python 模块 - 序列化 json 和 pickle
1,引入
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x = "[nuaa,true,dalse,1]" # print(eval(x)) # 报错,无法解析null类型,而json就可以 print(json.dumps(x)) # "[nuaa,true,dalse,1]"
2,什么时序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
3,为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
4,如何和序列化之 json 和 pickle:
json
一,python类型数据和json数据格式互相转换
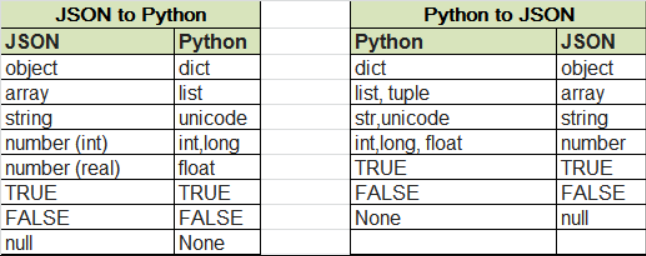
pthon 中str类型到json中转为unicode类型,None转为null,dict对应object
二,数据encoding和decoding
所谓简单类型就是指上表中出现的python类型。
dumps: 将对象序列化
import json # 简单编码===========================================
print json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
# ["foo", {"bar": ["baz", null, 1.0, 2]}] #字典排序
print json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)
# {"a": 0, "b": 0, "c": 0} #自定义分隔符
print json.dumps([1,2,3,{'': 5, '': 7}], sort_keys=True, separators=(',',':'))
# [1,2,3,{"4":5,"6":7}]
print json.dumps([1,2,3,{'': 5, '': 7}], sort_keys=True, separators=('/','-'))
# [1/2/3/{"4"-5/"6"-7}] #增加缩进,增强可读性,但缩进空格会使数据变大
print json.dumps({'': 5, '': 7}, sort_keys=True,indent=2, separators=(',', ': '))
# {
# "4": 5,
# "6": 7
# } # 另一个比较有用的dumps参数是skipkeys,默认为False。
# dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,会忽略这个key。
data = {'a':1,(1,2):123}
print json.dumps(data,skipkeys=True)
#{"a": 1}
python2代码
dump: 将对象序列化并保存到文件
#将对象序列化并保存到文件
obj = ['foo', {'bar': ('baz', None, 1.0, 2)}]
with open(r"c:\json.txt","w+") as f:
json.dump(obj,f)
loads: 将序列化字符串反序列化
import json
obj = ['foo', {'bar': ('baz', None, 1.0, 2)}]
a= json.dumps(obj)
print(json.loads(a))
# [u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
load: 将序列化字符串从文件读取并反序列化
with open(r"c:\json.txt","r") as f:
print (json.load(f))
三、自定义复杂数据类型编解码
例如我们碰到对象datetime,或者自定义的类对象等json默认不支持的数据类型时,我们就需要自定义编解码函数。有两种方法来实现自定义编解码。
1、方法一:自定义编解码函数
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# __author__ = "TKQ"
import datetime,json dt = datetime.datetime.now() def time2str(obj):
#python to json
if isinstance(obj, datetime.datetime):
json_str = {"datetime":obj.strftime("%Y-%m-%d %X")}
return json_str
return obj def str2time(json_obj):
#json to python
if "datetime" in json_obj:
date_str,time_str = json_obj["datetime"].split(' ')
date = [int(x) for x in date_str.split('-')]
time = [int(x) for x in time_str.split(':')]
dt = datetime.datetime(date[0],date[1], date[2], time[0],time[1], time[2])
return dt
return json_obj a = json.dumps(dt,default=time2str)
print a
# {"datetime": "2016-10-27 17:38:31"}
print json.loads(a,object_hook=str2time)
# 2016-10-27 17:38:31
python2代码
2、方法二:继承JSONEncoder和JSONDecoder类,重写相关方法
#! /usr/bin/env python
# -*- coding:utf-8 -*-
# __author__ = "TKQ"
import datetime,json dt = datetime.datetime.now()
dd = [dt,[1,2,3]] class MyEncoder(json.JSONEncoder):
def default(self,obj):
#python to json
if isinstance(obj, datetime.datetime):
json_str = {"datetime":obj.strftime("%Y-%m-%d %X")}
return json_str
return obj class MyDecoder(json.JSONDecoder):
def __init__(self):
json.JSONDecoder.__init__(self, object_hook=self.str2time) def str2time(self,json_obj):
#json to python
if "datetime" in json_obj:
date_str,time_str = json_obj["datetime"].split(' ')
date = [int(x) for x in date_str.split('-')]
time = [int(x) for x in time_str.split(':')]
dt = datetime.datetime(date[0],date[1], date[2], time[0],time[1], time[2])
return dt
return json_obj # a = json.dumps(dt,default=time2str)
a =MyEncoder().encode(dd)
print a
# [{"datetime": "2016-10-27 18:14:54"}, [1, 2, 3]]
print MyDecoder().decode(a)
# [datetime.datetime(2016, 10, 27, 18, 14, 54), [1, 2, 3]]
python2代码
====================================================================================
pickle
python的pickle模块实现了python的所有数据序列和反序列化。基本上功能使用和JSON模块没有太大区别,方法也同样是dumps/dump和loads/load。cPickle是pickle模块的C语言编译版本相对速度更快。
与JSON不同的是pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型。
pickle反序列化后的对象与原对象是等值的副本对象,类似与deepcopy。
dumps/dump序列化
from datetime import date try:
import cPickle as pickle #python 2
except ImportError as e:
import pickle #python 3 src_dic = {"date":date.today(),"oth":([1,"a"],None,True,False),}
det_str = pickle.dumps(src_dic)
print det_str
# (dp1
# S'date'
# p2
# cdatetime
# date
# p3
# (S'\x07\xe0\n\x1b'
# tRp4
# sS'oth'
# p5
# ((lp6
# I1
# aS'a'
# aNI01
# I00
# tp7
# s.
with open(r"c:\pickle.txt","w") as f:
pickle.dump(src_dic,f)
loads/load反序列化
from datetime import date try:
import cPickle as pickle #python 2
except ImportError as e:
import pickle #python 3 src_dic = {"date":date.today(),"oth":([1,"a"],None,True,False),}
det_str = pickle.dumps(src_dic)
with open(r"c:\pickle.txt","r") as f:
print (pickle.load(f))
# {'date': datetime.date(2016, 10, 27), 'oth': ([1, 'a'], None, True, False)}
json和pickle模块的区别
1、json只能处理基本数据类型。pickle能处理所有Python的数据类型。
2、json用于各种语言之间的字符转换。pickle用于Python程序对象的持久化或者Python程序间对象网络传输,但不同版本的Python序列化可能还有差异。
python 模块 - 序列化 json 和 pickle的更多相关文章
- python模块(json和pickle模块)
json和pickle模块,两个都是用于序列化的模块 • json模块,用于字符串与python数据类型之间的转换 • pickle模块,用于python特有类型与python数据类型之间的转换 两个 ...
- (转)python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
阅读目录 1.1.1导入模块 1.1.2__name__ 1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代 ...
- Python 序列化模块(json,pickle,shelve)
json模块 JSON (JavaScript Object Notation):是一个轻量级的数据交换格式模块,受javascript对象文本语法启发,但不属于JavaScript的子集. 常用方法 ...
- python---基础知识回顾(四)(模块sys,os,random,hashlib,re,序列化json和pickle,xml,shutil,configparser,logging,datetime和time,其他)
前提:dir,__all__,help,__doc__,__file__ dir:可以用来查看模块中的所有特性(函数,类,变量等) >>> import copy >>& ...
- python常用模块之json、pickle模块
python常用模块之json.pickle模块 什么是序列化? 序列化就是把内存里的数据类型转换成字符,以便其能存储到硬盘或者通过网络进行传输,因为硬盘或网络传输时只接受bytes. 为什么要序列化 ...
- python中的json和pickle
author:headsen chen date::2018-04-10 09:56:54 json模块和pickle模块: 这是用于序列化的两个模块: 概念介绍:json和pickle模块是将数据 ...
- python模块之JSON
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之JSON #1.JSON #JSON表示的对象就是标准的JavaScript语言的对象 # ...
- python 序列化模块之 json 和 pickle
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,支持不同程序之间的数据转换.但是只能转换简单的类型如:(列表.字典.字符串. ...
- python中序列化json模块和pickle模块
内置模块和第三方模块 json模块和pickle 模块(序列化模块) 什么是序列化? 序列化就是将内粗这种的数据类型转成另一种格式 序列化:字典类型——>序列化——>其他格式——>存 ...
随机推荐
- 动手动脑(lesson2)
一·随机数生成问题 //信1605-3 20163683 蔡金阳 package lesson2; public class Suiji { private static final int N = ...
- 《MySQL必知必会》[07] 管理事务处理
1.管理事务处理 一个或多个数据库操作(查询/更新等)组成"事务",也就是说,事务实际上是一组按顺序执行的操作单位: 原子性:整个事务为整体执行,要么执行,要么不执行,不能出现执行 ...
- ASP.NET Core 中 HttpContext 详解与使用 | Microsoft.AspNetCore.Http 详解 (转载)
“传导体” HttpContext 要理解 HttpContext 是干嘛的,首先,看图 图一 内网访问程序 图二 反向代理访问程序 ASP.NET Core 程序中,Kestrel 是一个基于 li ...
- UOJ347 WC2018 通道 边分治、虚树
传送门 毒瘤数据结构题qwq 设三棵树分别为$T1,T2,T3$ 先将$T1$边分治,具体步骤如下: ①多叉树->二叉树,具体操作是对于每一个父亲,建立与儿子个数相同的虚点,将父亲与这些虚点穿成 ...
- Luogu2045 方格取数加强版(K取方格数) 费用流
题目传送门 题意:给出一个$N \times N$的方格,每个格子中有一个数字.你可以取$K$次数,每次取数从左上角的方格开始,每一次只能向右或向下走一格,走到右下角结束,沿路的方格中的数字将会被取出 ...
- React-引入图片的方法
方法一: import imgURL from '../../images/logo.png'; <img src={imgURL} alt="1"/> 方法二: &l ...
- WPF中的Bitmap与byte
原文:WPF中的Bitmap与byte public MainWindow() { InitializeComponent(); byte[] b = GetPictureData(@"F: ...
- IOC框架之 Unity 入门
十年河东,十年河西,莫欺少年穷 学无止境,精益求精 Unity是什么? Unity是patterns & practices团队开发的一个轻量级.可扩展的依赖注入容器,具有如下的特性: 1. ...
- 安卓自动化测试,贺晓聪之uiautomator设备和选择器~Python详解
1.设备对象 引入uiautomator,获取设备对象<所谓设备对象可理解为:Android模拟器或者真机> 语法:from uiautomator import device as d ...
- Luogu P4211 [LNOI2014]LCA
我去这道题的Luogu评级是假的吧,这都算黑题. 我们首先考虑把操作离线不强制在线的题目离线一下一般都要方便些 考虑差分,我们用\(f(x)\)表示\([1,x]\)之间的点与\(z\)的答案,那么显 ...