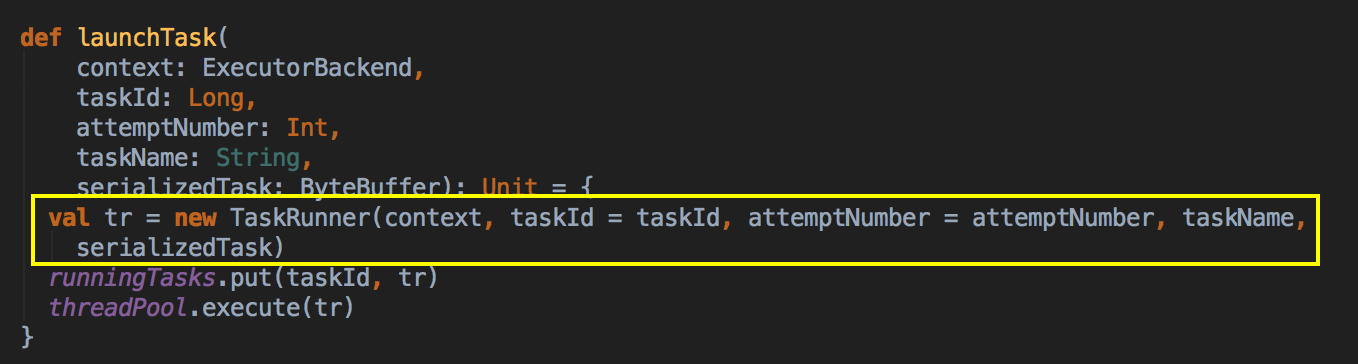
- Executor 会通过 TaskRunner 在ThreadPool 来运行具体的 Task,在 TaskRunner 的 run( )方法中首先会通过调用 stateUpdate 给 Driver 发信息汇报自己的状态,说明自己的RUNNING 状态。
[下图是 Executor.scala 中的 TaskRunner 类]
[下图是 Executor.scala 中的 run 方法]
[下图是 ExecutorBackend.scala 中的 statusUpdate 方法]
- TaskRunner 内部会做一些准备的工作,例如反序例化 Task 的依赖,这个反序例化得出一个 Tuple,然后通过网络获取需要的文件、Jar等;
[下图是在 Executor.scala 中 run 方法内部具体的代码实现]
在同一个 Stage 的内部需要共享资源。在同一个 Stage 中我们 ExecutorBackend 会有很多并发线程,此时它们所依赖的 Jar 跟文件肯定是一样的,每一个 TaskRunner 运行的时候都会运行在线程中,这个方法会被多个线程去调,所以线程需要一个加锁,而这个方法是有全区中的。这主要是要防止资源竞争。下载一切这个 Task 需要的 Jar 文件,我们通 Executor 在不同的线程中共享全区资源。
[下图是 Executor.scala 中的 updateDependencies 方法]
- 在 Task 的 runTask 内部会调用 RDD 的 iterator( ) 方法,该方法就是我们针对当前 Task 所对应的 Partition 进行计算的关键之所在,在处理内部会迭代 Partition 的元素并交给我们先定义的 Function 进行处理对于 ShuffleMapTask,首先要对 RDD 以及其他的依赖关系进行反序例化:
[下图是 Executor.scala 中 run 方法内部具体的代码实现]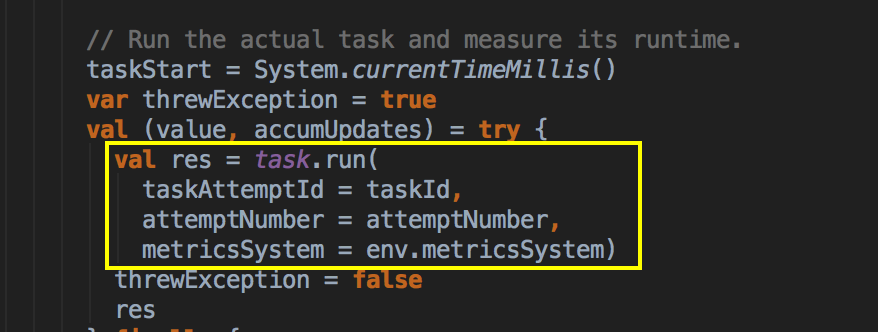
[下图是 Task.scala 中的 run 方法]
因为 Task 是一个 abstract class,它的子类是 ShuffleMapTask 或者是 ResultsMapTask,是乎我们当前的 Task 是那个类型。
[下图是 ShuffleMapTask.scala 中的 runTask 方法]
[下图是 RDD.scala 中的 iterator 方法]
[下图是 RDD.scala 中的 computeOrReadCheckpoint 方法]
最终计算会调用 RDD 的 compute 的方法具体计算的时候有具体的 RDD,例如 MapPartitionsRDD.compute,其中的 f 就是在当前 Stage 计算具体 Partition 的业务逻辑代码。
[下图是 RDD.scala 中的 compute 方法]
[下图是 MapPartitionsRDD.scala 中的 compute 方法]
- 调用反序例化后的 Task.run 方法来执行任务并获得执行结果,其中 Task 的 run 方法调用的时候会导致 Task 的抽象方法 runTask 的调用
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
- 把执行结果序例化
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
- 运行 Thread 的 run 方法,导致 Task 的 runTask 被调用来执行具体的业务逻辑处理
- 对于 ResultTask
[下图是 ResultsMapTask.scala 中的 runTask 方法]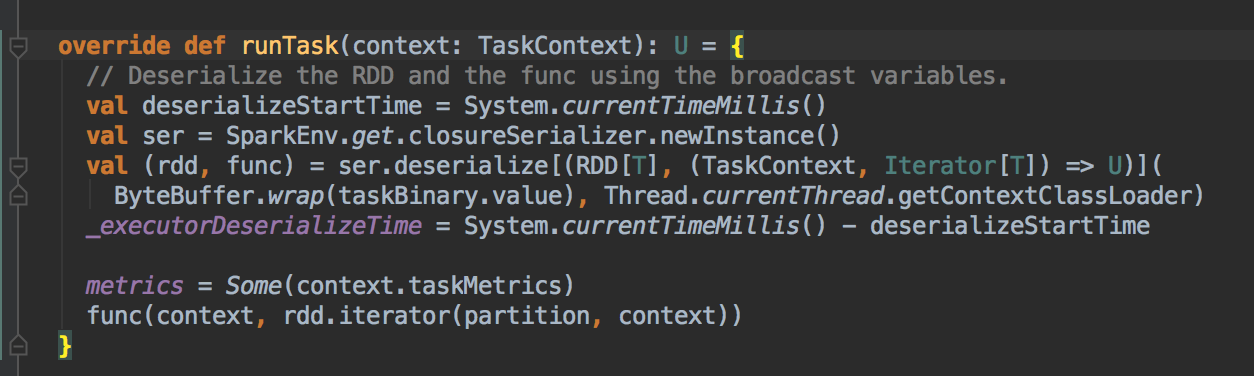
- 在 Spark 中 AkaFrameSize 是 128MB,所以可以扩播非常大的任务,而任务
- 并根据大小判断不同的结果传回给 Driver 的方式
- CoraseGrainedExectorBackend 给 DriverEndpoint 发送 StatusUpdate 来传执行结果
[下图是 Executor.scala 中 run 方法内部具体的代码实现]
[下图是 CoraseGrainedExectorBackend.scala 中 statusUpdate 方法]
[下图是 DriveEndPoint.scala 中 receive 方法]
- DriverEndpoint 会把执行结果传给 TaskSchedulerImpl 处理,然后交给 TaskResultGetter 去分别处理执行成功和失败时候的不同情况,然后告X DAGScheduler 任务处理结的情况重
[下图是 TaskSchedulerImpl.scala 中 statusUpdate 方法]
[下图是 TaskResultsGetter.scala 中 handleSuccessfulTask 方法]
[下图是 TaskSchedulerImpl.scala 中 handleSuccessfulTask 方法]
[下图是 TaskSetManager.scala 中 handleSuccessfulTask 方法]
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第37课:Task执行内幕与结果处理解密
Spark源码图片取自于 Spark 1.6.0版本
[Spark内核] 第37课:Task执行内幕与结果处理解密的更多相关文章
- Task执行内幕与结果处理解密
本课主题 Task执行内幕与结果处理解密 引言 这一章我们主要关心的是 Task 是怎样被计算的以及结果是怎么被处理的 了解 Task 是怎样被计算的以及结果是怎么被处理的 Task 执行原理流程图 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- [Spark内核] 第28课:Spark天堂之门解密
本課主題 什么是 Spark 的天堂之门 Spark 天堂之门到底在那里 Spark 天堂之门源码鉴赏 引言 我说的 Spark 天堂之门就是SparkContext,这篇文章会从 SparkCont ...
- [Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题 CacheManager 运行原理图 CacheManager 源码解析 CacheManager 运行原理图 [下图是CacheManager的运行原理图] 首先 RDD 是通过 iter ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
随机推荐
- Linux中MySQL配置文件my.cnf参数优化
MySQL参数优化这东西不好好研究还是比较难懂的,其实不光是MySQL,大部分程序的参数优化,是很复杂的.MySQL的参数优化也不例外,对于不同的需求,还有硬件的配置,优化不可能又最优选择,只能慢慢的 ...
- 从 Bridge 到 OVS,探索虚拟交换机
Linux Bridge 和物理网络一样,虚拟网络要通信,必须借助一些交换设备来转发数据.因此,对于网络虚拟化来说,交换设备的虚拟化是很关键的一环. 上文「网络虚拟化」已经大致介绍了 Linux 内核 ...
- kafak集群安装-转
前言 最近在利用Spark streaming和Kafka构建一个实时的数据分析系统,对图书阅读数据进行分析,做实时推荐.Spark Streaming 模块是对于 Spark Core 的一个扩展, ...
- The ResourceConfig instance does not contain any root resource classes
问题描述 当我们在使用 myeclipse 创建 Web Service Projects 项目后,运行项目然后就会出现这个问题. 解决方案 通过这个错误描述,我们项目没有找到这个资源.报错的原因在于 ...
- 运算符关键字。数据区别大小写。日期范围。判空的两种写法。NOT IN的两种写法。IN范围可含NULL,但NOT IN值范围不能含NULL。
比较:>,<,=,>=,<=,<>(!=) 逻辑:AND,OR,NOT 范围:BETWEEN...AND... 范围:IN,NOT IN 判空:IS NULL, I ...
- 【python】列表
>>> mix = [2,3.4,"abc",'中国',True,['ab',23]]>>> mix[2, 3.4, 'abc', '中国', ...
- springboot 入门六-多环境日志配置
在应用项目开发阶段,需要对日志进入很详细的输出便于排查问题原因,上线发布之后又只需要输出核心的日志信息的场景.springboot也提供多环境的日志配置.使用springProfile属性来标识使用那 ...
- Swift tableview自带的刷新控件
import UIKit class ViewController: UIViewController,UITableViewDelegate,UITableViewDataSource { let ...
- Kafka+Storm写入Hbase和HDFS
1.Storm整合Kafka 使用Kafka作为数据源,起到缓冲的作用 // 配置Kafka订阅的Topic,以及zookeeper中数据节点目录和名字 String zks = KafkaPrope ...
- [array] leetcode - 34. Search for a Range - Medium
leetcode - 34. Search for a Range - Medium descrition Given an array of integers sorted in ascending ...