浅谈SQL优化入门:1、SQL查询语句的执行顺序
1、SQL查询语句的执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
1.1 FROM 笛卡儿积
1.2 ON 过滤
1.3 添加外部行
1.4 WHERE过滤
1.5 GROUP BY分组
1.6 HAVING过滤
1.7 SELECT列表
1.8 执行DISTINCT
1.9 ORDER BY排序
1.10 LIMIT限制
2、浅谈一个坑

SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
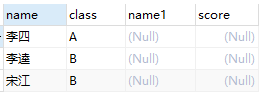
student AS stu LEFT JOIN score AS s ON stu.name = s.name AND stu.class = 'A'SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
student AS stu LEFT JOIN score AS s ON stu.name = s.name AND stu.class = 'A'
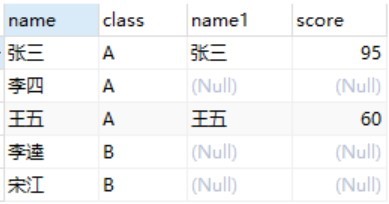
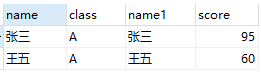 +
+ 
SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
student AS stu LEFT JOIN score AS s ON stu.name = s.name
WHERE
stu.class = 'A'SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
student AS stu LEFT JOIN score AS s ON stu.name = s.name
WHERE
stu.class = 'A'
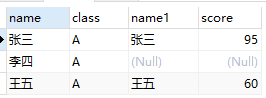
3、参考链接
浅谈SQL优化入门:1、SQL查询语句的执行顺序的更多相关文章
- {MySQL的逻辑查询语句的执行顺序}一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析
MySQL的逻辑查询语句的执行顺序 阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SEL ...
- 浅谈Java语言中try{}catch{}和finally{}的执行顺序问题
浅谈Java语言中try{}catch{}和finally{}的执行顺序问题 2019-04-06 PM 13:41:46 1. 不管有没有出现异常,finally块中代码都会执行: 2. 当t ...
- SQLServer2005中查询语句的执行顺序
SQLServer2005中查询语句的执行顺序 --1.from--2.on--3.outer(join)--4.where--5.group by--6.cube|rollup--7.havin ...
- Oracle中的一些查询语句及其执行顺序
查询条件: 1)LIKE:模糊查询,需要借助两个通配符,%:表示0到多个字符:_:标识单个字符. 2)IN(list):用来取出符合列表范围中的数据. 3)NOT IN(list): 取出不符合此列表 ...
- oracle中sql查询语句的执行顺序
查询语句的处理过程主要包含3个阶段:编译.执行.提取数据(sql查询语句的处理主要是由用户进程和服务器进程完成的,其他进程辅助配合) 一.编译parse 在进行编译时服务器进程会将sql语句的正文放入 ...
- mysql SQL 逻辑查询语句和执行顺序
关键字的执行优先级(重点) fromwheregroup byhavingselectdistinctorder bylimit 先创建两个表 CREATE TABLE table1 ( custom ...
- sql逻辑查询语句的执行顺序
SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN ...
- MySQL的逻辑查询语句的执行顺序
一.select语句关键字的定义顺序 二.select语句关键字的执行顺序 三.准备表和数据 四.准备SQL逻辑查询测试语句 五.执行顺序分析 一.select语句关键字的定义顺序 SELECT DI ...
- mysql查询语句的执行顺序(重点)
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
随机推荐
- 从零宽断言说起到用python匹配html标签内容
版权声明:本文为博主原创文章,转载请附带原文网址http://www.cnblogs.com/wbchanblog/p/7411750.html ,谢谢! 提示:本文主要是讲解零宽断言,所以阅读本文需 ...
- Writing A Threadpool in Rust
文 Akisann@CNblogs / zhaihj@Github 本篇文章同时发布在Github上:https://zhaihj.github.io/writing-a-threadpool-in- ...
- 【Ubuntu 16】安装deb
deb是debian linux的安装格式,跟red hat的rpm非常相似,最基本的安装命令是:dpkg -i file.deb dpkg 是Debian Package的简写,是为Debian ...
- 【LCT】一步步地解释Link-cut Tree
简介 Link-cut Tree,简称LCT. 干什么的?它是树链剖分的升级版,可以看做是动态的树剖. 树剖专攻静态树问题:LCT专攻动态树问题,因为此时的树剖面对动态树问题已经无能为力了(动态树问题 ...
- 七字真言解读TCP三次握手
三次握手所谓的"三次握手"即对每次发送的数据量是怎样跟踪进行协商使的发送和接收同步,根据所接收到的数据量而确定的数据确认数及数据发送.接收完毕后何时撤消联系,并建立虚连接. 一.七 ...
- c89和c99中/运算符和%运算符为负数时的区别
运算式 -8 / 5 = -1.6,在C89中取值为 -1 或 -2,C99的出现,CPU对除法的结果向零取整,上述运算式结果为 -1. 在C89和C99中都要确保 (a / b) * b + a % ...
- 基于FPGA的Sobel边缘检测的实现
前面我们实现了使用PC端上位机串口发送图像数据到VGA显示,通过MATLAB处理的图像数据直接是灰度图像,后面我们在此基础上修改,从而实现,基于FPGA的动态图片的Sobel边缘检测.中值滤波.Can ...
- plsql developer 恢复默认布局界面
tools-preferences-appearance-(reset docking,reset toolbars)
- [UWP]理解及扩展Expander
##1. 前言 最近在自定义Expander的样式,顺便看了看它的源码. Expander控件是一个ContentControl,它通过IsExpanded属性或者通过点击Header中的Toggle ...
- 数据库学习任务三:执行数据库操作命令对象SqlCommand
数据库应用程序的开发流程一般主要分为以下几个步骤: 创建数据库 使用Connection对象连接数据库 使用Command对象对数据源执行SQL命令并返回数据 使用DataReader和DataSet ...