Hadoop2.7.5+Hbase1.4.0完全分布式
Hadoop2.7.5+Hbase1.4.0完全分布式
一、在介绍完全分布式之前先给初学者推荐两本书:
《Hbase权威指南》偏理论
《Hbase实战》实战多一些
二、在安装完全分布式之前应该对他们的概念有个简单的认知:
1、Hadoop擅长存储任意的、半结构化的,甚至是结构化的数据,几乎是现在所有数据库的一种补充。
2、Hbase是hadoop数据库,hbase并不是一个列式存储数据库,他是利用的磁盘上的列存储格式。
3、列存储数据库是以“列”为单位的聚合数据库,然后按顺序地存入磁盘。
4、RDBMS与列存储数据库地区别:
rdbms适合有限、有规则(范式、科德十二定律)地数据,适合实时存取数据地场景
hbase适合键值对地数据存取或者有序地数据存取
5、hbase数据库最基本地单位是“列”
6、一列或者多列形成一行,并且由唯一的“行键”来存储(行键就相当于rdbms中的主键索引是一样的性质)
7、一个表可以有若干行,其中每列可能有多个版本,每个单元格存储了不同地值
8、若干列构成了一个“列族”
9、一个列族地所有列存储在同一个底层地存储文件里,这个存储文件叫做Hfile。
10、“列族”需在创建表的时候就定义好,且数量不要太多,修改也不要太频繁,一般只建议1~2个,最好只用一个
11、与列族相反,列地数量没有限制,列值得类型和长度也没有限制。
12、每一列得值和单元格得值都具有时间戳,默认由系统指定,也可以是用户自己指定。
13、一个单元格得数据默认是按“降序”排列的,访问时有限读取最新的数据。
14、hbase数据存储模式:
test<rowkey,list<tests<column,list<value,timestamp>>>>
test表示一个表,rowkey是行键,包含一个列族list(第一个list),列族种包含了tests存储列和对应的值,这些值存储在最后一个list种,并对应有时间戳
15、Hbase是一个分布式的、持久性的、强一致性的存储系统。
三、hbase分布式环境搭建:
1、并不是所有的Hbase运行模式都需要分布式,如果只是想在本地测试,只需要安装java即可。
2、完全分布式搭建:
(1)、环境
系统:centos6.8
hadoop版本:2.7.5
zookeeper版本:3.4.11
hbase版本:1.4.0
(2)、下载hbase安装包:
下载地址:http://apache.spinellicreations.com/hbase/
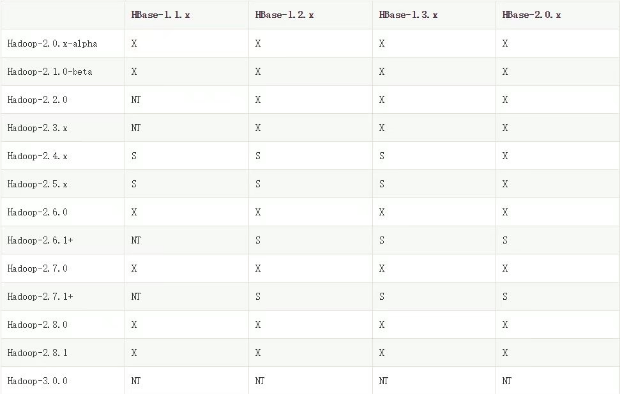
hbase需要跟Hadoop版本对应
(3)、将下好的hbase安装包上传至服务器然后解压至合适的目录中, 我们使用的是Hbase的版本是:hbase-1.4.0-bin.tar.gz
tar -zxvf hbase-1.2.1-bin.tar.gz -C /root/apps/
(4)、解压之后可以看到项目目录里面包含哪些文件:
ll命令或者ls -lr可查看:
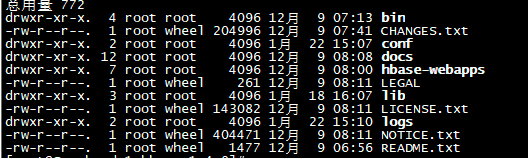
(5)、a.说明文档以及许可条款在LICENSE.txt和NOTICE.txt文件中。
b.其他一些生成信息在README.txt中。
c.CHANGES.txt是变更日志的静态快照页面,它包含了当前下载版本中多有的变更记录。
d.Bin是一个二进制文件,此目录包含了hbase提供的所有脚本,可以完成启动和停止,运行独立的守护进程或启动额外的master节点等功能。
e.Conf目录包含了定义hbase配置的文件。
f.Docs目录包含了hbase工程网页的副本,以及工具、API和项目自身的文档信息。
g.hbase-webapps这个目录包含了java实现的web接口。
h.Lib目录包含了java应用程序的很多类库,这些类库包含了很多实际的执行程序。
i.Logs目录首次启动的时候不存在,但是Hbase会通过日志框架自动创建日志文件夹。hbase进程通常以守护进程的形式运行,即在操作系统的后台运行,在生命周期内他会将一些状态、进程、异常等信息打印到日志文件中。
j.Src文件是一些源文件及其包含的发布信息。
(6)、Hbase运行模式分为两种:单机模式和分布式模式
(7)、分布模式又分为伪分布模式和完全分布模式,这里我们介绍的是完全分布模式。
四、hbase完全分布式搭建:
1、假设我们的Linux环境都已经准备好,搭建了4台Hadoop+hdfs,名称分别是Sparknode1,Sparknode2,Sparknode3,Sparknode4。搭建了三台zookeeper集群,名称分别是zookeeper1,zookeeper2,zookeeper3。这里我没有使用hbase自带的zookeeper集群,而是自己搭建了另外一套zookeeper集群。
2、在安装hbase集群之前必须保证HDFS集群和zookeeper集群已经启动,因为hbase是依赖于hdfs和zookeeper的,二者缺一不可。
3、启动zookeeper的命令:
bin/zkServer.sh start
HDFS的启动命令:
sbin/start-dfs.sh
4、将hbase安装包解压至指定的文件夹后,需要修改配置文件hbase-env.sh,修改如下:
//修改JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_101/
//Hbase使用的是自己另外搭建的zookeeper集群,没有使用自带的zookeeper集群,所以需要把HBASE_MANAGES_ZK属性值设置成false,默认是ture
export HBASE_MANAGES_ZK=false
//修改Hbase堆设置,默认大小是1G,将其设置成4G
export HBASE_HEAPSIZE=4G
5、修改配置文件hbase-site.xml,修改如下:
<configuration>
<property>
<name>hbase.rootdir</name> /*region服务器的共享目录,用来持久存储hbase数据,HDFS实例*/
<value>hdfs://master:9000/hbase</value> /*HDFS主节点(namenode)的访问位置*/
</property>
<property>
<name>hbase.cluster.distributed</name> /*hbase集群运行模式*/
<value>true</value> /*false为单机模式,ture为分布式模式*/
</property>
<property>
<name>hbase.zookeeper.quorum</name> /*zookeeper quorum服务器中的服务器列表*/
<value>zookeeper1:2181,zookeeper2:2181,zookeeper3:2181</value> /*每个服务器之间使用使用逗号分隔,2181是zookeeper默认端口号,你可以自行根据你的端口号添加,默认的端口号加不加都无所谓*/
</property>
<property>
<name>hbase.master.info.port</name> /*Hbase master的web UI服务端口*/
<value>60010</value> /*如果不想启动UI实例,则将参数设置成-1,默认值是60010*/
</property>
</configuration>
6、修改配置文件regionservers,修改如下:
配置region服务器,该文件列出了所有运行hregionserver守护进程的主机,每个主机独立占一行,Hbase集群启动和关闭都会按照文件中罗列的主机一一执行。
Sparknode1
Sparknode2
Sparknode3
Sparknode4
7、将HBASE加入环境变量:
export HBASE_HOME=/usr/soft/hbase-1.4.0
8、将Hadoop的配置文件拷到hbase下:
将hadoop的/opt/hadoop-2.7.5/etc/hadoop/目录下面的hdfs-site.xml和core-site.xml这两个配置文件拷贝到HBase的/usr/soft/hbase-1.4.0/conf/目录下:
这里我没有用拷贝的方式,而是用了软链接(快捷方式),目的是为了防止Hadoop目录下的配置文件更改了之后还要去/usr/soft/hbase-1.4.0/conf/目录下更新:
ln -s /opt/hadoop-2.7.5/etc/hadoop/ /usr/soft/hbase-1.4.0/conf/
用法:ln -s 源文件(夹) 目标文件(夹)
9、将配置后的hbase目录拷贝到其他节点
在Sparknode1(主节点)上分别执行如下命令,将Sparknode2上的hbase-1.4.0目录分别拷贝到Sparknode2、Sparknode3和Sparknode4的相同目录下:
scp -r hbase-1.4.0/ Sparknode2:$PWD
scp -r hbase-1.4.0/ Sparknode3:$PWD
scp -r hbase-1.4.0/ Sparknode4:$PWD
10、同步时间
我们在使用HDFS的时候经常会出现一些莫名奇妙的问题,通常可能是由于多台服务器的时间不同步造成的。因为它要经常去分析一些时间戳、版本或者超时时间等,如果多台服务器的时间差的太远,可能会导致一些误判。
有两种方式来同步多台服务器的时间:
(1)在每台服务器上开启时间同步的进程,通过网络时间服务器进行同步;
(2)如果你的电脑不能联网,可以将多台服务器的时间手动改成一致的;
我们下面使用第二种方式来设置,使用“date –s”命令来同步时间:

11、启动hbase集群
在启动Hbase集群之前,确保hdfs集群和zookeeper集群都已经启动成功。
bin/start-hbase.sh
状态如下:

12、利用jps命令查看运行进程
jps
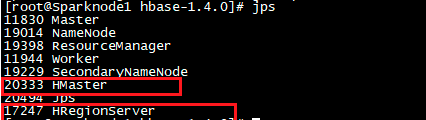
红框里面的是主节点上的两个hbase的两个进程,其他datanode上只有hregionserver进程
13、停止hbase集群
bin/stop-hbase.sh
状态如下:

Hadoop2.7.5+Hbase1.4.0完全分布式的更多相关文章
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署
因为学习,在网上找了很多hbase搭建的文章,感觉这篇很好,点此 搭建好后,jps查看了后台进程,发现在slave上面没有HRegionServer进程 便查看了 slave上关于HRegionSer ...
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- 琐碎-hadoop2.2.0伪分布式和完全分布式安装(centos6.4)
环境是centos6.4-32,hadoop2.2.0 伪分布式文档:http://pan.baidu.com/s/1kTrAcWB 完全分布式文档:http://pan.baidu.com/s/1s ...
- hadoop2.2.0+hive-0.10.0完全分布式安装方法
hadoop+hive-0.10.0完全分布式安装方法 1.jdk版本:jdk-7u60-linux-x64.tar.gz http://www.oracle.com/technetwork/cn/j ...
- hadoop-2.6.0为分布式安装
hadoop-2.6.0为分布式安装 伪分布模式集群规划(单节点)------------------------------------------------------------------- ...
- 基于Hadoop2.2.0版本号分布式云盘的设计与实现
基于Hadoop2.2.0版本号分布式云盘的设计与实现 一.前言 在学习了hadoop2.2一个月以来,我重点是在学习hadoop2.2的HDFS.即是hadoop的分布式系统,看了非常久的源代码看的 ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
随机推荐
- c#发送get请求
c#发送get请求爬取网页 关键点:在控制台中发送一个get请求,将响应的内容写入文件流中保存html格式 static void Main(string[] args) { string url = ...
- php-删除非空目录
function deldir($path){ if(!is_dir($path)){ return false; } $dh = opendir($path); while(($file = rea ...
- SpringBoot_02_servlet容器配置
二.参考资料 1.Spring boot 自定义端口 2.Spring Boot的Web配置(九):Tomcat配置和Tomcat替换
- g4e基础篇#2 Git分布式版本控制系统的优势
g4e 是 Git for Enterprise Developer的简写,这个系列文章会统一使用g4e作为标识,便于大家查看和搜索. 章节目录 前言 1. 基础篇: 为什么要使用版本控制系统 Git ...
- 跟我一起,利用bitcms内容管理系统从0到1学习小程序开发:一、IIS下SSL环境搭建
缘起 1.从事互联网十来年了,一直想把自己的从事开发过程遇到的问题给写出来,分享给大家.可是可是这只是个种想法,想想之后就放下了,写出来的类文章是少之又少.古人说无志之人常立志,有志之人立长志.今天, ...
- 一、JavaSE语言概述
1.软件:系统软件 VS 应用软件 2.人与计算交互:使用计算机语言.图形化界面VS命令行. 3.语言的分类:第一代:机器语言 第二代:汇编语言 第三代语言:高级语言(面向过程-面向对象) 4.jav ...
- ldap命令的使用
转自:http://blog.chinaunix.net/uid-20690190-id-4085176.html 增:ldapadd 1)选项: -x 进行简单认证 -D 用来绑定服务器的D ...
- TPYBoard实例之利用WHID为隔离主机建立隐秘通道
本文作者:xiaowuyi,来自FreeBuf.COM(MicroPythonQQ交流群:157816561,公众号:MicroPython玩家汇) 0引言 从2014年BADUSB出现以后,USB- ...
- 这是要逆天么,看我控制台程序玩Microsoft XPS Document 打印
主要是想试试Microsoft XPS Document 打印时怎样去掉那个“将打印输出另存为”对话框 using System; using System.Drawing; using System ...
- 【读书笔记】【深入理解ES6】#10-改进的数组功能
创建数组 在ES6之前,创建数组的方式主要有两种: 调用 Array 构造函数 用数组字面量语法 为了简化数组的创建过程,ES6新增了两个方法: Array.of() Array.from() Arr ...