以Random Forests和AdaBoost为例介绍下bagging和boosting方法
我们学过决策树、朴素贝叶斯、SVM、K近邻等分类器算法,他们各有优缺点;自然的,我们可以将这些分类器组合起来成为一个性能更好的分类器,这种组合结果被称为 集成方法 (ensemble method)或者 元算法 (meta-method)。使用集成算法时有多种形式:
- 不同算法的集成
- 同一种算法在不同设置下的集成
- 数据集不同部分分配 给不同分类器之后的集成
1、bagging 和boosting综述
bagging 和boosting中使用的分类器类型都是一样的。
bagging,也成为自举汇聚法(boostrap aggegating) 是在原始数据集有放回的选择S次后得到S个新数据集的一种技术。新数据集合原数据集大小相等,但是有可能某一条数据被选择了好几次,而原数据集中某些数据在新数据集中可能不出现。在S个数据集建好之后,将某个算法分别作用于每个数据集就得到S个分类器。对新数据集进行分类时,就用这S个分类器进行分类,与此同时,选择分类器投票结果中最多的的类别作为最终分类结果,如图1所示。Random Forests是一种更先进的bagging算法,下文详细介绍。

boosting 与bagging很类似,不同的是Boosting是通过串行训练而获得的,而每个新分类器都是根据已经训练好的分类器的性能来进行训练的。AdaBoost是这一种常用的boosting方法。
2、一种提升算法:AdaBoost
在概率近似正确的学习框架(probably approximately corect,PAC)中,一个概念,如果存在一个多项式的学习算法能够学习他,并且正确率很高,在统计学习方法中,称这个概念是 强可学习(strongly learnable)的;而如果正确率仅仅比随机猜测(正确率大于0.5)略好,那么称这个概念是 弱可学习(weakly learnable) 的。然而Schapire证明了再PAC学习框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。
那么也就是说,我们可以将“弱学习算法”提升为“强学习算法”,毕竟弱学习算法比强学习算法要好找的多了。问题是怎么来提升呢?有很多算法,最具代表性的就是AdaBoost算法。大多数提升方法都是改变训练数据的概率分布(训练数据的权值分布)。
因此,对提升算法有两个问题需要回答:
- 在每一轮如何改变训练数据的权值或者概率分布
- 如何将若分类器组合成一个强分类器
对于第一个问题AdaBoost通过集中关注那些错分的数据,即将错分的数据赋予较大的权重,没错分的数据赋予较小的权重,然后再将这有具有新权重的数据集进行训练,从而来获得新分类器;对于第二个问题,AdaBoost采取加权多数表决的方法。
2.1、AdaBoost算法
首先提一下几个数学表达式的意思,当做本小节的先验知识吧。

AdaBoost算法

在上述算法中,值得注意的是:
- 在2(c)中,由弱分类器的系数计算公式可知,在当前的弱分类器分类后,其分类误差率em如果小于0.5,系数$\alpha _{m}$将大于0,并且系数随着误差率em的减少而增大,所以分类误差率小的基本分类器在最终分类器中的作用越大。
- 在2(d)中,更新权值分布时,被基本分类器误分类的样本的权值得意扩大,而被正确分类的样本的权值得以缩小,即误分类样本在下一次训练中起更大的作用。
- 在步骤(3)中,f(x)的符号决定实例x的类,它的绝对值表示分类的确信度。利用基本分类器的线性组合构建最终分类器是AdaBoost的一个特点
AdaBoost算法的示意图如图2所示。
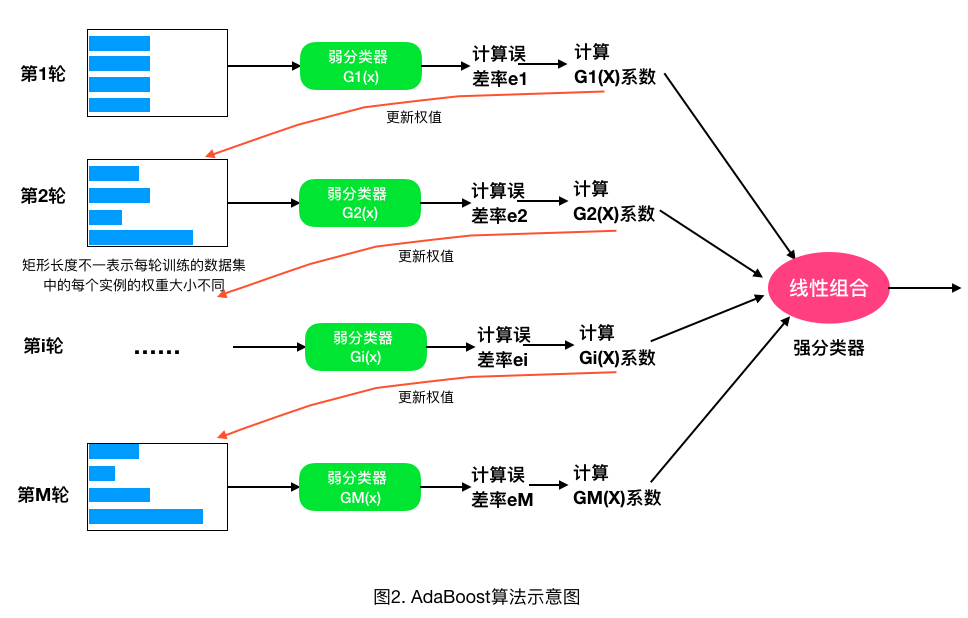
2.2、AdaBoost算法的误差分析
AdaBoost最基本的性质是它能在学习的过程中不断的减少训练误差,即在训练数据集上的分类误差率。那么训练误差是不是能无限制的减少呢?AdaBoost训练误差界定理回答了这个问题。
AdaBoost算法最终分类器的训练误差界为:

推导从略,见《统计学习方法》一书。
这一定理说明,可以在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降最快。
对于二类分类问题有:

AdaBoost的训练误差是以指数速率下降的。AdaBoost具有适应性,即它能适应弱分类器各自的训练误差率,这也是它名称的由来,即adaptive。
3、Random Forests(RF)
RF在实际中使用非常频繁,其本质上和bagging并无不同,只是RF更具体一些。一般而言可以将RF理解为bagging和DT(CART)的结合。RF中的基学习器使用的是CART树,由于算法本身能降低方差(variance),所以会选择完全生长的CART树。抽样方法使用bootstrap,除此之外,RF认为随机程度越高,算法的效果越好。所以RF中还经常随机选取样本的特征属性、甚至于将样本的特征属性通过映射矩阵映射到随机的子空间来增大子模型的随机性、多样性。RF预测的结果为子树结果的平均值。RF具有很好的降噪性,相比单棵的CART树,RF模型边界更加平滑,置信区间也比较大。一般而言,RF中,树越多模型越稳定。
3.1 随机森林算法
随机森林训练过程如下:
(1)给定训练集S,测试集T,特征维数F。确定参数:使用到的CART的数量t,每棵树的深度d,每个节点使用到的特征数量f,终止条件:节点上最少样本数s,节点上最少的信息增益m
对于第1-t棵树,i=1-t:
(2)从S中有放回的抽取大小和S一样的训练集S(i),作为根节点的样本,从根节点开始训练
(3)如果当前节点上达到终止条件,则设置当前节点为叶子节点,如果是分类问题,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(j),概率p为c(j)占当前样本集的比例;如果是回归问题,预测输出为当前节点样本集各个样本值的平均值。然后继续训练其他节点。如果当前节点没有达到终止条件,则从F维特征中无放回的随机选取f维特征。利用这f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余的被划分到右节点。继续训练其他节点。有关分类效果的评判标准在后面会讲。
(4)重复(2)(3)直到所有节点都训练过了或者被标记为叶子节点。
(5)重复(2),(3),(4)直到所有CART都被训练过。
利用随机森林的预测过程如下:
对于第1-t棵树,i=1-t:
(1)从当前树的根节点开始,根据当前节点的阈值th,判断是进入左节点(\
(2)重复执行(1)直到所有t棵树都输出了预测值。如果是分类问题,则输出为所有树中预测概率总和最大的那一个类,即对每个c(j)的p进行累计;如果是回归问题,则输出为所有树的输出的平均值。
参考资料
- 《统计机器学习》,李航
- 《机器学习实战》,Peter
- http://www.cnblogs.com/hrlnw/p/3850459.html
以Random Forests和AdaBoost为例介绍下bagging和boosting方法的更多相关文章
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
- Linux(以RHEL7为例)下添加工作区的方法|| The Way To Add Workspace On Linux
Linux(以RHEL7为例)下添加工作区的方法 The Way To Add Workspace On Linux 作者:钟凤山(子敬叔叔) 编写时间:2017年5月11日星期四 需求:有时候在使用 ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- Bagging决策树:Random Forests
1. 前言 Random Forests (RF) 是由Breiman [1]提出的一类基于决策树CART的Bagging算法.论文 [5] 在121数据集上比较了179个分类器,效果最好的是RF,准 ...
- 随机森林——Random Forests
[基础算法] Random Forests 2011 年 8 月 9 日 Random Forest(s),随机森林,又叫Random Trees[2][3],是一种由多棵决策树组合而成的联合预测模型 ...
- CF Gym 102028G Shortest Paths on Random Forests
CF Gym 102028G Shortest Paths on Random Forests 抄题解×1 蒯板子真jir舒服. 构造生成函数,\(F(n)\)表示\(n\)个点的森林数量(本题都用E ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- Bagging和Boosting的介绍及对比
"团结就是力量"这句老话很好地表达了机器学习领域中强大「集成方法」的基本思想.总的来说,许多机器学习竞赛(包括 Kaggle)中最优秀的解决方案所采用的集成方法都建立在一个这样的假 ...
随机推荐
- 通过wireshark学习Traceroute命令(UDP,ICMP协议)
traceroute: 通过TTL限定的ICMP/UDP/TCP侦测包来发现从本地主机到远端目标主机之间的第三层转发路径.用来调试网络连接性和路由问题. mtr: traceroute的一个变种,能根 ...
- Javascript及Jquery获取元素节点以及添加和删除操作
用了javascript和jquery很久,把所有元素节点的操作总结了下,放在博客上作为记录. Javascript获取元素的主要方式有三种 1.document.getElementById('ma ...
- Xamarin App文件(apk)大小和启动时间的影响因素
Xamarin开发的时候大家都有一个疑问,就是apk文件会不会特别的大,启动会不会很慢.答案是肯定的,文件肯定大,启动肯定会慢,但是具体大多少.具体慢多少,有什么因素可以使apk文件稍微小一点.可以使 ...
- 关于Eclipse+SVN 开发配置
入职快一个月,学的比较慢,但学的东西很多,受益匪浅.有时候真正意义上,感受到:代码使我快乐,我爱编程. 好久没有开笔,不知道说些什么,也不知道应该说什么. 但总觉得有些东西,很想说出来,不用理会他人的 ...
- JS/jQ常用宽高及应用
关于js的宽高,随便一搜就是一大堆.这个一大堆对我来说可不是什么好事,看的头都大了.所以今天就总结了一些比较会常用的,并说明一下应用场景. 先来扯一下documentElement和body的微妙关系 ...
- 浅谈Ubuntu PowerShell——小白入门教程
早在去年八月份PowerShell就开始开源跨平台了,但是一直没有去尝试,叫做PowerShell Core. 这里打算简单介绍一下如何安装和简单使用,为还不知道PowerShell Core on ...
- 使用DBeaver连接hive
介绍 在hive命令行beeline中写一些很长的查询语句不是很方便,查询结果也不是很友好,于是找了一个hive的客户端界面工具DBeaver,它也支持很多符合JDBC连接的数据库,例如MySQL.O ...
- asp.net mvc中html helper的一大优势
刚上手这个框架,发现其中的html helper用起来很方便,让我们这些从web form 过渡来的coder有一种使用控件的快感,嘻嘻! 言归正传,我要说的是在使用它时,系统会自动执行表单的现场恢复 ...
- 搭建vue开发环境及各种报错处理
1.安装node.js 参考教程:http://nodejs.cn/download/ 我的是windows 64位系统,以此为例: (1)打开 http://nodejs.cn/download/ ...
- C#与Java对比学习
Eclipse开发环境与VS开发环境的调试对比 数据类型.集合类.栈与队列.迭达.可变参数.枚举 类型判断.类与接口继承.代码规范与编码习惯.常量定义