论文笔记【二】Making Sense of Word Embeddings
摘要
1.作者提出了一种新的简单有效的方法,用于学习词义嵌入word sense embedding
2.传统的两种方法:(1)直接从语料库中学习词义;(2)依赖词汇资源的语义库
研究方法的创新点:通过聚类相关词的自我网络ego-networks,从而在现有的词嵌入中引出语义库。
3.集成的WSD机制允许在学习到的语义向量的上下文中标记单词,从而产生下游应用
4.这种新式方法能够与现有的无监督WSD系统相媲美
介绍
在NLP应用中,密集向量形式的术语表示是非常有用的。首先,它们能计算语义相关的单词;另外,它们可以用来表示其他语言单元,如短语和短文,降低传统向量空间表示的固有稀疏性。
大多数词向量模型都把一个单词的各种含义混合成一个简单的单一向量,这是大多数词向量的一个局限性,也就是稀疏和密集表示的问题。为了解决这个问题,(Huang et al., 2012; Tian et al., 2014; Neelakantan et al., 2014; Nieto Pi ˜na and Johansson, 2015; Bartunov et al., 2016)等人,先后提出了几种用于学习多原型词向量的结构。而已有的迹象显示,多原型词嵌入能够改善文本处理程序的性能,例如词性标注和语义关系识别。
注:大多数词嵌入方法都是假定用每个词能够用单个向量代表,但是无法解决一词多义和同音异议的问题。多原型向量空间模型(Reisinger and Mooney 2010)是将一个单词的上下文分成不同的群(groups),然后为每个群生成不同的原型向量。遵循这个想法, (Huang et al. 2012) 提出了基于神经语言模型(Bengio et al. 2003)的多原型词嵌入。
本文的贡献是一种学习词义向量的新方法。与先前的方法相比,该方法依赖于现有的单原型词嵌入,通过自我网络聚类,将词向量转换为语义向量。所谓的ego network,它的节点是由唯一的一个中心节点(ego),以及这个节点的邻居(alters)组成的,它的边只包括了ego和alter之间,以及alter与alter之间的边,其中,图里面的每个alter和它自身的邻居又可以构成一个ego network,而所有节点的ego network合并起来,就可以组成真实的social network了。
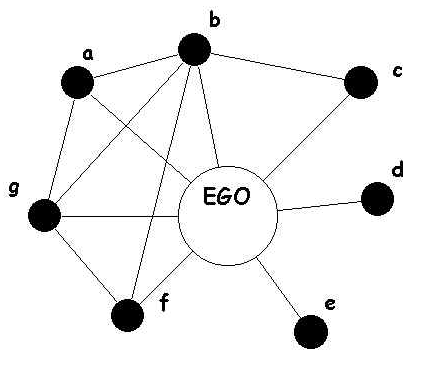
此外,本文方法中配有词义消歧WSD机制,因此上下文中的词可以可以映射到这些语义表示上。
本文所阐述的方法的一个优点是可以使用现有的词嵌入和/或现有的语义库来构建词义嵌入。这种方法与最先进的无监督WSD系统相当。
学习词义嵌入
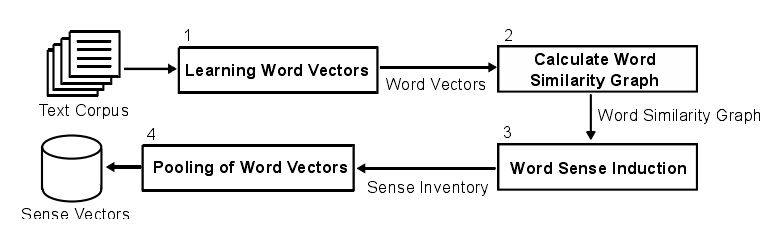
四个阶段:1.学习词向量 2.基于向量相似性构建最近邻居图 3.利用自我网络聚类归纳词义 4.关于语义归纳的词向量聚合
1.学习词向量
使用word2vec学习词向量,所训练的COBW词嵌入有100或300维,上下文窗口大小为3,最小词频为5。在训练时,修改了word2vec的标准实现,以便能够保存WSD方法之一所需的上下文向量。
2.计算词相似图
对于每个单词,检索其200个最近邻居,而只有少数几个词具有更强烈的语义相关词。词相似度图是基于前一步中学习的词嵌入或者使用JoBim Text框架所提供的语义相似性来计算的。
(1) word2vec
使用w2v提取情况下,词的最近邻居是各个词向量的最高余弦相似性的项。出于可伸缩性的原因,使用快向量乘法,使用1000个向量的块来执行相似度计算。
(2) JoBim Text
这是一种无监督的方法,每个词都表示为一组基于稀疏依赖性的特征,这种特征是使用Malt解析器提取的。使用LMI得分对特征进行归一化,接着对默认值进行进一步修剪。两个词的相似性等于共同特征的数量。
3.语义归纳
语义由单词簇表示,为了归纳语义,首先我们构建单词t的自我网络G,然后对该网络进行图形聚类。引用相同含义的词语倾向于紧密相连,而指向不同意义的词语的联系较少。
在算法1中呈现的语义归纳每次迭代便处理词相似图T中的一个字t。首先,检索自我网络G的节点V,这些是图T中t的N个最相似词。t本身不是自我网络的一部分。其次,将G中的节点连接到来自T的n个最相似的词。最后,自我网络与Chinese Whispers (CW)算法聚类。(注:CW是用来分割加权的无向图节点,CW算法的目标就是查找传播相同信息到相邻节点的节点组。)
由于该方法是无参数的,故不对词义的数量进行假设。
语义归纳算法有三个元参数:目标自我词 t 的自我网络大小N;自我网络连接(n)是允许邻居v在自我网络中具有的最大连接数;集群k的最小尺寸。参数n调整语义库的粒度。
词义聚类中的每个单词的权重等于该词与其模糊词 t 之间的相似性得分。
4.词向量池化
这个过程要计算归纳语义库中每种语义的语义嵌入。假设一个词的词义是表示这种词义的词的组合。语义向量定义为表示集群项的词向量的函数。设W是训练语料库中所有单词的集合,让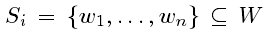 成为上一步中获得的语义聚类。考虑一个函数
成为上一步中获得的语义聚类。考虑一个函数 将单词映射到它们的向量和函数
将单词映射到它们的向量和函数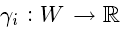
将集群词映射到集群Si中的权重。这里尝试了两种计算感测向量的方法:
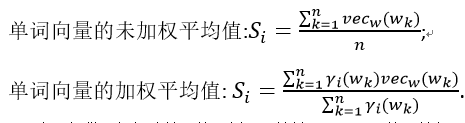
论文笔记【二】Making Sense of Word Embeddings的更多相关文章
- 【论文笔记】Zero-shot Recognition via semantic embeddings and knowledege graphs
Zero-shot Recognition via semantic embeddings and knowledege graphs 2018-03-31 15:38:39 [Abstrac ...
- 论文笔记【四】Semi-supervised Word Sense Disambiguation with Neural Models
基于神经模型的半监督词义消歧 Dayu Yuan Julian Richardson Ryan Doherty Colin Evans Eric Altendorf Google, Mount ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
- 《基于WEB的独立学院补考重修管理系统研究》论文笔记(二十)
<基于WEB的独立学院补考重修管理系统研究>论文笔记(1) 一.基本信息 标题:基于WEB的独立学院补考重修管理系统研究 时间:2016 来源:南通大学杏林学院 关键词:WEB:补考重修管 ...
- 吴恩达《深度学习》-第五门课 序列模型(Sequence Models)-第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings)-课程笔记
第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings) 2.1 词汇表征(Word Representation) 词汇表示,目 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- [C5W2] Sequence Models - Natural Language Processing and Word Embeddings
第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings) 词汇表征(Word Representation) 上周我们学习了 RN ...
- deeplearning.ai 序列模型 Week 2 NLP & Word Embeddings
1. Word representation One-hot representation的缺点:把每个单词独立对待,导致对相关词的泛化能力不强.比如训练出“I want a glass of ora ...
随机推荐
- Ai challenger 2017 image caption小结
参加了今年的ai challenger 的image caption比赛,最终很幸运的获得了第二名.这里小结一下. Pytorch 越来越火了.. 前五名有三个pytorch, 两个tensorflo ...
- Vivado Design Suite用户指南之约束的使用第一部分(介绍部分)
首先来看目录部分: 首先是介绍部分:这部分讲述的是Migrating From UCF Constraints to XDC Constraints(从UCF约束迁移到XDC约束)和About XDC ...
- linux signal
1) SIGHUP 本信号在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联. 登录Linux时,系统会分配给 ...
- [LeetCode] Majority Element 求大多数
Given an array of size n, find the majority element. The majority element is the element that appear ...
- [LeetCode] Longest Substring Without Repeating Characters 最长无重复字符的子串
Given a string, find the length of the longest substring without repeating characters. Example 1: In ...
- webpack应用案例之美团app
记录自己的创建步骤,且对自己的错误进行纠正分析.
- 常用基础Linux操作命令总结与hadoop基础操作命令
cd命令:切换目录 (1)切换到目录 /usr/local cd /usr/local (2)去到目前的上层目录 cd .. (3)回到自己的主文件夹 cd ~ ls命令:查看文件与目录 (4)查看目 ...
- 剑指offer——python【第54题】字符流中第一个不重复的字符
题目描述 请实现一个函数用来找出字符流中第一个只出现一次的字符.例如,当从字符流中只读出前两个字符"go"时,第一个只出现一次的字符是"g".当从该字符流中读出 ...
- html的空格和换行显示
一.HTML 代码中的所有连续的空格或空行(换行)都会被显示为一个空格,不管是内容还是标签之间. 二.当我们想让它们在同一行连续显示时,就让所有的代码之间没有空格,也不要换行. 三.当我们想要显示连续 ...
- python学习之旅(十六)
Python基础知识(15):模块 1.可以把模块想象成导入Python以增强其功能的扩展 2.任何程序都可以作为模块导入 3.导入模块并不意味着在导入的时候执行某些操作,它们主要用于定义变量.函数和 ...