天池新人赛-天池新人实战赛o2o优惠券使用预测(一)
第一次参加天池新人赛,主要目的还是想考察下自己对机器学习上的成果,以及系统化的实现一下所学的东西。看看自己的掌握度如何,能否顺利的完成一个分析工作。为之后的学习奠定基础。
这次成绩并不好,只是把整个机器学习的流程熟悉了下。我本人总结如下:
步骤一:读懂题目含义,分析赛题的数据
步骤二:特征工程的设计,这部分非常重要,好的特征工程能大大提高模型的准确率
步骤三:训练算法。区分训练集、测试集等。
步骤四:测试模型,看效果如何。
赛题可以去天池的官网查看,里面有赛题说明,赛题数据等等
https://tianchi.aliyun.com/getStart/introduction.htm?spm=5176.11165418.333.1.3c2e613cd1CCDk&raceId=231593
以下是代码部分:
import numpy as np
import pandas as pd #导入数据
train_online = pd.read_csv('ccf_online_stage1_train.csv')
train_offline = pd.read_csv('ccf_offline_stage1_train.csv')
test = pd.read_csv('ccf_offline_stage1_test_revised.csv')
#将数据合并,以便统一对数据进行处理。都是线下数据
all_offline = pd.concat([train_offline,test])
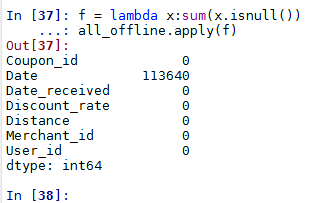
#查看每一列的异常值
f = lambda x:sum(x.isnull())
all_offline.apply(f)
#Data的空值 赋值为null,统一空值的格式
all_offline['Date'] = all_offline['Date'].fillna('null') #将online与offline的数据合并
pd.merge(all_offline,train_online,on=['Merchant_id','User_id']) #通过合并数据,发现两者并无交集,题目要求只用线下预测,故排除线上online数据,
#只用offline数据 #根据赛题的要求,把正负样本标注出来
def is_used(column):
if column['Date']!='null' and column['Coupon_id']!='null':
return 1
elif column['Date']=='null' and column['Coupon_id']!='null':
return -1
else:
return 0 all_offline['is_used'] = all_offline.apply(is_used,axis=1)
#Coupon_id 优惠券ID的具体数值意义不大,因此我们把他转换成:是否有优惠券
def has_coup(x):
if x['Coupon_id'] != 'null':
return 1
else:
return 0 all_offline['has_coup']=all_offline.apply(has_coup,axis=1)
#由于Discount_rate优惠率的特殊格式:"150:20",很难使用算法来计算使用
#根据实际情况,优惠力度是能够影响优惠券的使用频率的。因此需要对Discount_rate进行转化
#根据Discount_rate标识出折扣率
import re
regex=re.compile('^\d+:\d+$') def discount_percent(y):
if y['Discount_rate'] == 'null' and y['Date_received'] == 'null':
return 'null'
elif re.match(regex,y['Discount_rate']):
num_min,num_max=y['Discount_rate'].split(':')
return float(num_max)/float(num_min)
else:
return y['Discount_rate'] all_offline['discount_percent'] = all_offline.apply(discount_percent,axis=1)
#在进一步想,优惠力度会影响优惠券使用的概率,x:y这种满减的类型,x具体是多少,势必也会影响优惠券使用率
#讲满x元的标出x元
def discount_limit(y):
if y['Discount_rate'] == 'null' and y['Date_received'] == 'null':
return 'null'
elif re.match(regex,y['Discount_rate']):
num_min,num_max=y['Discount_rate'].split(':')
return num_min
else:
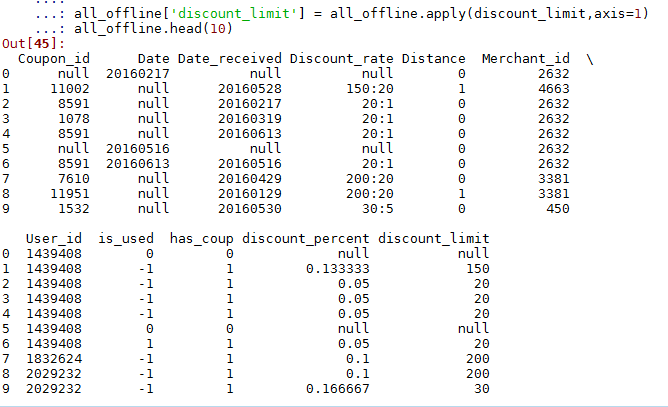
return 0 all_offline['discount_limit'] = all_offline.apply(discount_limit,axis=1)
all_offline.head(10)
#由于赛题需要的是,优惠券领取后15天的使用概率
#因此,我们在is_used的基础上,在对领券时间 Date_received 和使用时间Date,进行比较,判断是否在15天内使用
#时间比较
import datetime
#标注15天内使用优惠券的情况
def used_in_15days(z):
if z['is_used'] == 1 and z['Date'] != 'null' and z['Date_received'] != 'null':
days= (datetime.datetime.strptime(z['Date'],"%Y%m%d")-datetime.datetime.strptime(z['Date_received'],"%Y%m%d"))
if days.days < 15:
return 1
else:
return 0
else:
return 0 all_offline['used_in_15days']=all_offline.apply(used_in_15days,axis=1)
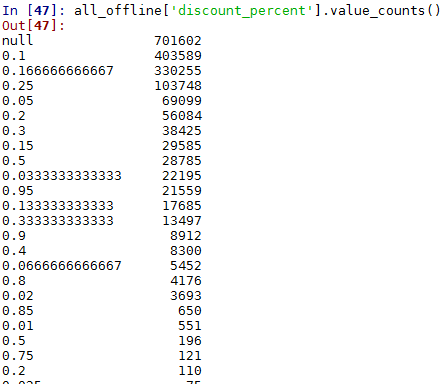
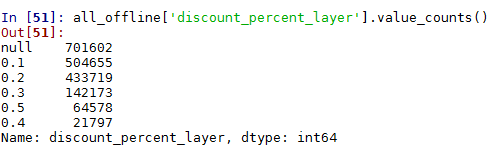
#再来观察discount_percent,discount_limit这2个特征,看数据的分布情况。
all_offline['discount_percent'].value_counts()
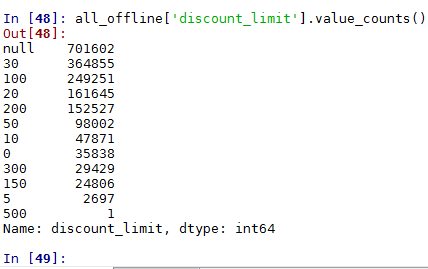
all_offline['discount_limit'].value_counts()
#将discount_percent分段
def discount_percent_layer(columns):
if columns['discount_percent']=='null':
return 'null' columns['discount_percent']=float(columns['discount_percent'])
if columns['discount_percent'] <= 0.1:
return 0.1
elif columns['discount_percent'] <= 0.2:
return 0.2
elif columns['discount_percent'] <= 0.3:
return 0.3
elif columns['discount_percent'] <= 0.4:
return 0.4
else:
return 0.5 all_offline['discount_percent_layer']=all_offline.apply(discount_percent_layer,axis=1)
all_offline['discount_percent_layer'].value_counts()
· 
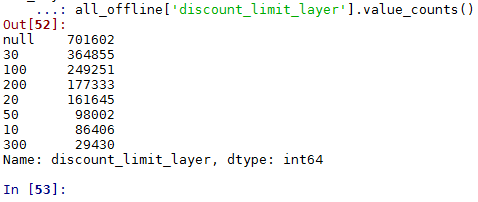
#将discount_limit分段
def discount_limit_layer(columns):
if columns =='null':
return 'null' columns=int(columns)
if columns <= 10:
return 10
elif columns <= 20:
return 20
elif columns <= 30:
return 30
elif columns <= 50:
return 50
elif columns <= 100:
return 100
elif columns <= 200:
return 200
else:
return 300 all_offline['discount_limit_layer']=all_offline['discount_limit'].apply(discount_limit_layer)
all_offline['discount_limit_layer'].value_counts()
总结:
此时 Coupon_id 被处理成 has_coup(1代表领取优惠券,0代表没有领取优惠券)
Date,Date_received 被处理成 used_in_15days。表示是否在15天内使用过优惠券
Discount_rate 被处理成 discount_percent(折扣率),discount_limit(满多少)
Merchant_id,User_id 是unicode值,不需要进行处理
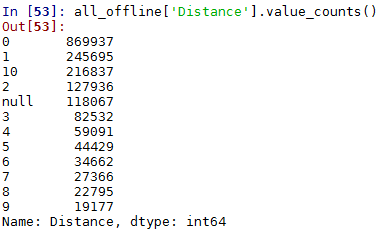
#剩下Distance,看下Distance的分布情况
all_offline['Distance'].value_counts()
#保存数据,以便后期使用起来方便
train_finall,test_finall = all_offline[:train_offline.shape[0]],all_offline[train_offline.shape[0]:]
all_offline.to_csv(r'output\all_offline.csv')
train_finall.to_csv(r'output\train_finall.csv')
test_finall.to_csv(r'output\test_finall.csv')
#one_hot处理
all_offline_new=all_offline.drop(
['Coupon_id','Date','Date_received','Discount_rate','Merchant_id',
'User_id','discount_percent','discount_limit'],axis=1)
all_offline_new=pd.get_dummies(all_offline_new)
#把测试集跟验证集分开
train01,test01=all_offline_new[:len(train_offline)],all_offline_new[len(train_offline):] #把没有领券的去掉
train02=train01[train01['has_coup']==1] #由于特征集 都是领券的人,故把 has_coup 字段删掉
train02=train02.drop(['has_coup'],axis=1)
test01=test01.drop(['has_coup'],axis=1) x_train=train02.drop(['used_in_15days'],axis=1)
y_train=pd.DataFrame({"used_in_15days":train02['used_in_15days']})
x_text=test01.drop(['used_in_15days'],axis=1)
#建模
from sklearn.linear_model import LinearRegression clf=LinearRegression()
clf.fit(x_train,y_train) #用模型进行预测
predict=clf.predict(x_text) result=pd.read_csv('ccf_offline_stage1_test_revised.csv')
result['probability']=predict result=result.drop(['Merchant_id','Discount_rate','Distance'],axis=1) #发现最终预测有负值,直接归为0
result['probability']=result['probability'].apply(lambda x: 0 if x<0 else x) result.to_csv(r'output/sample_submission.csv',index=False)
天池新人赛-天池新人实战赛o2o优惠券使用预测(一)的更多相关文章
- 数据挖掘实战 - 天池新人赛o2o优惠券使用预测
数据挖掘实战 - o2o优惠券使用预测 一.前言 大家好,家人们.今天是2021/12/14号.上次更新是2021/08/29.上篇文章中说到要开两个专题,果不其然我鸽了,这一鸽就是三个多月.今天,我 ...
- 2016天池-O2O优惠券使用预测竞赛总结
第一次参加数据预测竞赛,发现还是挺有意思的.本文中的部分内容参考第一名“诗人都藏在水底”的解决方案. 从数据划分.特征提取.模型设计.模型融合/优化,整个业务流程得到了训练.作为新手在数据划分和模型训 ...
- o2o优惠券使用预测
前沿: 这是天池的一个新人实战塞题目,原址 https://tianchi.aliyun.com/getStart/information.htm?spm=5176.100067.5678.2.e13 ...
- 《阿里云天池大赛赛题解析》——O2O优惠卷预测
赛事链接:https://tianchi.aliyun.com/competition/entrance/231593/introduction?spm=5176.12281925.0.0.7e157 ...
- 天池新闻推荐比赛1:赛题理解+baseline
天池新闻推荐比赛1:赛题理解+baseline 一.比赛信息 比赛链接: https://tianchi.aliyun.com/competition/entrance/531842/inform ...
- 52-2018 蓝桥杯省赛 B 组模拟赛(一)java
最近蒜头君喜欢上了U型数字,所谓U型数字,就是这个数字的每一位先严格单调递减,后严格单调递增.比如 212212 就是一个U型数字,但是 333333, 9898, 567567, 313133131 ...
- 2014年亚洲区域赛北京赛区现场赛A,D,H,I,K题解(hdu5112,5115,5119,5220,5122)
转载请注明出处: http://www.cnblogs.com/fraud/ ——by fraud 下午在HDU上打了一下今年北京区域赛的重现,过了5题,看来单挑只能拿拿铜牌,呜呜. ...
- 第十三届北航程序设计竞赛决赛网络同步赛 B题 校赛签到(建树 + 打标记)
题目链接 校赛签到 对每个操作之间建立关系. 比较正常的是前$3$种操作,若第$i$个操作属于前$3$种,那么就从操作$i-1$向$i$连一条有向边. 比较特殊的是第$4$种操作,若第$i$个操作属 ...
- 串门赛: NOIP2016模拟赛——By Marvolo 丢脸记
前几天liu_runda来机房颓废,顺便扔给我们一个网址,说这上面有模拟赛,让我们感兴趣的去打一打.一开始还是没打算去看一下的,但是听std说好多人都打,想了一下,还是打一打吧,打着玩,然后就丢脸了. ...
随机推荐
- LeetCode: 102_Binary Tree Level Order Traversal | 二叉树自顶向下的层次遍历 | Easy
题目:Binay Tree Level Order Traversal Given a binary tree, return the level order traversal of its nod ...
- Liferay7 BPM门户开发之11: Activiti工作流程开发的一些统一规则和实现原理(完整版)
注意:以下规则是我为了规范流程的处理过程,不是Activiti公司的官方规定. 1.流程启动需要设置启动者,在Demo程序中,“启动者变量”名统一设置为initUserId 启动时要做的: ident ...
- Go标准库之读写文件(File)
Go标准库之读写文件(File) 创建一个空文件 package main import ( "log" "os" ) func main() { file, ...
- Selenium3 + Python3自动化测试系列一——安装Python+selenium及selenium3 浏览器驱动
一.安装Python https://www.python.org/downloads/ 验证Python是否安装成功.打开Windows命令提示符(cmd),输入python,回车 注意:在安装的过 ...
- Eclipse 工程目录下的.classpath、.project文件和.settings文件作用
1..classpath 定义了你这个项目在编译时所使用的$CLASSPATH (注: 每次在更新jar的版本或者增加jar之后,请在SVN提交.classpath文件,否则工程的build path ...
- 关于JS的一些东西
1.声明Js代码域 1.在head标签中使用script声明js代码域 <head> .... <!--声明js代码域--> ...
- C# sqlhelper 整理
以下代码是参考几个不同人的写法总结写成的,肯定还有很大的优化空间,暂存该版本:有建议的欢迎提出: using System; using System.Collections.Generic; usi ...
- ARP的通信过程
在当今的以太网络通信中,在IP数据包中有两个必不可少的地址,那就是IP地址和网卡地址(即MAC地址),在数据包中,无论是IP地址还是MAC地址,都有源地址和目标地址,因为通信是双方的,所以就必须同时拥 ...
- #3 Python解释器和编辑器
前言 上文介绍了Python在不同平台的安装方法,本文将带领你了解Python解释器和编辑器的概念,并且选择出最符合自己的解释器和编辑器! 一.Python解释器 其实上文介绍的安装Python,实质 ...
- MySQL中MyISAM和InnoDB两种主流存储引擎的特点
一.数据库引擎(Engines)的概念 MySQ5.6L的架构图: MySQL的存储引擎全称为(Pluggable Storage Engines)插件式存储引擎.MySQL的所有逻辑概念,包括SQL ...