开源通用爬虫框架YayCrawler-框架的运行机制
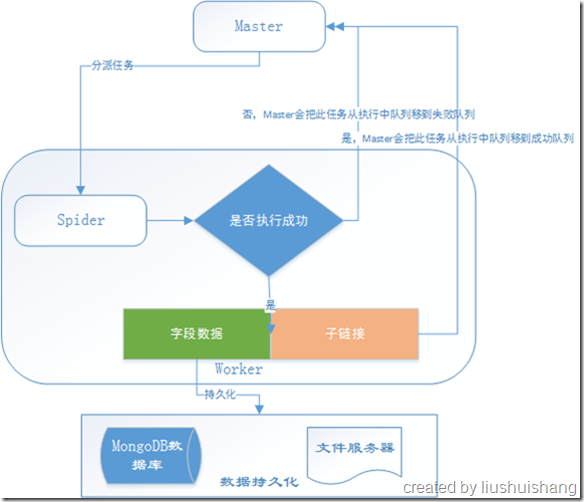
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图:
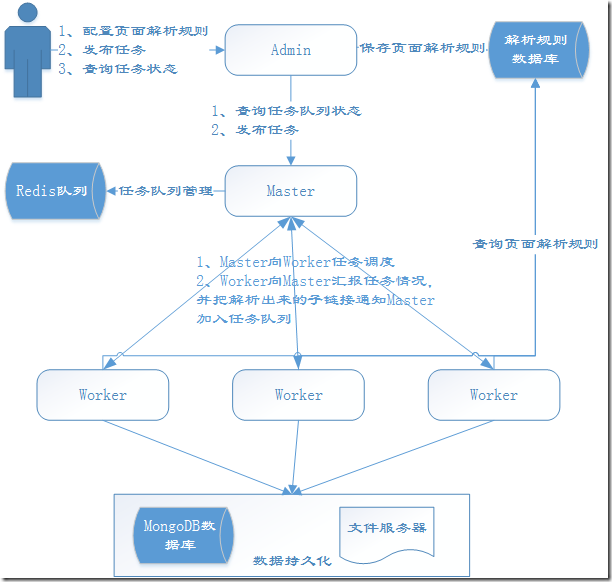
首先各个组件的启动顺序建议是Master、Worker、Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启动顺序。
一、Master端分析
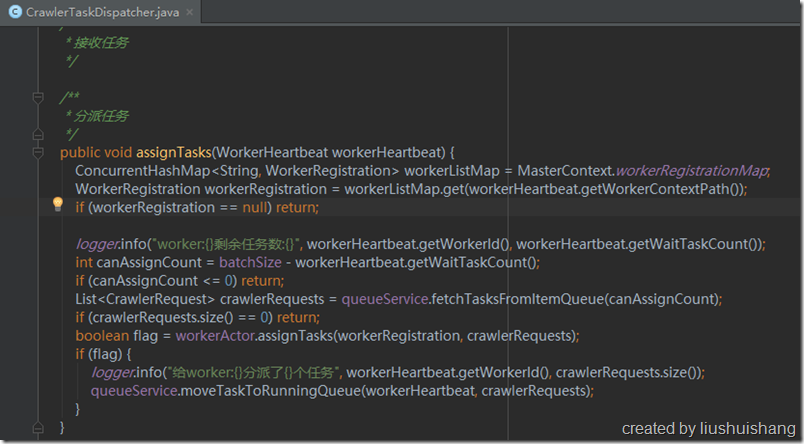
Master启动后会连接Redis查询任务队列状态,Master维持了四个状态的任务队列:待执行任务队列、执行中任务队列、成功任务队列和失败任务队列。Master内部有一个任务调度器,Master等Worker心跳包到来的时候,观察Worker是否还有任务分配的余地(每个Worker可以设置自己本地的任务队列的长度),如果Worker还能接收n个任务,任务调度器就会从待执行任务队列中取至多n个任务分配给该Worker。分配成功后,Master会把这n个任务从待执行队列移到执行中队列。
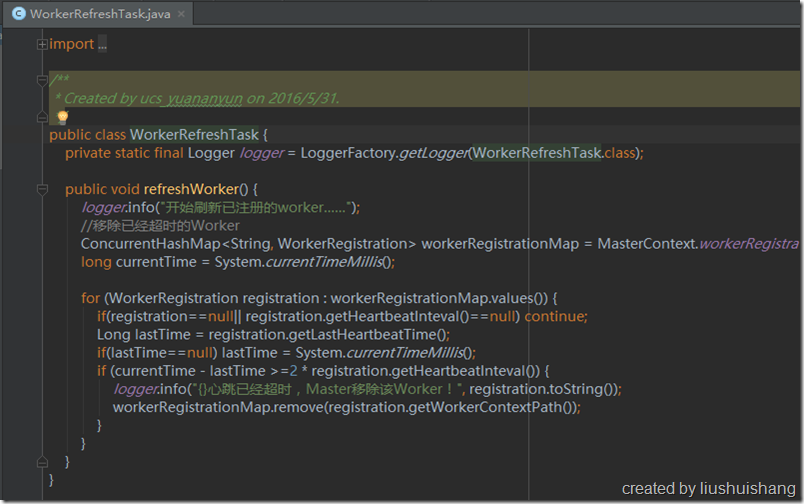
Master会定期扫描已注册的Worker,如果某个Worker的上次心跳时间距离了现在已经超过了2倍Worker自身的心跳间隔,那么Master会认为此Worker已经失联,不能再给它分配任务,因此会把它从已注册列表移除。
Master会定期扫描执行中队列,如果发现某个任务的分配时间距离现在已经超过了某个预设值,我们可以认为这个任务出现了差错,应该重新执行一遍,因此Master会重新把这个任务从执行中队列移到待执行队列,以便再次分配执行。
二、Worker端分析
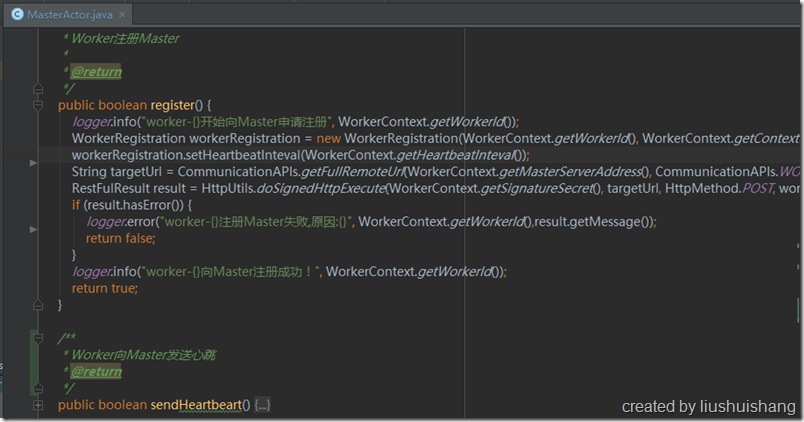
Worker的配置文件里面配置了Master的服务通信地址,Worker启动的时候就会通过这个地址向Master注册,注册的信息包括Worker的通信地址、心跳间隔、任务配额等。Worker注册成功后会定期向Master发送心跳,向Master汇报自己的状态的同时领取任务。
三、Admin端分析
Admin端主要是为用户提供一个操作的接口界面,这是一个Web工程,Admin端的配置文件里面也记录了Master的服务通信地址。用户在Admin端可以针对目标网页编写抽取规则,测试规则,直到保存到数据库。用户可以在界面上查看任务的执行情况,比如成功的任务,失败的任务,任务的结果等;用户也可以在界面上单个或批量发布普通任务/定时任务,这些任务最终会在Worker上执行,Worker在解析的时候会参考用户设置的解析规则。
四、其他
Master、Worker和Admin三者之间的通信是基于http协议的,为了安全,通信过程中都使用了token, timestamp, nonce来对消息体进行签名并验证,只有签名正确才能通信成功。
框架中的队列、持久化方式都是基于接口编程的,您可以很方便的用自己的实现来替换原有的处理。
开源通用爬虫框架YayCrawler-框架的运行机制的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler.该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行. 首先 ...
- 01_日志采集框架Flume简介及其运行机制
离线辅助系统概览: 1.概述: 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出. 任务调度等不可或缺的辅助系统,而这些辅助 ...
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一.如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同.页面的结构不 ...
- php CI框架目录结构及运行机制
CI目录结构 CI主要组成部分为,application(应用文件夹).system(系统文件夹)和index.php入口文件. 应用文件夹中主要是存放控制器.模型和视图等,系统文件夹中主 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 【转】Python爬虫(6)_scrapy框架
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html 性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
随机推荐
- Django复习之ORM
QuerySet数据类型: 1.可切片,可迭代 [obj,....] 2.惰性查询: ...
- 如何优雅地使用Sublime Text3(转)
转自http://www.jianshu.com/p/3cb5c6f2421c/ Sublime Text:一款具有代码高亮.语法提示.自动完成且反应快速的编辑器软件,不仅具有华丽的界面,还支持插件扩 ...
- mybatis基础系列(三)——动态sql
本文是Mybatis基础系列的第三篇文章,点击下面链接可以查看前面的文章: mybatis基础系列(二)--基础语法.别名.输入映射.输出映射 mybatis基础系列(一)--mybatis入门 动态 ...
- java mysql的latin1转UTF-8
public String convertCharset(String s) { if (s != null) { try { int length = s.length(); byte[] buff ...
- jenkins编译jar包 报connection连接错误
原因是因为编译启动连接了注册中心 eureka.client.service-url.defaultZone=http://localhost:8093/eureka/ eureka.client.r ...
- Ubuntu上安装paparazzi
这个值得看: https://www.bilibili.com/video/av16824692?from=search&seid=14509366447693533881
- AliOS-Things linkkitapp解读
app-example-linkkitapp是AliOS-Things提供的设备联网并且和阿里云IOT平台数据交互的一个示例程序: 1:application_start()程序在app_entry. ...
- 【Codeforces 526D】Om Nom and Necklace
Codeforces 526 D 题意:给一个字符串,求每个前缀是否能表示成\(A+B+A+B+\dots+A\)(\(k\)个\(A+B\))的形式. 思路1:求出所有前缀的哈希值,以便求每个子串的 ...
- Android学习之基础知识四-Activity活动1讲
一.活动(Activity)的基本用法: 1.手动创建活动FirstActivity(java源码): A.Android Studio在一个工作区间只允许打开一个项目,点击:File--->C ...
- 随笔一个dom节点绑定事件
以下利用jquery说明: js中,给一个dom节点绑定事件再平常不过了.这里说下,如果dom经常发生变化的话,给这个dom绑定事件的情况. 比如代码如下: li的节点,绑定了事件:点击会打出来里头的 ...