Pandas 基础(5) - 处理缺失的数据
首先, 读入一个 csv 文件:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/5_handling_missing_data_fillna_dropna_interpolate/weather_data.csv')
df输出: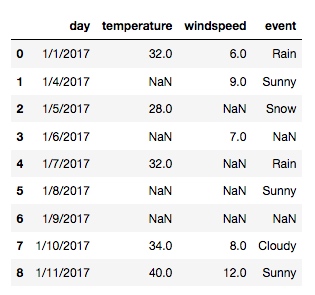
查看一下 day 列的数据类型:
type(df.day[0])
输出:
str
所以目前 day 列里数据类型是字符串.
把 day 列里的数据转成时间戳, 加上第二个参数 parse_dates=['day'] 即可:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/5_handling_missing_data_fillna_dropna_interpolate/weather_data.csv', parse_dates=['day'])
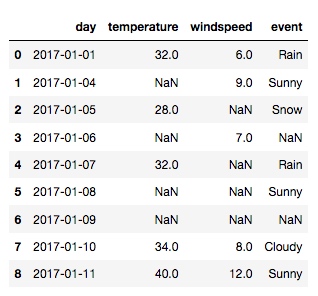
再查看一下 day 列的数据类型:
type(df.day[0])
输出:
pandas._libs.tslibs.timestamps.Timestamp
把 day 列设置为索引列:
df.set_index('day', inplace=True)
输出: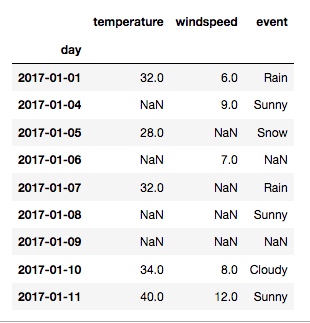
上面的输出有很多空值 NaN, 我们要把它改成数字0:
new_df = df.fillna(0)
new_df
输出: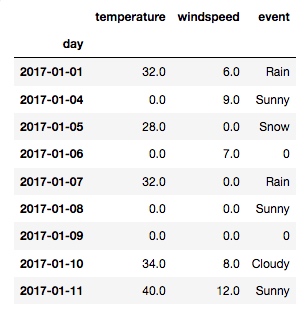
可以看到所有的 NaN 都变成 0 了. 但其实, 并不是所有的列都适合用 0 来填充, 比如 event 列里的 0 就没有实际意义. Pandas 提供了自定义每个列空值填充的方法:
new_df = df.fillna({
'temperature': 0,
'windspeed': 0,
'event': 'no event'
})
new_df
输出: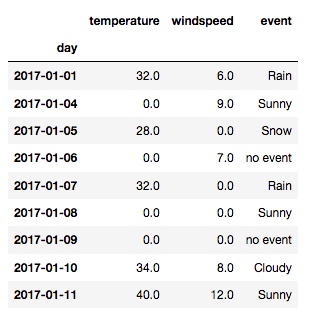
下面再介绍几个在实际应用中更有意义的空值填充方式:
fillna()函数
- 参考上一行的值填充:
new_df = df.fillna(method='ffill')
- 参考下一行的值填充:
new_df = df.fillna(method='bfill')
- 横向从右向左填充:
new_df = df.fillna(method='bfill', axis='columns')
- 横向从左向右填充:
new_df = df.fillna(method='ffill', axis='columns')
- 在使用上述几个填充的方法时, 还可以再加一个参数限定具体要填充几个格, 比如设置 limit=1, 就意味着只会向下填充一格, 后面的空格不管
new_df = df.fillna(method='ffill', limit=1)
输出如下, 可以看到 NaN 的部分就是未被填充的: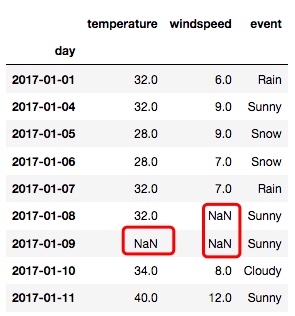
interpolate()函数
new_df = df.interpolate()
从输出中, 可以看出, 这个方法取的是空值前后的中间值:
显然, 取中间值的方式, 比简单粗暴地用前面的值填充更为合理, 但是其实还有优化的空间, 就以 temperature 列为例, 原本 1月4日的值是空的, 如果我们取中间值, 就得到了30.0度, 但是从实际意义出发, 我们会认为1月4日的温度应该与1月5日的温度更加接近, 而不是1月1日. 所以, 我们可以这样做:
new_df = df.interpolate(method='time')
输出: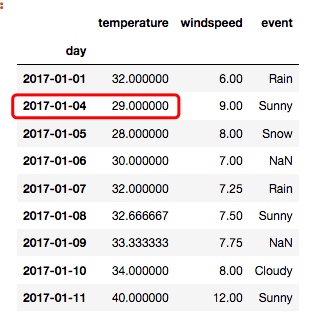
dropna() 函数
通过这个函数, 可以舍弃掉所有有空值的行:
new_df = df.dropna()
输出: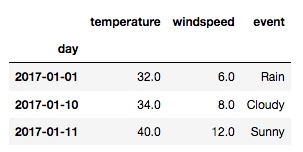
我们看到所有有空值的行全部被删除了, 但是这貌似也不是很合适, 我们只想舍弃所有列都为空值的行, 酱紫就可以了:
new_df = df.dropna(how='all')
输出: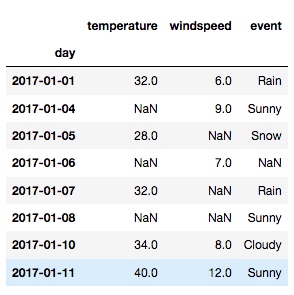
保留至少有一个列有值的行:
new_df = df.dropna(thresh=1)
输出:
保留至少有两个列有值的行:
new_df = df.dropna(thresh=2)
输出: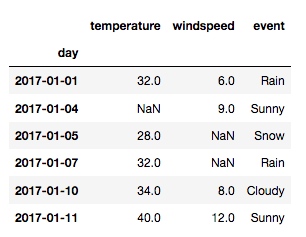
补足所缺的日期
#设置日期范围
dt = pd.date_range('2017-01-01', '2017-01-11')
#重新定义索引
idx = pd.DatetimeIndex(dt)
df = df.reindex(idx)
df
输出: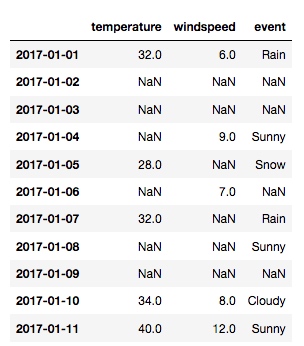
之后, 可以按照上面所讲的方法, 根据实际需要填充空值.
以上, 就是关于空值填充的一些方法, 如有问题请留言, enjoy~~~
Pandas 基础(5) - 处理缺失的数据的更多相关文章
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 数据可视化基础专题(八):Pandas基础(七) 数据清洗与预处理相关
1.数据概览 第一步当然是把缺失的数据找出来, Pandas 找缺失数据可以使用 info() 这个方法(这里选用的数据源还是前面一篇文章所使用的 Excel ,小编这里简单的随机删除掉几个数据) i ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Python Numpy,Pandas基础笔记
Numpy Numpy是python的一个库.支持维度数组与矩阵计算并提供大量的数学函数库. arr = np.array([[1.2,1.3,1.4],[1.5,1.6,1.7]])#创建ndarr ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
随机推荐
- mui 卡片视图 遮罩蒙版
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- 原生JS表格行拖动排序,添加了回调功能
function tableDnD(el, callback) { if (typeof (el) == "string") { el = document.getElementB ...
- ubuntu 16.04 安装和配置vncserver
https://www.linode.com/docs/applications/remote-desktop/install-vnc-on-ubuntu-16-04/#connect-to-vnc- ...
- 分析Hello2代码
代码如下String username = request.getParameter("username"); if (username != null && us ...
- GIS常用知识列举
GIS知识分类 我认为GIS知识,大体可分为以下三类. G——测量学.地图学.误差理论等基础——测绘方面 I——数据库.开发——IS方面 S——GIS原理——结合前面两种知识的理念 第一类,是基础,有 ...
- linux下yum安装及配置
1 2 3 4 分步阅读 公司使用的是linux搭建服务器,linux安装软件能够使用yum安装依赖包是一件非常简单而幸福的事情,所以这里简单介绍一下linux安装yum源流程和操作. 工具/原料 电 ...
- Jedis简介
实际开发中,我们需要用Redis的连接工具连接Redis然后操作Redis, 对于主流语言,Redis都提供了对应的客户端: https://redis.io/clients https://redi ...
- python练习题-day16
1.用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb name=["alex","wupeiqi","yuanhao" ...
- 使用APScheduler启动Django服务时自动运行脚本(可设置定时运行)
Django搭建的服务器一般都用作WEB网站进行访问,通常的形式是用户访问网站或点击按钮发送请求,Django检测到请求后进行相应的试图函数处理后返回页面给用户. 但是,我们有时会需要有一些后台自动运 ...
- webstorm 配置 开发微信小程序
默认情况下,webstorm是不支持wxml和wxss的文件类型,不会有语法高亮 设置高亮 除了高亮,还需要代码提示, 所幸已经有前辈整理了小程序的代码片段,只需要导入其安装包即可使用,包文件路径如下 ...